Data Annotation for ML: Guide to Label AI Training Data

In the current digital age and the new industrial revolution of artificial intelligence, data has become one of the most valuable assets. Machine Learning (ML) plays a major role in exploiting this information to derive meaningful insights and informed decisions.
At the heart of this technology, an essential step makes it possible to transform raw data into usable resources for algorithms: data annotations (also know as Data Labeling). This task, often unknown to the general public but fundamental to AI, is to label and organize data in a way that it can be effectively used by Machine Learning models. The AI industry is rapidly expanding, driven by the increasing demand for annotated data to train advanced models. Data annotation work is foundational to this growth, as it enables the development and deployment of effective AI systems.
Data Labeling involves several steps necessary to ensure accurate, high-quality data labeling, such as transcribing, tagging or processing objects within various types of unstructured data (text, image, audio, video), to enable algorithms to interpret the labeled data and train themselves to solve analyses or interpret information without human intervention. The data annotation industry, as a sector, provides both opportunities and faces challenges as it grows to meet the needs of AI development. In this article, we explain in detail how it all works.
-hand-innv.png)
Data annotation is a process that requires both precision and a thorough understanding of the data context. Whether it’s image recognition, natural language processing or predictive analysis. Indeed, the quality of data annotation directly affects the performance of the models. High quality training data is essential for building effective AI and ML models.
💡 In other words, the relevance and precision of data annotation largely determine the ability of algorithms to learn and generalize from data! In this article, we explain how the data preparation process for Machine Learning models works!

Data annotation: what is it?
Data annotation refers to the process of assigning labels to raw data. Labeling data is a core part of the annotation process across all data types, enabling machine learning models to learn from examples. These attributes or labels can vary according to the type of data and the specific application of Machine Learning. Data labeling involves the transcription, marking or processing of objects within various data types (text, image, audio, video) to enable algorithms to interpret the labeled data and train themselves to solve analyses without human intervention. Labeled data plays an important role in training machine learning models, and a variety of tools and platforms are used to label or annotate data in different formats.
Data can be structured or unstructured. Structured data historically required less annotation because it was already organized and easier for machines to process. However, the shift toward unstructured data, such as free-form text, images, and audio, has increased the need for data annotation to enable effective machine learning.
For example, in an image database, labels can indicate the objects present in each image, such as “cat“, “dog“ or “tree“. For textual data, a data annotation can identify parts of speech, named entities (such as names of people or places), or sentiments expressed in a text. Named entity recognition (NER) is a key NLP task that involves identifying and categorizing entities like names, dates, and organizations within unstructured text, making it fundamental for information extraction and other NLP workflows. We can also create navigational relationships between entities and solve problems of property correspondence, using specific data annotations.
The task of data annotation can be performed manually by human annotators or automatically using algorithmic techniques (with more or less convincing results). In automated systems, human supervision is often required to check and correct a data annotation to ensure its reliability. Often, the best method of data preparation is to use hybrid approaches: for example, this may involve equipping annotators (or data labelers) with advanced tools to enable them to make precise annotations, and to have a functional and critical eye on the reviewed data. A data annotation platform provides a dedicated environment for efficient data labeling, offering features such as customizable workflows, collaboration tools, and scalability.
Importance of Data Annotation
Data annotation is a cornerstone of successful artificial intelligence and machine learning initiatives. At its core, data annotation transforms raw data into annotated data, providing the context and structure that enable ML models to recognize patterns, learn from examples, and make accurate predictions. Without this crucial step, even the most advanced machine learning algorithms would struggle to interpret unstructured information, leading to unreliable results and missed opportunities.
High-quality annotated data is what allows artificial intelligence systems to move beyond simple data processing and truly understand the world—whether it’s identifying objects in images, extracting meaning from text, or detecting trends in large datasets. By labeling and categorizing data, data annotation gives meaning to otherwise ambiguous information, ensuring that ML models can generalize from training data to real-world scenarios. In short, the importance of data annotation lies in its ability to bridge the gap between raw data and actionable intelligence, making it an essential process for building robust, high-performing ML models.
What are the different types of data annotation?
