Optical Character Recognition (OCR) in AI: an underestimated technique?

By transforming visual elements into textual data, OCR opens up new perspectives in the field of visual data analysis and data annotation tasks.
What is OCR?
Optical Character Recognition (OCR) is a technology that allows the conversion of physical documents containing text into editable electronic files. You start by scanning a document using a scanner or a camera. Then, the built-in algorithms analyze the image to recognize the printed characters.
Once characters are identified, OCR converts them into editable text, usually in a file format such as Word or PDF. This technology is widely used for converting paper documents into electronic files. The objective is to facilitate their storage by integrating them into a database, in order to allow searches or editions to be carried out.
What is the importance of OCR?
OCR is very important in its various uses, including:
Digitization and preservation of documents
As mentioned above, OCR makes it possible to convert paper documents into electronic formats, thus facilitating their long-term storage and preservation. This helps preserve important and historical records that could otherwise deteriorate over time.
Accessibility
OCR makes the content of printed materials accessible to people who are visually impaired or blind. In particular, it allows the conversion of text into formats that can be read by speech synthesis software or Braille displays.
Content research and analysis
Once text is converted to electronic format, it becomes easier to search, sort, and analyze it. This makes it easy to find specific information in large sets of documents. This can be very useful in areas such as academic, legal, medical, or commercial research.
-hand-innv.png)
What makes OCR so important (though sometimes underrated) in the AI era?
In the age of AI, OCR is becoming even more important due to the technological advancements that come with it, including:
