Reinforcement Learning from Human Feedback (RLHF): a detailed guide

”Reinforcement Learning from Human Feedback“(or RLHF) is a technique of Machine Learning (ML) that uses human feedback to ensure that large language models (LLMs) or other AI systems offer answers similar to those formulated by humans.
RLHF learning is playing a revolutionary role in the transformation of artificial intelligence. It is considered to be the industry standard technique for making LLMs more effective and accurate in how they mimic human responses. The best example is GPT chat. When the team of OpenAI developed ChatGPT, she applied the RLHF to the GPT model to make ChatGPT able to respond as it does today (i.e. in a near natural way).
Essentially, RLHF includes human input and feedback in the reinforcement learning model. This helps improve the efficiency of AI applications and aligns them with human expectations.
Considering the importance and usefulness of RLHF for developing complex models, the community of AI researchers and developers have invested a lot in this concept. In this article, we have tried to popularize its principle, by covering everything you need to know about learning through “Reinforcement Learning from Human Feedback” (RLHF), including its basic concept, operating principle, operating principle, operating principle, benefits, and much more. If there's one thing to remember, it's that this process involves mobilizing moderators/evaluators in the AI development cycle. Innovatiana offers these AI assessment services: Do Not Hesitate to Ask Us !
In AI, what is learning through “Reinforcement Learning from Human Feedback” (RLHF)?
Apprenticeship by “Reinforcement Learning from Human Feedback” (RLHF) is a machine learning (ML) technique that involves human feedback to help ML models self-learn more effectively. Reinforcement learning (RL) techniques make it possible to train Software/Models to make decisions that maximize rewards. This leads to more accurate results (and less biased).
RLHF involves incorporating human feedback into the reward function, which causes the ML model to perform tasks that match human needs and goals. It gives the model the power to correctly interpret human instructions, even if they are not clearly described. In addition, it also helps the existing model improve its ability to generate natural language.
Today, In particular, RLHF is deployed in all generative artificial intelligence applications, especially in large language models (LLMs).
The fundamental concept behind the RLHF
To better understand the RLHF, it is important to first understand Reinforcement learning (RL) Then the role of Feedback Human in this one.
Reinforcement learning (RL) is an ML technique in which The Agent/Model Interacts with Their Environment to Learn to Make Decisions. To do this, he performs actions that impact his environment, makes it move to a new state and returns a reward. The reward he receives is like feedback, which improves the agent's decision-making. This feedback process goes on and on to improve agent decision making. However, designing an effective reward system is difficult. That's where human interaction and feedback come in.
Human feedback addresses the shortcomings of the reward system by involving a Human Reward Signal Through a Human Supervisor. In this way, the agent's decision making becomes more effective. Most RLHF systems involve both collecting human feedback and automated reward signals for faster training.
RLHF and its role in large language models (LLMs)
For the general public, including specialists outside the AI research community, when we hear about RLHF, it is mainly Related to large language models (LLMs). As mentioned earlier, RLHF is the industry standard technique for making LLMs more effective and accurate in mimicking human responses.
LLMS are designed to predict the next word/token in a sentence. For example, if you enter the beginning of a sentence into a GPT language model now, it will complete it by adding logical sentences (or sometimes hallucinated or even biased - but that's another debate).
However, humans don't just want the LLM to complete sentences. They want him to understand their complex requests and respond consistently. For example, suppose you ask the LLM to “write a 500 word article on cybersecurity.” In this case, he may interpret the instructions incorrectly and respond by telling you how to write a cybersecurity article instead of writing an article for you. This mostly happens due to an ineffective reward system. This is exactly what the RLHF means for LLMs. Are you following?
The RLHF enhances the abilities of LLMs by incorporating a reward system with human feedback. This teaches the model to take human advice into account and to respond in a way that best aligns with human expectations. In short, the RLHF is the key for LLMs to make responses similar to those of humans. This could also, in some way, explain why a model like ChatGPT is more attentive to questions that are formulated in a courteous manner (as in real life, a “please” in a question is more likely to get a quality answer!).
