Reconocimiento óptico de caracteres (OCR) en IA: ¿una técnica subestimada?

Al transformar los elementos visuales en datos textuales, el OCR abre nuevas perspectivas en el campo del análisis visual de datos y las tareas de anotación de datos.
¿Qué es el OCR?
El reconocimiento óptico de caracteres (OCR) es una tecnología que permite la conversión de documentos físicos que contienen texto en archivos electrónicos editables. Empieza escaneando un documento con un escáner o una cámara. Luego, los algoritmos integrados analizan la imagen para reconocer los caracteres impresos.
Una vez identificados los caracteres, el OCR los convierte en texto editable, normalmente en un formato de archivo como Word o PDF. Esta tecnología se usa ampliamente para convertir documentos en papel en archivos electrónicos. El objetivo es facilitar su almacenamiento integrándolos en una base de datos, a fin de permitir realizar búsquedas o ediciones.
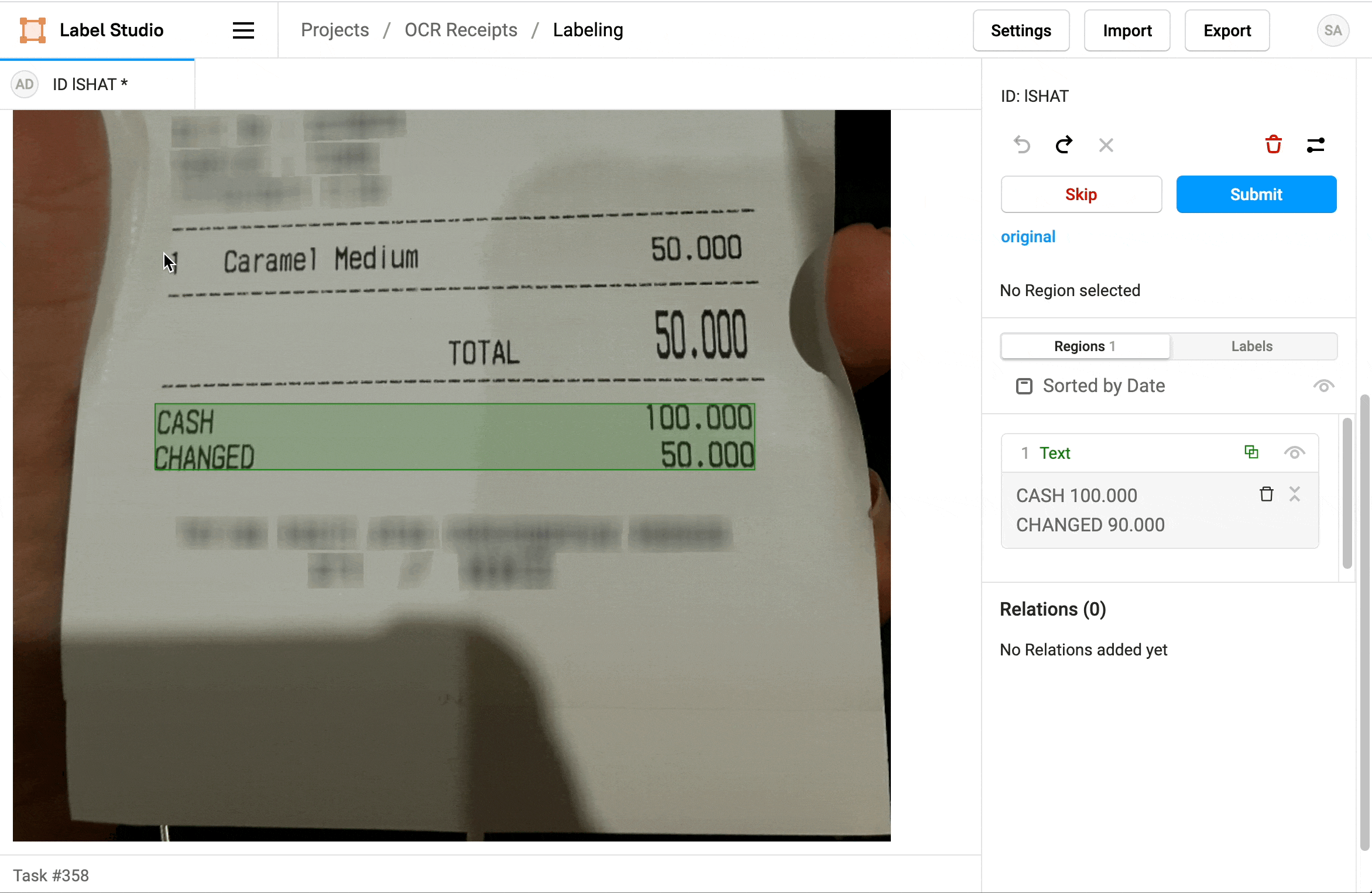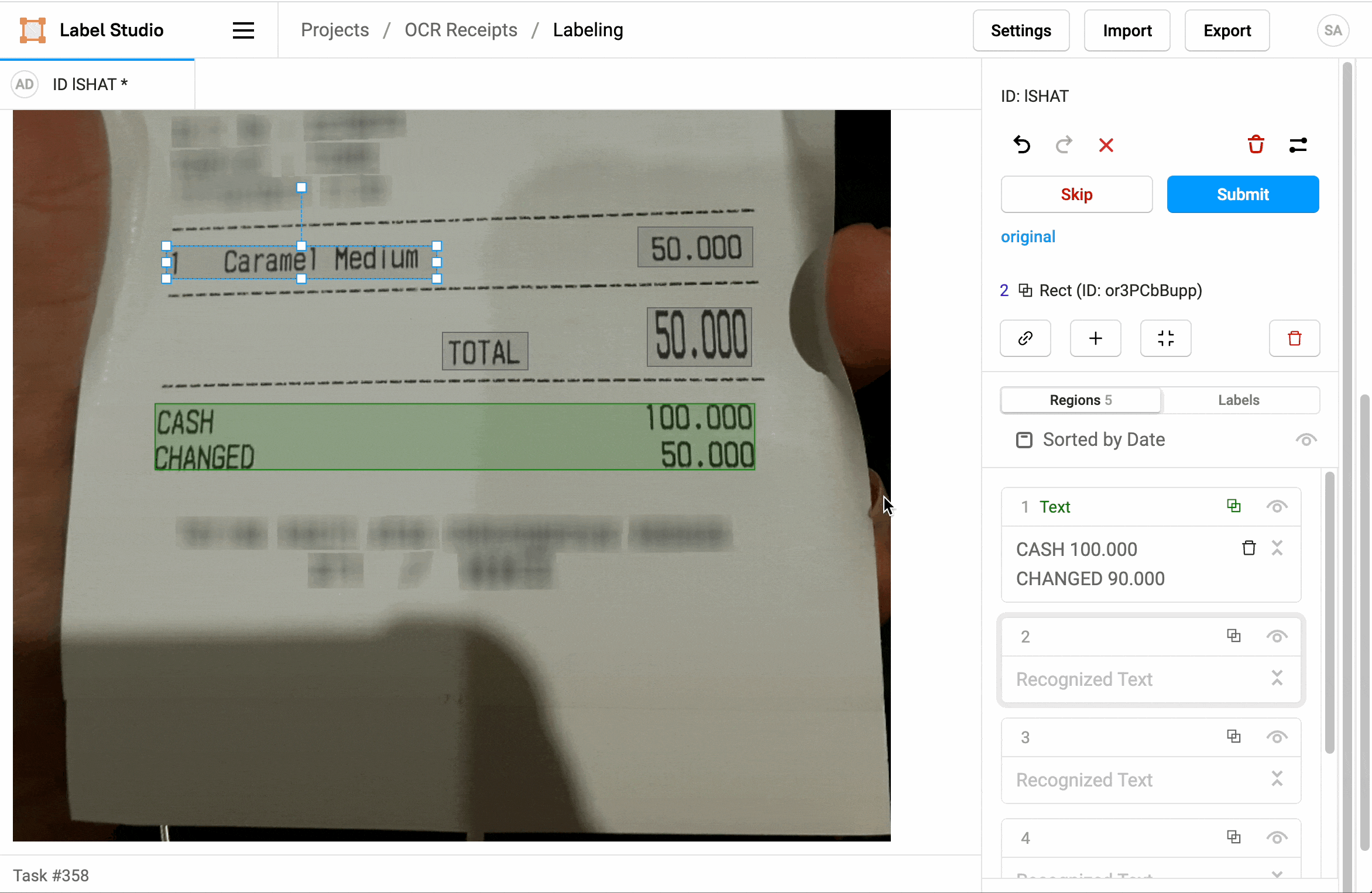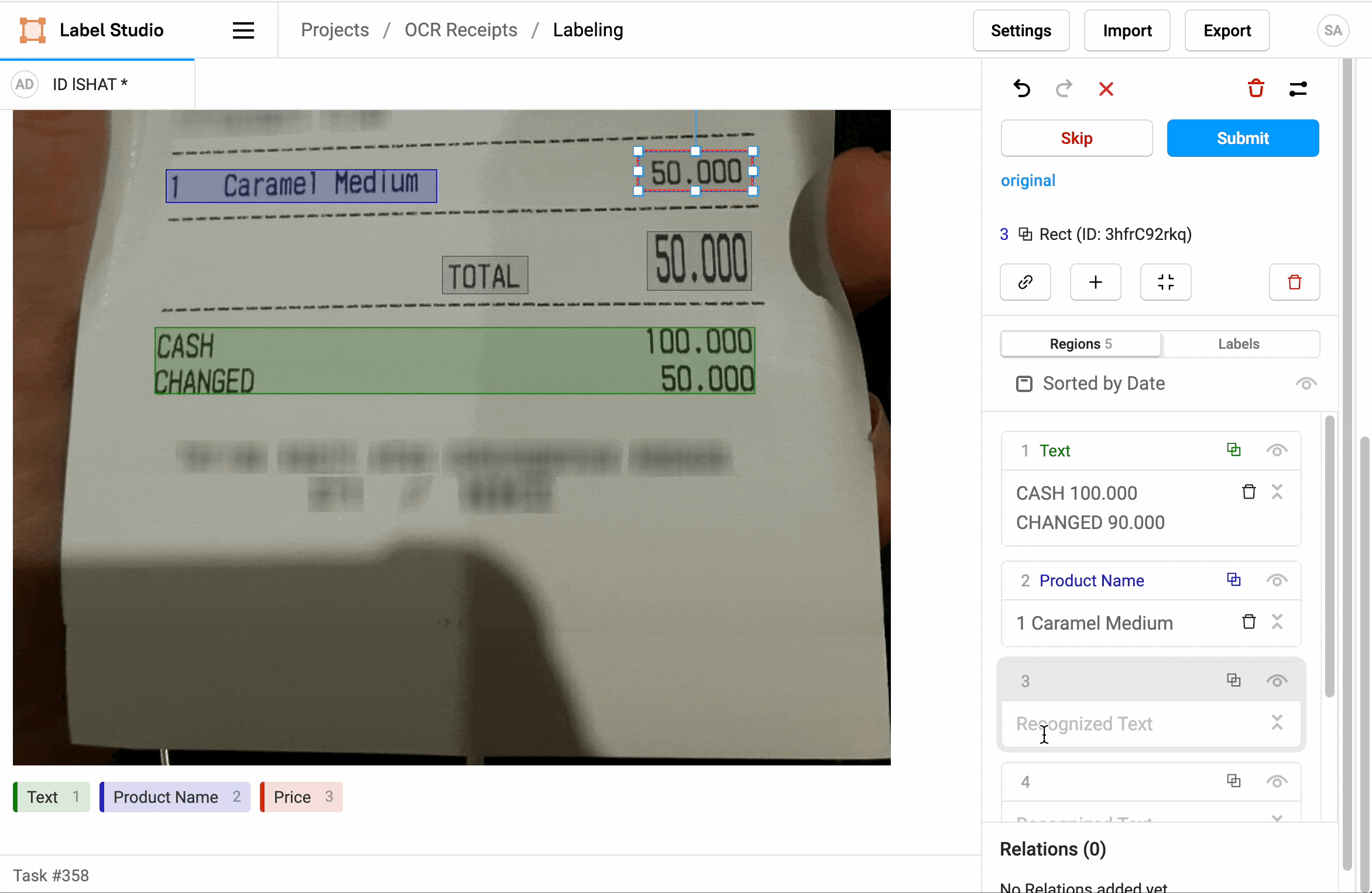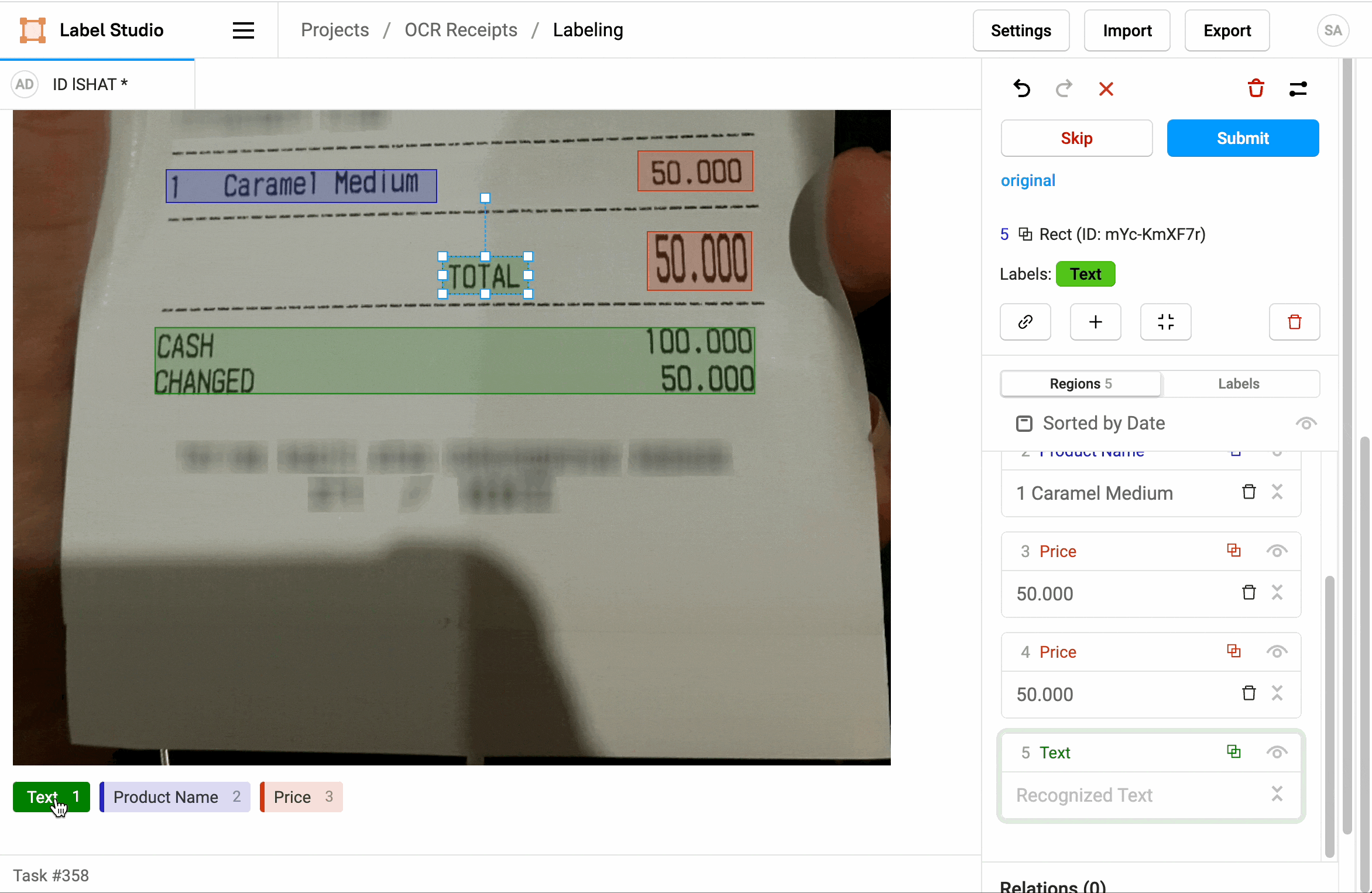
¿Cuál es la importancia del OCR?
El OCR es muy importante en sus diversos usos, que incluyen:
Digitalización y conservación de documentos
Como se mencionó anteriormente, el OCR permite convertir documentos en papel a formatos electrónicos, lo que facilita su almacenamiento y conservación a largo plazo. Esto ayuda a preservar los registros importantes e históricos que, de otro modo, podrían deteriorarse con el tiempo.
Accesibilidad