There are several data annotation types, each adapted to different data formats and the specific needs of machine learning applications. The main data annotation types include image annotation, text annotation, audio annotation, and video annotation. The choice of annotation method depends on the data type being processed, as each data type—such as text, audio, image, or video—requires specialized annotation techniques. Here’s a detailed exploration of the main types of data annotations, covering images, text, and other common formats.
High quality datasets, created through careful annotation, are essential for effective model training.
Image annotations
Image annotations play a key role in machine learning, especially for computer vision tasks. Box annotation, including bounding box annotation, is commonly used to annotate objects in both 2D images and 3D data, enabling precise identification and classification of entities. Below are the main activities in image annotation:
Classification annotation
This type of annotation consists in assigning a unique category to each image. For example, in a fruit data set, each image can be labeled as ”apple”, ”banana” or ”orange”. This type of labeling allows machine learning algorithms to understand and classify images according to defined categories. This method is used for image classification tasks where the model must predict the class of a given image.
Object detection annotation
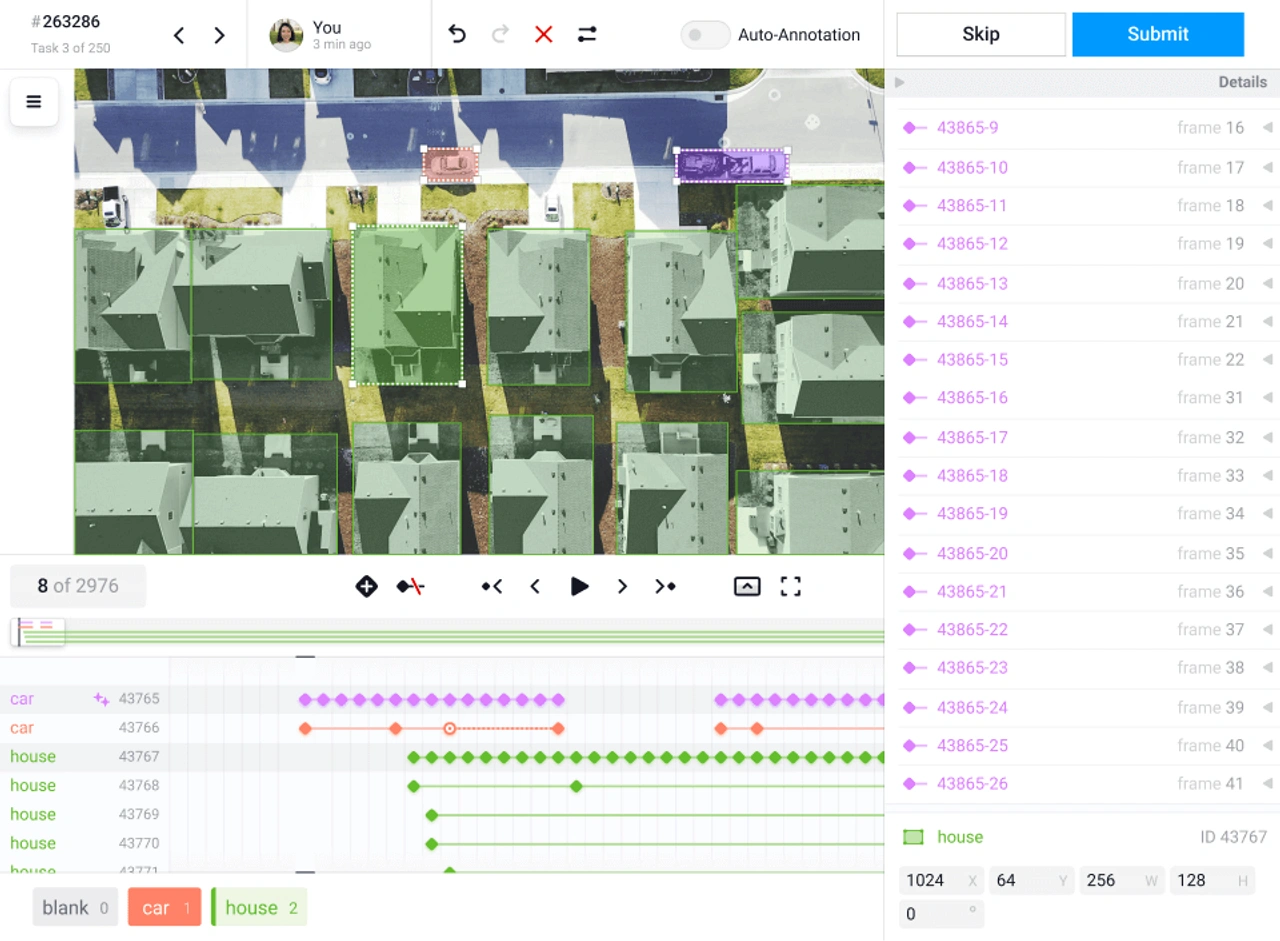
Here, bounding box annotation is the standard technique for object detection, where bounding boxes are drawn around objects of interest in an image or 3D data, such as lidar data. Each box is labeled with the class of the object it contains. This method is widely used in autonomous systems, including autonomous vehicles and robotics, to identify and track objects, recognize activities, and navigate environments safely. For example, in a street image, annotators can identify and frame cars, pedestrians, and traffic lights. This type of annotation is essential for object detection.