-hand-innv.png)
Why is RLHF important?
The artificial intelligence (AI) industry is booming today with the emergence of a wide range of applications, including natural language processing (NLP), self-driving cars, stock market predictions, etc. However, the main objective of almost all AI applications is to Replicate Human Responses or Make Decisions Similar to Those of Humans.
The RLHF plays a major role in training AI models/applications to respond in a more humane way. In the RLHF development process, the model initially gives an answer that is a bit like what could be formulated by a human. Then, a Human Supervisor (like our team of moderators at Innovatiana) gives direct feedback and a score to the response based on various aspects involving human values, such as mood, conviviality, feelings associated with a text or image, etc. For example, a model translates text that seems technically correct, but it may seem unnatural to the reader. It is what the Feedback Human can detect. In this way, the model continues to learn from human responses and improves its results to match human expectations.
If you use ChatGPT regularly, you may have noticed that ChatGPT offers options and sometimes asks you to choose the best answer. You unwittingly participated in his training process as a supervisor!
The importance of the RLHF is obvious in terms of the following aspects:
- Making AI more accurate : It improves the accuracy of models by incorporating an additional human feedback loop.
- Facilitate complex training parameters : RLHF helps in training models with complex parameters, such as guessing the feeling associated with music or text (sadness, joy, particular state of mind, etc.).
- Satisfying Users : It makes models respond in a more humane way, which increases user satisfaction.
In Short, the RLHF is a AI development cycle tool to optimize the performance of ML models and enable them to imitate human responses and decision-making.
RLHF training process step by step
Reinforcement learning with human feedback or”Reinforcement Learning from Human Feedback“(RLHF) extends the self-supervised learning that large language models undergo as part of the training process. However, RLHF is not a self-sufficient learning model, as the use of human testers and trainers makes the whole process expensive. Therefore, most businesses use the RLHF to Fine Tuner A pre-trained model, i.e. complete an automated AI development cycle with a Human Intervention.
The step-by-step RLHF development/training process is as follows:
Step 1. Pre-training a language model
The first step is pre-training the language model (like BERT, GPT, or LLama to name a few) using a large amount of text data. This training process allows the language model to understand the various nuances of the human language, such as semantics or syntax, and of course the language.

The main activities involved in this stage are as follows:
1. Choose a basic language model for the RLHF process. For example, OpenAI uses a lightweight version of GPT-3 For its RLHF model.
2. Gather raw data from the Internet and other sources and pre-process it to make it suitable for training.
3. Train the language model with the data.
4. Evaluate the post-training language model using a different data set.
For the LM to gain more knowledge about human preferences, Humans are involved in generating answers to prompts or questions. These answers are also used for Train the reward model.
Step 2. Training a reward model
A reward model is a Language model that sends a ranking signal to the original language model. Basically, it serves as an alignment tool that integrates human preferences into the AI learning process. For example, an AI model generates two answers to the same question, so the reward model will indicate which answer is closer to human preferences.

The main activities involved in the formation of the reward model are as follows:
- Establish the reward model, which can be a modular system or an end-to-end language model.
- Train the reward model with a different data set than the one used when pre-training the language model. The data set is composed of prompt and reward pairs, i.e., each prompt reflects an expected exit with associated rewards for exhibiting the desirable nature of the exit.
- Train the model using prompts (or “prompts”) and reward pairs for Associate Specific Outputs with Corresponding Reward Values.
- Integrating human feedback into reward model training to refine the model. For example, ChatGPT integrates human feedback by asking users to categorize the response by clicking thumbs down or thumbs up.