El OCR hace que el contenido de los materiales impresos sea accesible para las personas ciegas o con discapacidad visual. En particular, permite la conversión de texto en formatos que pueden leerse mediante un software de síntesis de voz o pantallas Braille.
Investigación y análisis de contenido
Una vez que el texto se convierte a formato electrónico, resulta más fácil buscarlo, ordenarlo y analizarlo. Esto facilita la búsqueda de información específica en grandes conjuntos de documentos. Esto puede resultar muy útil en áreas como la investigación académica, legal, médica o comercial.
-hand-innv.png)
¿Qué hace que el OCR sea tan importante (aunque a veces subestimado) en la era de la IA?
En la era de la IA, el OCR es cada vez más importante debido a los avances tecnológicos que conlleva, que incluyen:
Integración en flujos de trabajo automatizados
La integración del OCR en sistemas basados en inteligencia artificial automatiza tareas como la clasificación de documentos, la extracción de texto u otra información y el procesamiento de datos. Esto puede acelerar los procesos empresariales, reducir los errores humanos y liberar tiempo para tareas más estratégicas.
Entrenamiento de modelos de IA
Análisis de datos no estructurados
Se encuentra mucha información valiosa en documentos no estructurados como informes, contratos, formularios,... El OCR permite hacer que estos datos sean accesibles para su análisis mediante algoritmos de inteligencia artificial. Esto abre nuevas posibilidades para la innovación y la toma de decisiones basadas en datos.
¿Cómo da forma el OCR a las tareas de anotación de datos?
En muchos casos de uso, el OCR (reconocimiento óptico de caracteres) participa activamente en la forma en que se configuran las tareas de anotación de datos. A continuación se muestran algunas ilustraciones:
Preprocesamiento de datos
Aumento de datos
El OCR se puede utilizar para aumentar los conjuntos de datos convirtiendo documentos no textuales en texto extraído. Esto aumenta la variedad y la cantidad de datos disponibles para entrenar modelos de IA. Al mismo tiempo, esto puede mejorar el rendimiento de estos modelos.
Validación y corrección de anotaciones
Cuando los anotadores humanos trabajan en tareas de anotación, el OCR se puede usar para validar o corregir las anotaciones producidas. Por ejemplo, si un anotador ha anotado incorrectamente parte del texto de una imagen, se puede usar el OCR para comprobar si el texto extraído coincide con la anotación. Esto puede ayudar a garantizar la calidad de los datos anotados.