Semantic segmentation annotation
In the method of semantic segmentation, each pixel in the image is labeled with a class, allowing for a detailed understanding of the image. For example, a landscape image can be annotated to differentiate the road, trees, sky, and other elements. This is particularly useful for applications that require detailed image analysis.

Instance segmentation annotation
Similar to semantic segmentation, but each instance of an object is labeled individually. For example, in an image that contains multiple dogs, each dog will be annotated separately. This technique is used for tasks where distinction between individual instances is required, such as recognizing multiple objects.
Annotation of keypoints
Specific points on objects are annotated for tasks such as pose detection or facial recognition. For example, to detect human poses, key points can be placed on joints such as elbows, knees, and shoulders. This method is important for applications that require the understanding of facial expressions or movements.

Text annotations
Text annotations are essential for natural language processing applications (NLP). Intent annotation is a specialized form of text annotation used to categorize the underlying purpose of user messages, helping to understand user intent in applications like chatbots. Annotated keywords and phrases are also used to improve search relevance in search engines. LLM annotation is crucial for preparing data to train and fine-tune large language models, which rely on high-quality annotated text data for optimal training and performance. Here are the main types:
Text classification annotation
Each document or text segment is tagged with a predefined category. Intent annotation is a specialized form of text classification that categorizes the underlying user intent in messages, which is essential for training chatbots and conversational AI systems to accurately recognize and respond to user intent. For example, e-mails can be classified as “spam“ or “non-spam“. This type of labeling enables Machine Learning algorithms to understand and classify text documents according to the defined categories. This method is commonly used for document classification tasks, such as spam filtering or news article categorization.
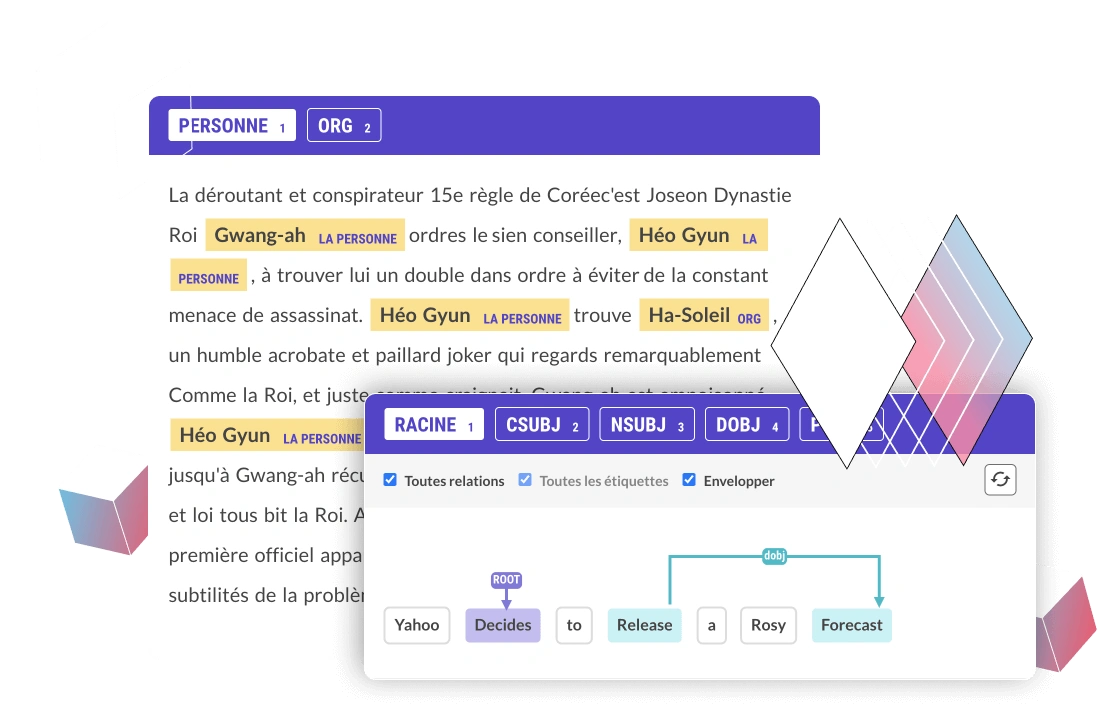
Named entity annotation (NER)
This technique involves identifying and labeling specific entities in text, such as the names of people, things or places, dates or organizations. This process is known as named entity recognition (NER), a fundamental component of NLP workflows. For example, in the sentence “Apple announced a new product in Cupertino“, “Apple“ and “Cupertino“ would be annotated as named entities. This method is required for applications that need to extract specific information.