Step 3. Fine tuning Of the Language Model or LM with Reinforcement Learning
The Last Step, and the Most Critical, is the Fine tuning Of the natural language comprehension model with reinforcement learning. This refinement is critical to ensure that the language model provides reliable responses to user prompts. To do this, AI specialists use various reinforcement learning techniques, such as Optimization of the Proximal Policy (PPO) and the Kullback—Leibler divergence (KL).
The main activities involved in the refining of LM are as follows:
1. User input is sent to the RL policy (the adjusted version of the LM). The RL policy generates the response. The response from the RL policy and the initial output from the LM are then evaluated by the reward model, which provides a scalar reward value based on the quality of the responses.
2. The above process continues in a feedback loop, so the reward model continues to award rewards to as many samples as possible. In this way, the RL policy will continuously start generating responses in a style similar to that of humans.
3. Divergence (KL) is a statistical method for evaluating the difference between two probability distributions.. It is used to compare the probability distribution among current RL policy responses with the reference distribution that reflects the best human-style responses.
4. Proximal Policy Optimization (PPO) Is a reinforcement learning algorithm that Effectively optimizes policies in complex environments involving high-dimensional state/action spaces. It is very useful for refining the LM because it balances exploitation and exploration during training. Since RLHF agents need to learn from human feedback and exploration through trial and error, this balance is vital. In this way, the PPO helps to achieve robust and faster learning.
That's all, and that's already quite good! This is how a complete RLHF training process takes place, starting with a pre-training process and ending with an AI agent with a Fine tuning thorough.
How is RLHF used in ChatGPT?
Now that we know how an RLHF works, let's take a concrete example: let's discuss how the RLHF is embedded in the training process of ChatGPT - the most popular AI chatbot in the world.
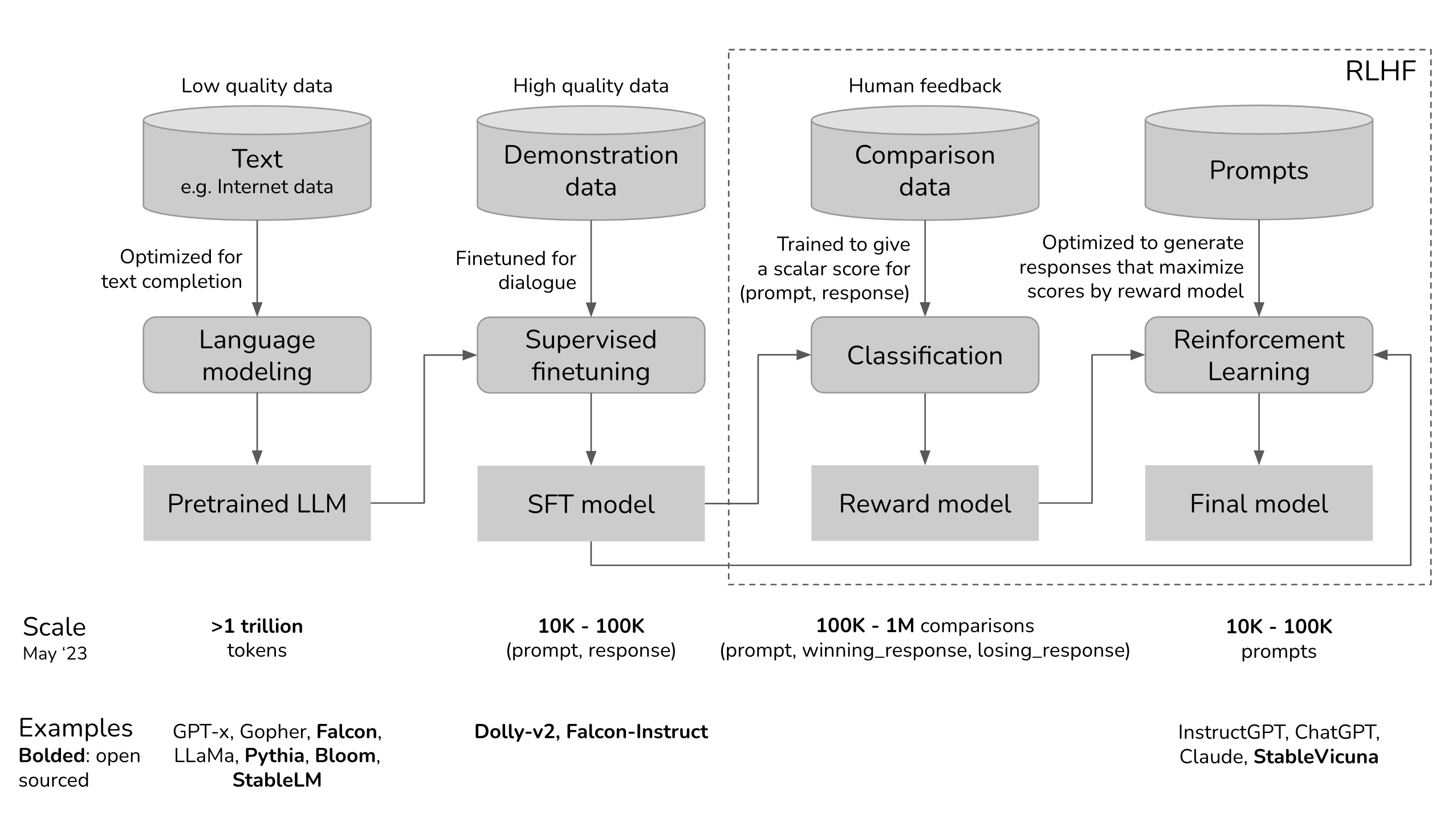
ChatGPT uses the RLHF framework to train the language model to provide responses that are appropriate to a context and similar to those of humans.. The three main steps included in her training process are:
1. Fine tuning Of the language model