Mejora de la eficiencia
Al utilizar el OCR para extraer texto de las imágenes, las tareas de anotación pueden hacerse más eficientes. En lugar de pedir a los anotadores que escriban manualmente el texto que se va a anotar, pueden centrarse en la tarea de anotación específica. Es una excelente manera de acelerar el proceso general de procesamiento de datos.
Adaptación a necesidades específicas
El OCR se puede adaptar para satisfacer las necesidades específicas de las tareas de anotación. Por ejemplo, en el caso de documentos que contienen idiomas o fuentes particulares, se pueden desarrollar plantillas de OCR personalizadas para mejorar la precisión de la extracción del texto. Esto es especialmente importante en los proyectos de anotación de datos que son sensibles a la calidad de los datos (es decir, ¡en la gran mayoría de los proyectos!).
¿Cómo allanaron el camino los primeros sistemas de OCR para la tecnología actual?
Los primeros sistemas de OCR sentaron las bases para el desarrollo de la tecnología actual. Superaron numerosos desafíos técnicos e introdujeron conceptos fundamentales que se siguen utilizando en la actualidad.
Reconocimiento de caracteres basado en reglas
Los primeros sistemas de OCR solían utilizar enfoques basados en reglas para reconocer los caracteres. Estos enfoques incluían la definición de reglas específicas para reconocer las formas de los personajes en función de características como el tamaño, la forma y la disposición de los rasgos.
Si bien estos métodos eran limitados en términos de precisión y capacidad para manejar una variedad de fuentes, sentaron las bases para futuros desarrollos en este campo.
Modelos estadísticos
Más tarde, los sistemas de OCR comenzaron a utilizar modelos estadísticos para mejorar la precisión del reconocimiento de caracteres. Estos modelos se basaron en grandes cantidades de datos para aprender las características de los caracteres y las palabras en diferentes contextos.
Este enfoque ha mejorado considerablemente la precisión del reconocimiento óptico de caracteres, especialmente en entornos en los que las fuentes y los estilos de escritura pueden variar.
Uso de redes neuronales
Los avances recientes en el campo del aprendizaje profundo han llevado a la adopción de redes neuronales para el reconocimiento de caracteres. Estas redes neuronales han demostrado un rendimiento notable en el reconocimiento de texto. Este es, en particular, el caso de las redes neuronales convolucionales (CNN) y las redes neuronales recurrentes (RNN).
Estos modelos mejoraron significativamente la precisión del OCR y permitieron procesar una amplia variedad de fuentes y estilos de escritura. Esto se logra mediante el uso de arquitecturas profundas y técnicas de entrenamiento avanzadas con grandes cantidades de datos.
Adaptación a datos específicos
Los sistemas de OCR modernos suelen incorporar mecanismos para adaptarse a datos específicos a fin de mejorar la precisión del reconocimiento. Esto puede incluir el entrenamiento de modelos de OCR con datos específicos de un dominio o idioma en particular. Esto también incluye el uso de técnicas de adaptación continua para ajustar los modelos en función de los nuevos datos observados en los escenarios de producción.
OCR: más allá de la digitalización de documentos, ¿qué otras aplicaciones está revolucionando?
Más allá de la simple digitalización de documentos, el OCR aporta importantes innovaciones a muchas otras aplicaciones.
Traducción automática
El OCR se usa a menudo en combinación con sistemas de traducción automática para traducir materiales impresos a varios idiomas. Al convertir primero el texto a formato electrónico mediante OCR, los sistemas de traducción automática pueden traducir el texto al idioma deseado.