Sentiment annotation
Text is annotated to indicate the sentiment expressed, as positive, negative or neutral. For example, a customer review can be annotated to reflect the general feeling of satisfaction or dissatisfaction. This technique is widely used for sentiment analysis in social networks and online reviews.
Annotation of parts of speech (POS)
Each word or token in a sentence is labeled with its grammatical category, such as noun, verb, adjective and so on. For example, in the sentence"The cat sleeps","The" would be annotated as a determiner,"cat" as a noun, and"sleeps" as a verb. This annotation is fundamental to the syntactic and grammatical understanding of texts.
Annotation of semantic relations (semantic annotation)
This method involves annotating relationships between different entities in the text. For example, in the sentence"Google has acquired YouTube", an acquisition relationship would be annotated between"Google" and"YouTube". This technique is used for complex tasks such as relation extraction and knowledge graph construction.
Other types of annotations
In addition to images and text, other data formats require specific annotations:
Audio annotation tasks include speech transcription, event detection, and identifying aggressive speech indicators for security and emergency response applications. Speech data is annotated to improve voice recognition, understand speaker nuances, and enhance the accuracy of speech-enabled applications like chatbots and virtual assistants. Annotating social media posts is important for content moderation and for improving AI capabilities on social media platforms. Accurately annotating medical data, such as medical images and records, is crucial for developing effective machine learning models in healthcare.
Annotating audio data
Audio files can be annotated to identify specific segments, transcripts, sound types, or speakers. Audio annotation includes tasks such as speech transcription, event detection, and identifying aggressive speech indicators in recordings. For example, in a conversation recording, each speech segment can be annotated with the identity of the speaker and transcribed into text. Speech data is essential for training audio annotation models that power applications such as speech recognition and the analysis of feelings in conversations.

Video data annotation
Videos can be annotated frame by frame or by segments to indicate actions, objects, or events. Object tracking is a crucial video annotation task, involving the analysis of moving objects across video frames. For example, in surveillance video, a person’s every movement can be annotated to identify suspicious behavior. This annotation is used by surveillance systems and computer vision applications.
3D data annotation
3D data, such as point clouds or 3D models, can be annotated to identify objects, structures, or areas of interest. Box annotation and bounding box annotation are commonly used to annotate objects in 3D point clouds, such as those generated by lidar data. Annotators annotate objects in 3D data for applications in autonomous systems like self-driving cars and robotics. For example, in a 3D scan of a room, objects such as furniture can be annotated for augmented reality or robotics applications. This method is used in areas that require precise spatial understanding.
💡 These various types of annotations allow you to create rich and informative data sets, essential for training and evaluating machine learning models in a variety of applications and domains.
What are the different methods of annotating data?
There are several data annotation methods, adapted to the specific needs of machine learning projects and the types of data to be annotated. Data annotation tools are essential for efficient annotation processes, enabling accurate and scalable labeling for AI model training.
When using manual annotation, data labellers play a crucial role by performing various types of data annotation work, such as image, text, and audio labeling, depending on the complexity and requirements of the project.