Integration into automated workflows
Integrating OCR into AI-powered systems automates tasks such as classifying documents, extracting text or other information, and performing data processing. This can speed up business processes, reduce human error, and free up time for more strategic tasks.
AI model training
Unstructured data analysis
A lot of valuable information is found in unstructured documents such as reports, contracts, forms,... OCR makes it possible to make this data accessible for analysis by AI algorithms. This opens up new possibilities for data-based decision making and innovation.
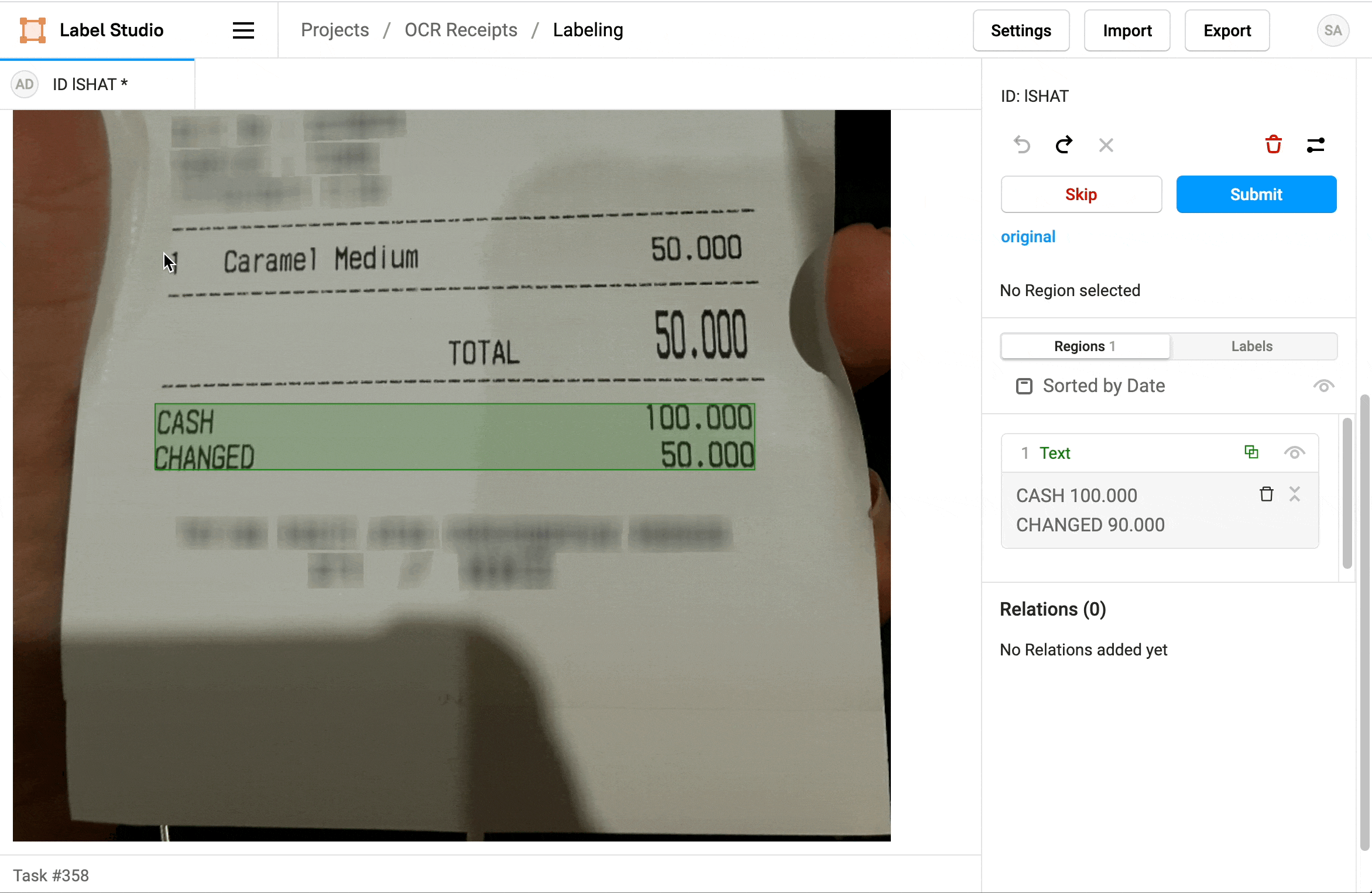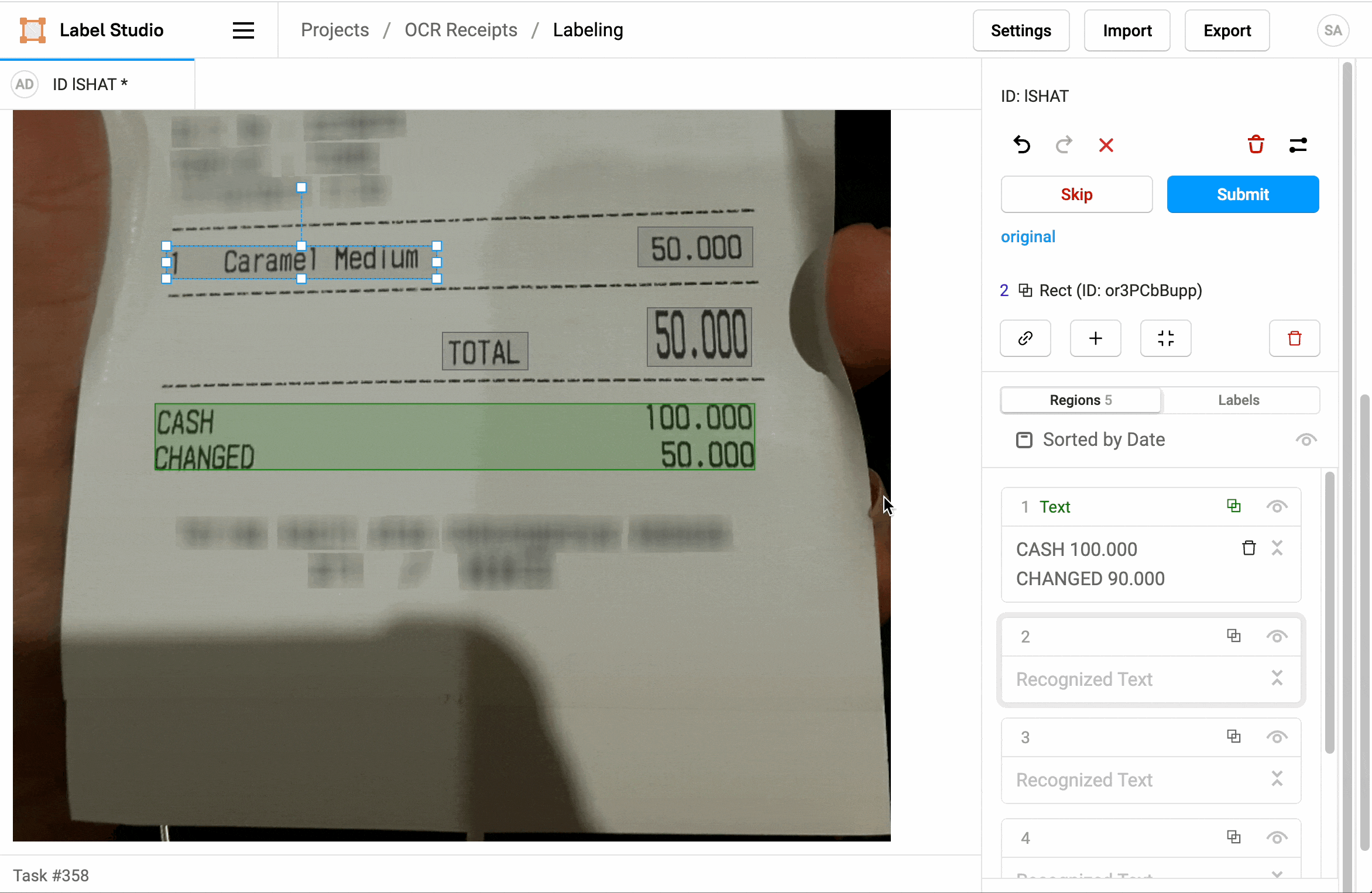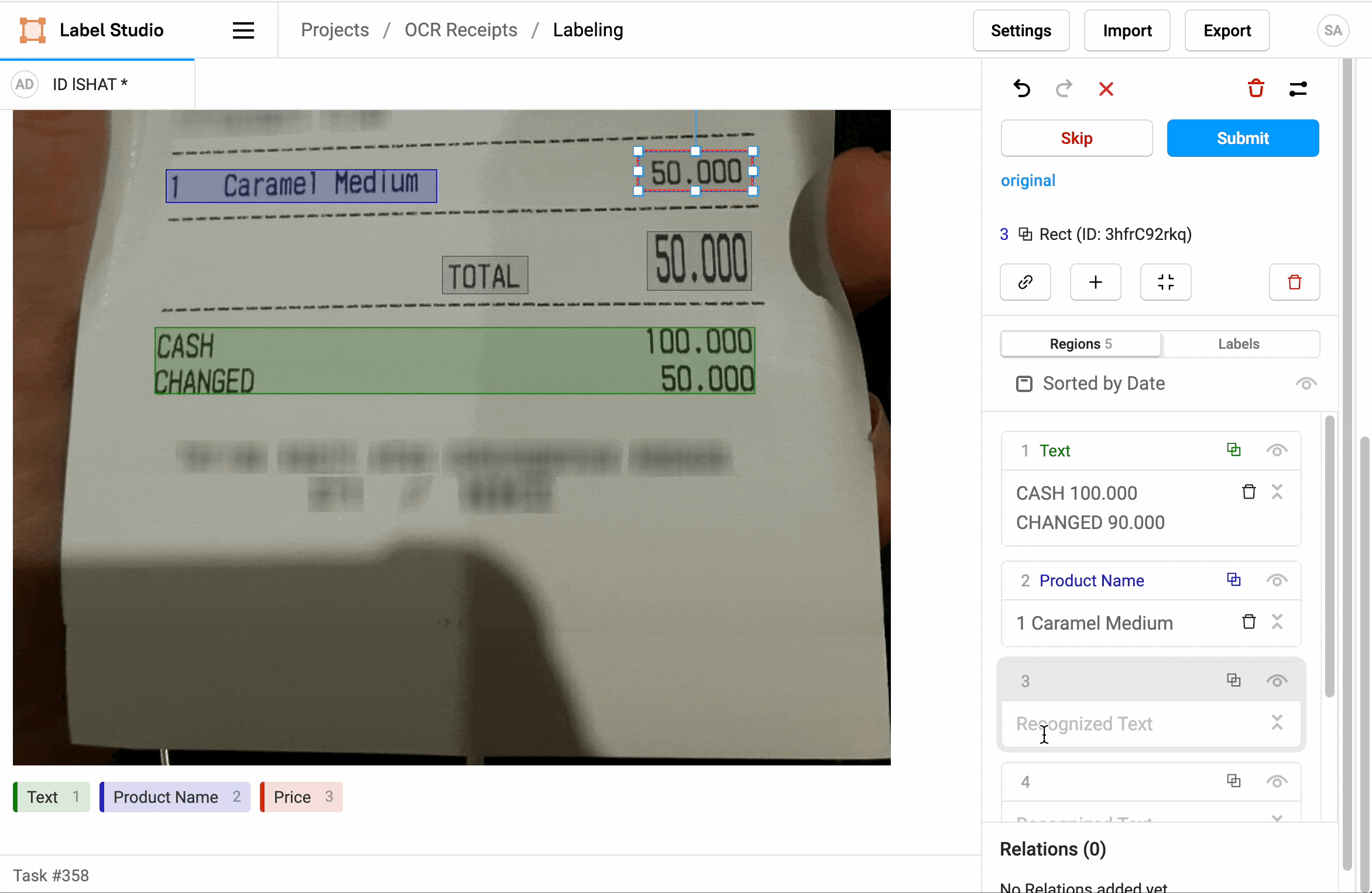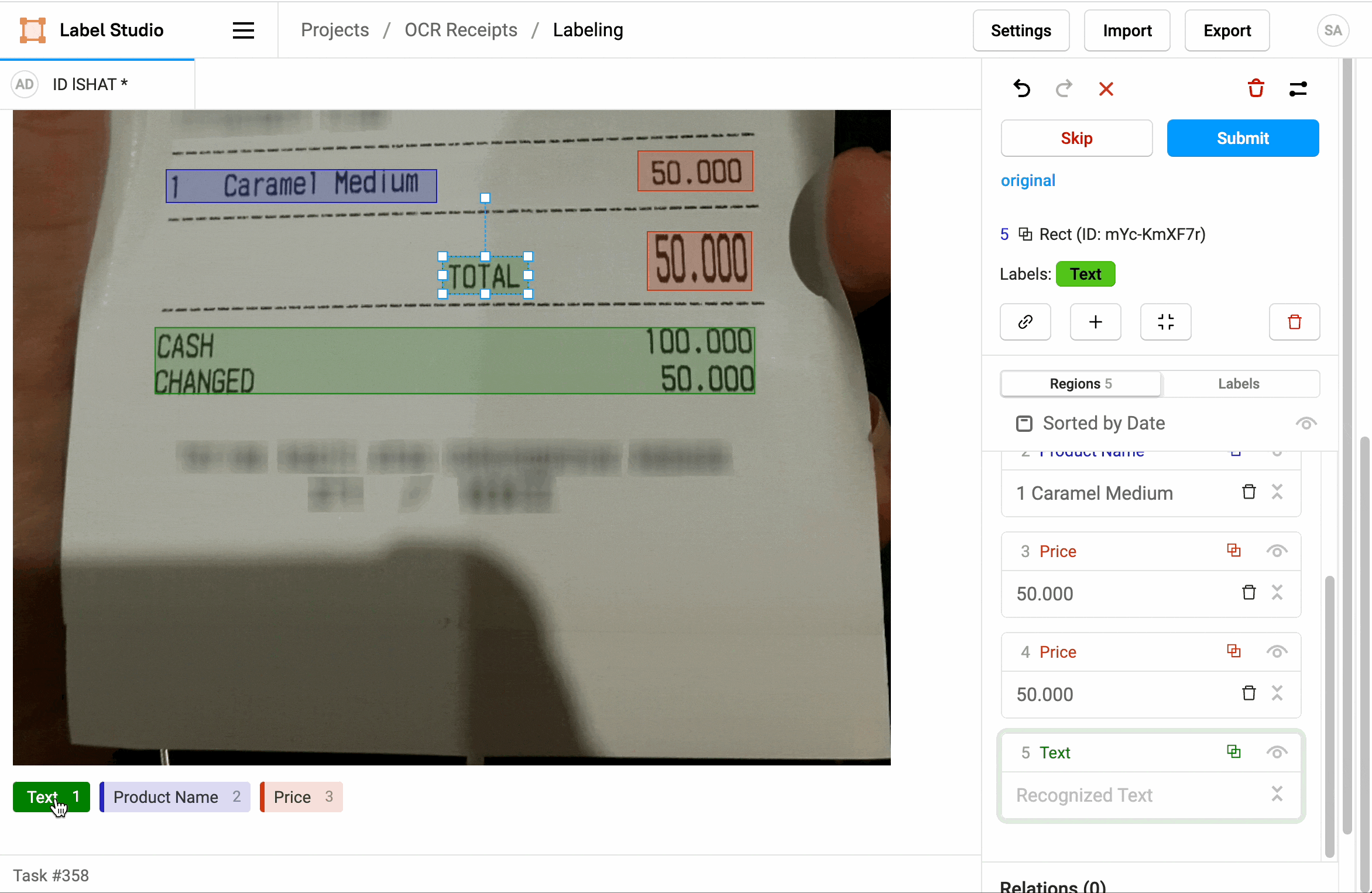
How does OCR shape data annotation tasks?
For many use cases, OCR (Optical Character Recognition) is actively involved in how data annotation tasks are shaped. A few illustrations below:
Data preprocessing
Increase in data