Extracción de información
El OCR se puede utilizar para extraer información específica de documentos, como facturas, formularios o recibos o recibos. Por ejemplo, en la contabilidad, el OCR se puede utilizar para extraer automáticamente importes, fechas y otra información relevante de las facturas escaneadas. Esto puede acelerar considerablemente los procesos de procesamiento de datos.
Reconocimiento de texto en imágenes y vídeos
El OCR también se puede utilizar para extraer texto de imágenes o videos. Esto es útil en los casos en los que puede ser necesario buscar un texto específico en las grabaciones de vídeo. O incluso en el reconocimiento automático de matrículas a partir de imágenes de cámaras de vigilancia.
¿Qué nuevas fronteras podría cruzar la OCR en los próximos años?
En los próximos años, el OCR podría cruzar nuevas fronteras gracias a la rápida evolución de la tecnología y, en particular, de la inteligencia artificial. En el momento de redactar este artículo, las técnicas de desarrollo de la IA se renuevan cada 2 semanas, ¡o casi! La integración con otros campos de la inteligencia artificial y la informática también puede desempeñar un papel.
Reconocimiento avanzado de documentos manuscritos
Los avances en el procesamiento de imágenes y las técnicas de aprendizaje automático podrían permitir un reconocimiento más preciso de los documentos escritos a mano. Esto es cierto incluso en condiciones difíciles, como estilos de escritura variados, documentos dañados o idiomas con caracteres complejos.
Reconocimiento multimodal
La integración del OCR con otras modalidades sensoriales podría permitir un reconocimiento multimodal más sólido y contextualmente más rico. Esto podría incluir el reconocimiento de objetos en imágenes, el reconocimiento de voz y la comprensión del lenguaje natural. Esto abriría nuevas posibilidades en áreas como la realidad aumentada, los coches autónomos y las interfaces de usuario inteligentes.
OCR basado en aprendizaje profundo
El uso de arquitecturas de redes neuronales profundas y técnicas de aprendizaje profundo podría mejorar significativamente la precisión del OCR. Especialmente en situaciones difíciles, como el reconocimiento de documentos con fuentes variadas, idiomas distintos del latín y sistemas de escritura complejos.
OCR en tiempo real
Los avances en las tecnologías de procesamiento de imágenes y las arquitecturas de hardware podrían permitir la implementación del OCR en tiempo real en dispositivos móviles y sistemas integrados. Esto abriría nuevas posibilidades en aplicaciones como la realidad aumentada (VR), la traducción en tiempo real y la asistencia visual para personas ciegas o con discapacidad visual.
OCR adaptativo y de autoaprendizaje
El OCR podría ser más adaptativo y de autoaprendizaje. Esto se logra mediante el uso de técnicas de aprendizaje continuo para adaptarse automáticamente a nuevos tipos de documentos, idiomas y estilos de escritura. Esto podría permitir una mejor generalización y una mayor solidez del OCR en entornos variados.
Protección de la privacidad y seguridad de los datos
Con el aumento del uso del OCR para gestionar documentos confidenciales, es probable que se centre cada vez más en el desarrollo de técnicas para proteger la privacidad y la seguridad de los datos. Esto es para garantizar que la información confidencial, como la información médica, financiera o legal, no se vea comprometida durante el proceso de reconocimiento.
Conclusión
El OCR (reconocimiento óptico de caracteres), o reconocimiento óptico de caracteres, es una tecnología que transforma los documentos impresos en texto editable. Abre el camino a numerosas aplicaciones prácticas. Al analizar las imágenes de los documentos, el OCR identifica y convierte los caracteres en texto digital, lo que facilita la búsqueda, la traducción y la automatización de los procesos.
Aunque puede enfrentarse a varios desafíos técnicos, como la precisión del reconocimiento y la variabilidad del lenguaje, el OCR sigue evolucionando gracias a los avances en la inteligencia artificial y el procesamiento de imágenes. Por lo tanto, el OCR promete hacer que la información impresa sea más accesible, manipulable y utilizable que nunca.