In industry practices, companies like Scale AI (or Innovatiana) are recognized as major providers of scalable annotation services, supporting large-scale AI training datasets and specialized annotation needs.
Manual annotation
Manual annotation is done by human annotators who review each piece of data and add appropriate labels. Data labellers perform data annotation work, which requires attention to detail and domain expertise. This method offers great precision and makes it possible to understand the nuances and complex contexts of data, which is crucial for highly detailed and specific annotations.
Human annotators can adapt to varied tasks and changing annotation criteria, offering significant flexibility. However, this process is often perceived as expensive and time-consuming, especially for large data sets. Additionally, annotations may vary based on annotators’ interpretations, requiring quality checking processes to ensure consistency and accuracy.
💡 In reality, your perception of manual annotation processes is probably negative, as you have in the past worked with untrained staff, working on platforms of microtasking or crowdsourcing. Just the opposite of what we offer with Innovatiana: by entrusting us with the development of your datasets, you are working with professional and experienced Data Labelers / AI Trainers!
On another topic… we think it’s important to remind that human annotators often work on dedicated interfaces (like CVAT or Label Studio, for example), where each page represents a set of data to be annotated, allowing structured and methodical management of the annotation process. See below some annotation techniques:
Automated annotation
Automated annotation uses advanced data processing algorithms and machine learning models to annotate data without direct human intervention. This method is particularly fast, allowing large amounts of data to be processed in a short period of time. Automatic annotation models produce consistent annotations, reducing variability between data.
However, the accuracy of this method depends on the quality of the annotation models, which inevitably make mistakes. As a result, human supervision is always required to check and correct the annotations, which may limit the overall effectiveness of this method if it is not accompanied by supervision by qualified personnel.
Semi-automated annotation
The semi-automated method combines automated annotation with human verification and correction. The algorithms perform a first pass of pre-annotation, then humans correct and refine the results. This approach offers a good balance between speed and precision, as it allows data to be processed quickly while maintaining good annotation quality through human intervention.
It is also less expensive than fully manual annotation, since humans only intervene to correct errors. However, this method can be complex to implement, requiring an infrastructure to integrate automated and manual steps. Moreover, the final quality always depends on the initial performance of the annotation algorithms.
These different data annotation methods offer varied approaches to processing data depending on the resources available, the size of the data set, and the specific requirements of the project. Choosing the appropriate method will depend on accuracy requirements, time and budget constraints, and the complexity of the data to be annotated.

Data Annotation Services
Data annotation services play a vital role in the development of cutting-edge AI and machine learning solutions. These services provide organizations with access to teams of skilled data annotators who specialize in labeling and categorizing data across a wide range of domains. Whether your project requires image annotation for computer vision, audio annotation for speech recognition, or text annotation for natural language processing, professional data annotation services ensure that your annotated data meets the highest standards of quality and accuracy.
By leveraging specialized data annotation services, companies can accelerate their AI initiatives, reduce operational costs, and focus on core development tasks. These services often utilize advanced annotation tools and workflows tailored to specific use cases, such as entity recognition in legal documents, object detection in autonomous vehicles, or sentiment analysis on social media platforms. Outsourcing to experienced data annotators not only guarantees quality data for training ML models but also provides the flexibility to scale annotation efforts as project needs evolve. Ultimately, data annotation services are a key enabler for organizations seeking to build reliable, high-performance AI systems powered by expertly labeled data.
Annotation Tools
Annotation tools are essential components in the data annotation workflow, providing the software infrastructure needed to efficiently label and categorize data for machine learning model training. These tools are designed to handle a variety of data types, including image annotation for computer vision tasks, audio annotation for speech and sound recognition, and text annotation for natural language processing applications.
Modern annotation tools, such as Labelbox, SuperAnnotate, and Hugging Face, offer a range of features to streamline the annotation process. These include intuitive interfaces for drawing bounding boxes or segmenting objects, collaborative environments for team-based projects, and automation capabilities to accelerate repetitive tasks. Many annotation tools also support integration with popular ML frameworks like TensorFlow and PyTorch, making it easier to move seamlessly from data labeling to model training.