OCR can be used to increase data sets by converting non-text documents into extracted text. This increases the variety and quantity of data available for training AI models. At the same time, this can improve the performance of these models.
Validating and correcting annotations
When human annotators are working on annotation tasks, OCR can be used to validate or correct the annotations produced. For example, if an annotator has incorrectly annotated some of the text in an image, OCR can be used to check if the extracted text matches the annotation. This can help ensure the quality of annotated data.
Improving efficiency
By using OCR to extract text from images, annotation tasks can be made more efficient. Instead of asking annotators to manually enter the text to be annotated, they can focus on the specific annotation task. It's a great way to speed up the overall data processing process.
Adaptation to specific needs
OCR can be adapted to meet the specific needs of annotation tasks. For example, in the case of documents containing particular languages or fonts, custom OCR templates can be developed to improve the accuracy of text extraction. This is especially important in data annotation projects that are sensitive to data quality (i.e., the vast majority of projects!).
How did the first OCR systems pave the way for today's technology?
The first OCR systems laid the foundations for the development of today's technology. They overcame numerous technical challenges and introduced fundamental concepts that continue to be used today.
Rule-based character recognition
Early OCR systems often used rule-based approaches to recognize characters. These approaches included defining specific rules for recognizing character shapes based on characteristics such as the size, shape, and arrangement of traits.
Although these methods were limited in terms of accuracy and the ability to handle a variety of fonts, they laid the groundwork for further developments in the field.