Choosing the right annotation tools is crucial for managing diverse data types and ensuring that your ML model is trained on high-quality, accurately labeled data. Whether you’re working on computer vision, audio analysis, or text classification, leveraging the right annotation platform can significantly enhance the efficiency and effectiveness of your annotation project.
Annotation Project: Planning and Management
Successfully executing an annotation project requires careful planning and effective management to ensure that the resulting annotated data is suitable for ML model training. The process begins with clearly defining the project’s goals and identifying the specific data types and annotation requirements. Selecting the appropriate annotation tools is essential, as these will shape the workflow and impact the quality of the final dataset.
Assembling a skilled team of annotators and providing them with detailed guidelines helps maintain consistency and accuracy throughout the annotation process. Project managers should establish robust quality assurance protocols, monitor progress regularly, and address any challenges or exceptions that arise. Open communication between all stakeholders—including data scientists, annotators, and project leads—ensures that everyone is aligned and that the annotation project stays on track.
By following a structured approach to planning and managing annotation projects, organizations can produce high-quality annotated data that meets the rigorous standards required for effective model training and deployment in real-world ML applications.
What role do humans play in Machine Learning / Deep Learning and data annotation process?
Humans play a central role in data annotation, a crucial step for the development of effective Machine Learning models. Human annotations are critical for creating high-quality data sets because human annotators have skills to understand and interpret the contextual nuances and subtleties of data that machines cannot easily discern. Human feedback is also essential for refining AI models, especially in reinforcement learning and large language model (LLM) training, where human evaluators help improve model responses and alignment.
For example, in the annotation of images for object detection, humans can identify and label objects accurately, even in difficult visibility conditions or with partially obstructed objects. Similarly, for textual data, humans can interpret the meaning and tone of sentences, identify named entities and complex relationships, and discern the feelings expressed. High quality annotations and well-prepared labeled datasets are vital for training effective AI models, ensuring that the data used to train models is both accurate and reliable.
High quality annotations are necessary to train models and improve AI model performance, making human expertise indispensable in the annotation process.
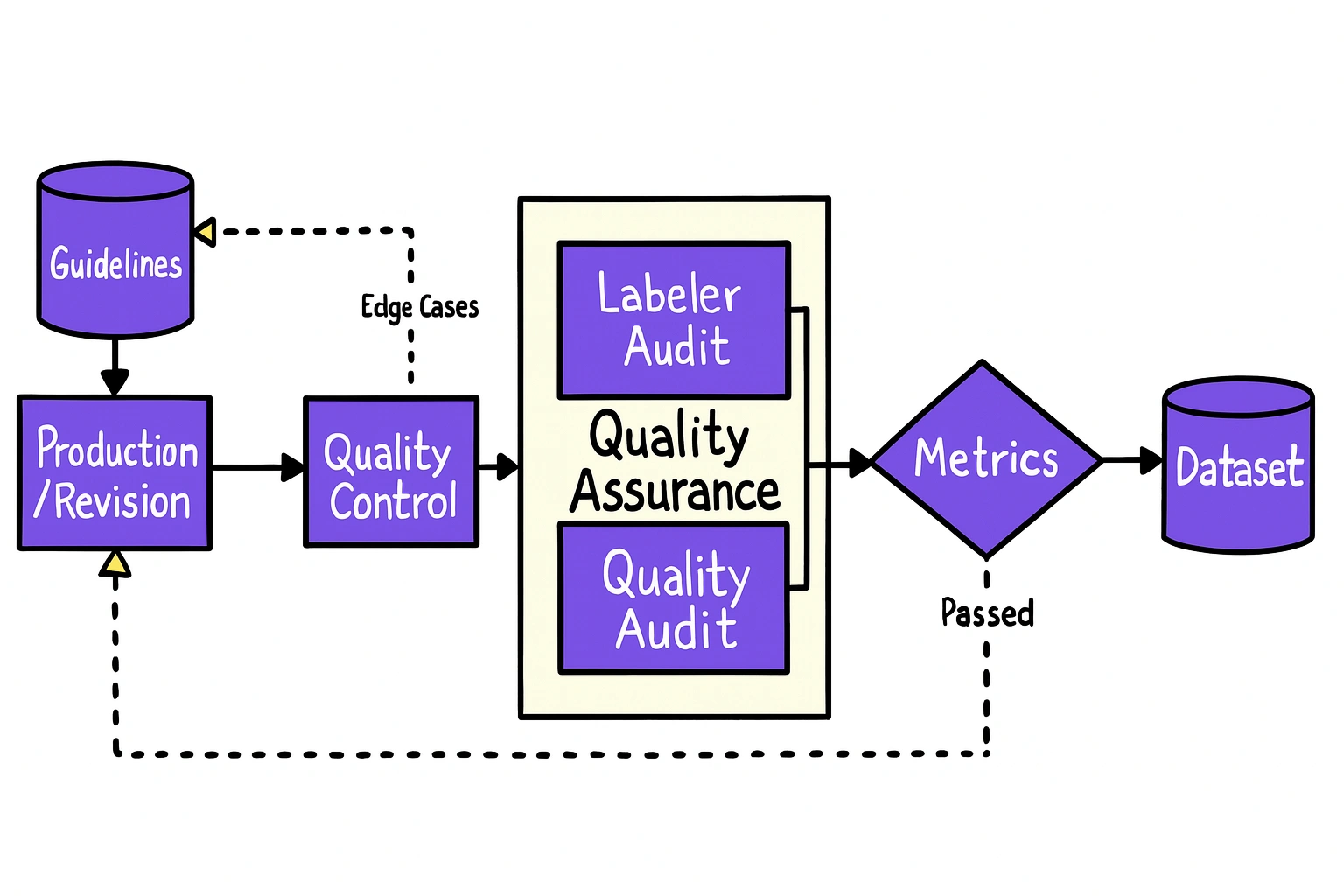
Quality management
Humans also play an important role in managing the quality of data annotations. Taking care of specific activities like quality management and supporting automated annotation processes is essential. Quality management processes are designed to produce high quality annotations and labeled datasets, which are critical for effective AI model training. Quality control processes, such as peer review, annotation audits, and mechanisms for Feedback, often involve experienced human annotators who can assess and improve the consistency and accuracy of annotations (and therefore the final quality of your datasets). Human feedback is also crucial in improving annotation quality, as it helps refine and align the results through direct evaluation and reinforcement.