Statistical models
Later, OCR systems started using statistical models to improve the accuracy of character recognition. These models were trained on large amounts of data to learn the characteristics of characters and words in different contexts.
This approach has significantly improved the accuracy of optical character recognition, especially in environments where fonts and writing styles may vary.
Use of neural networks
Recent advances in the field of deep learning have led to the adoption of neural networks for character recognition. These neural networks have shown remarkable performances in text recognition. This is in particular the case of convolutional neural networks (CNN) and recurrent neural networks (RNN).
These models significantly improved OCR accuracy and made it possible to process a wide variety of fonts and writing styles. This is done by using deep architectures and advanced training techniques on large amounts of data.
Adaptation to specific data
Modern OCR systems often incorporate mechanisms for adapting to specific data to improve recognition accuracy. This may include training OCR models on data that is specific to a particular domain or language. This also includes using continuous adaptation techniques to adjust models based on new data observed in production scenarios.
OCR: beyond the digitization of documents, what other applications is it revolutionizing?
Beyond the simple digitization of documents, OCR brings significant innovations to many other applications.
Machine translation
OCR is often used in combination with machine translation systems to translate printed materials into various languages. By first converting text into electronic format using OCR, machine translation systems can then translate the text into the desired language.
Information extraction
OCR can be used to extract specific information from documents, such as invoices, forms, or receipts or receipts. For example, in accounting, OCR can be used to automatically extract amounts, dates, and other relevant information from scanned invoices. This can speed up data processing processes considerably.
Recognizing text in images and videos
OCR can also be used to extract text from images or videos. This is useful in cases where it may be necessary to search for specific text in video recordings. Or even in the automatic recognition of license plates based on surveillance camera images.
What new frontiers could OCR cross in the coming years?
In the coming years, OCR could cross new frontiers thanks to the rapid evolution of technology, and in particular artificial intelligence. At the time of writing, AI development techniques are being renewed every 2 weeks, or almost! Integration with other fields of artificial intelligence and computer science may also have a role to play.
Advanced recognition of handwritten documents
Advances in image processing and machine learning techniques could allow for more accurate recognition of handwritten documents. This is true even in difficult conditions such as varied writing styles, damaged documents or languages with complex characters.
Multimodal recognition
Integrating OCR with other sensory modalities could allow for more robust and contextually richer multimodal recognition. This could include object recognition in images, speech recognition, and natural language understanding. This would open up new possibilities in areas such as augmented reality, autonomous cars, and smart user interfaces.
OCR based on deep learning
The use of deep neural network architectures and deep learning techniques could significantly improve OCR accuracy. Especially in difficult scenarios such as recognizing documents with varied fonts, non-Latin languages, and complex scripts.
Real-time OCR
Advances in image processing technologies and hardware architectures could allow real-time OCR to be deployed on mobile devices and embedded systems. This would open up new possibilities in applications such as augmented reality (VR), real-time translation, and visual assistance for people who are visually impaired or blind.
Adaptive and self-learning OCR
OCR could become more adaptive and self-learning. This is done by using continuous learning techniques to automatically adapt to new types of documents, languages, and writing styles. This could allow for better generalization and greater robustness of OCR in varied environments.
Protection of privacy and data security
With the increase in the use of OCR to handle sensitive documents, there is likely to be an increasing focus on developing techniques to protect privacy and data security. This is to ensure that confidential information, such as medical, financial, or legal information, is not compromised during the recognition process.
Conclusion
OCR (Optical Character Recognition), or Optical Character Recognition, is a technology that transforms printed documents into editable text. It opens the way to numerous practical applications. By analyzing document images, OCR identifies and converts characters into digital text, making it easier to search, translate, and automate processes.
Although it can face various technical challenges, such as recognition accuracy and language variability, OCR continues to evolve thanks to advances in artificial intelligence and image processing. Thus, OCR promises to make printed information more accessible, manipulable, and usable than ever before.