For example, crowdsourcing, where numerous annotators can participate, human experts can be tasked with verifying a sample of the annotations for inconsistencies and systematic errors, and providing guidelines for improving overall quality. However, we believe it is much more efficient when done by Domain AI Trainers and Expert Data Labelers!
Model design and optimization
Beyond data annotation, humans play a key role in designing, training, and optimizing machine learning models. Annotated data is essential to train models, including advanced ai models and large language models, as it enables these systems to learn from high-quality, well-labeled examples for tasks such as recognition, analysis, and natural language processing. Machine learning engineers and researchers use their expertise to choose the appropriate algorithms, adjust hyperparameters, and select the most relevant data characteristics.
Interpreting model results, understanding errors and biases, and adjusting models to improve their performance require significant human intervention. For example, after the initial training of a model, experts can analyze incorrect predictions to identify sources of bias or variance, and make changes to the training data or model architecture to get better results.
Ethics and responsibility
Finally, humans have a responsibility to ensure that machine learning systems are used ethically and responsibly. This includes considering potential biases in training data, transparency in how models work, and assessing the impact of deployed systems on users and society in general.
Ethical decisions and regulations around the use of artificial intelligence (AI) and machine learning require a deep understanding of the social, cultural, and legal implications, a task that is the responsibility of humans. At a time when regulations around AI are evolving, it seems essential to us to take into account the challenges of data annotation and to implement best practices, such as those recommended by the recent NIST paper with regard to the labeling and pre-processing of data (source: NIST AI-600-1, “Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile”).
How to choose the right tools for data annotation?
The choice of tools for data annotation is critical to ensure the efficiency and quality of annotations, which in turn influence the performance of machine learning models. Here are some criteria and key steps for selecting the annotation tools that best fit your needs:
Understanding project needs
Before choosing a tool, it is essential to fully understand the specific needs of your machine learning project. This means identifying what type of data you're working with, whether it's images, text, text, video, audio, or 3D data, because each type of data may require specialized tools.
In addition, it is key to determine what types of annotations are needed, such as classification, object detection, segmentation, or even textual annotations such as named entity recognition (NER). The volume of data to be annotated should also be evaluated, as it can influence the choice of the tool in terms of scalability and automation.
Features and capabilities
The features of annotation tools vary widely, and it's important to choose a tool that meets your specific needs. An intuitive user interface and a good user experience increase productivity and reduce annotation errors that Data Labelers (annotators) could make.
Look for AI-assisted tools that offer quality control features, such as peer review and annotation audits. If your project involves multiple annotators, choose a tool that facilitates collaboration and user management.
Some tools include automatic or semi-automatic annotation features, which can speed up the process. Finally, the ability to customize label types and annotation processes is essential to adapt to the specific needs of your project.
Integration and compatibility
Make sure the annotation tool can be easily integrated into your existing workflow, using AI to improve the quality of annotated data. Verify that the tool supports the data formats you use, such as JPEG or PNG for images, and TXT or CSV for text.
It should also allow you to export annotations in formats compatible with your data analysis tools and Machine Learning applications. The availability of APIs and connectors to integrate the tool with other systems and pipelines of data is an important criterion for a smooth integration.
Cost and scalability
Consider the cost of the tool based on your budget and the needs of your project. Compare tool pricing models, whether per user, per data volume, or based on a monthly or annual subscription, and assess whether they fit into your budget.
Also, make sure that the tool can evolve with the growth of your project and manage growing volumes of data without compromising performance. Scalability is critical to avoid limitations as your annotation needs increase.
💡 Did you know that? Innovatiana is an independent player: we collaborate with most publishers of data annotation solutions on the market. We can provide you with information on their pricing models, and help you select the most economical solution that best suits your needs. Learn more...
Support and documentation
Good technical support and comprehensive documentation can greatly facilitate the adoption and use of the AI-assisted tool. Verify that the tool offers comprehensive and clear documentation, covering all features and providing user guides.
Evaluate the quality of technical support, looking at the availability of support, whether via live chat, email, or phone, and the responsiveness of customer service. Effective technical support can resolve issues quickly and minimize interruptions in your annotation process.
Test and evaluation
Before making a final choice, it is recommended to test several tools. Use trial versions or free demos to assess the functionalities and usability of each tool. Gather feedback from potential users, such as annotators and project managers, to identify the strengths and weaknesses of each tool.
Conducting small-scale pilot projects allows you to observe how the tool behaves in real conditions and to assess its compatibility with your requirements. This allows you to make an informed decision and to choose the tool that best suits your needs.
💡 Do you want to know more about the data annotation platforms available on the market? Check out our article! You're a Data Labeling Solution vendor and want to partner with Innovatiana? Contact us!
Conclusion
Data annotation is a fundamental and necessary step in the process of developing machine learning models. It makes it possible to transform raw data into intelligible and usable information, guiding algorithms towards more accurate predictions and optimal performances.
Various types of annotations, whether for images, text, videos, or other forms of data, meet the specific needs of various projects, each with its own methods and tools.
However, despite significant advances, the field of data annotation still faces several challenges. The quality of annotations is sometimes compromised by the variability of human interpretations or by the limitations of automated tools.
The cost and time required to obtain accurate annotations can be prohibitive, and integrating annotation tools into workflows Complexes remain an obstacle for many teams.
However, in the rapidly changing AI landscape, startups are constantly striving to gain a competitive advantage. Whether they're developing cutting-edge AI algorithms, creating innovative products, or optimizing existing processes, data is at the heart of their operations. However, raw data is often like a puzzle in which pieces are missing — valuable but incomplete. That's where data annotation comes in, providing the context and structure that turns raw data into actionable information.
The future evolution of data annotation promises innovations, in terms of tools or techniques to accelerate data preparation processes. Developments in artificial intelligence (AI) and machine learning could automate more annotation tasks, increasing speed and accuracy while reducing costs.
We can also imagine that new collaborative techniques and approaches (different from crowdsourcing, as in "more sophisticated") could improve the quality and efficiency of annotations. At Innovatiana, we are convinced that one constant will remain: human review and approval. Whatever the advances in the technologies used for the development of AI, the use of specialized personnel who master the tools and techniques for preparing data, will be more necessary than ever. AI Trainers and Data Labelers do important and necessary work, which many now consider to be painstaking or unimportant. On the contrary, we believe that this is an indispensable job that, in the long run, will contribute to the mass adoption of AI development techniques by businesses!