The process starts with theUsing Supervised Learning Data to Refine the Initial Language Model. This requires building a data set of conversations where AI trainers play the roles of both AI assistant and user. In other words, AI trainers use suggestions written by the model to write their answers. In this way, the data set is built with a mixture of text written by the model and generated by the human, which means a collection of various responses from the model.
2. Creating a Reward Model
After refining the initial model, the reward model comes into play. In this stage, the reward model is created to reflect human expectations. For this, Human Annotators Rank the responses generated by the model according to human preference, quality, and other factors.
Rankings are used to train the second machine learning model, called Reward model. This model is able to predict the extent to which the reward function of a response is aligned with human preferences.
3. Improving the Model with Reinforcement Learning
Once the reward model is ready, the final step is to improve the main outputs of the language model and the model through reinforcement learning. Here, Proximal Policy Optimization (PPO) helps the LLM generate responses that score higher according to the reward model.
The three steps above are iterative, meaning they happen in a loop to improve the performance and accuracy of the entire model.
What are the challenges of using RLHF in ChatGPT?
While the RLHF in ChatGPT has improved response efficiency significantly, it has some challenges, as follows:
- Addressing different human preferences. Every human has different preferences. As a result, it is difficult to define a reward model that meets all types of preferences.
- Human work for moderation such as “Human Feedback”. Dependence on human work to optimize responses is costly and slow (and sometimes unethical).
- Using Language Exempt. Particular attention is required to ensure the consistency of the language (English, French, Spanish, Malagasy, etc.) while improving responses.
Benefits of RLHF
From all the discussions so far, it's obvious that the RLHF is playing a leading role in optimizing AI applications. Some of the main benefits it offers are:
- Adaptability: The RLHF offers a dynamic learning strategy that adapts based on feedback. This helps them adapt their behavior based on real-time feedback/interactions and adapt well to a wide range of tasks.
- Continuous improvement: Models based on the RLHF are capable of continuous improvement based on user interactions and more feedback. In this way, they will continue to improve their performance over time.
- Reducing model bias: The RLHF reduces model bias by involving human feedback, which minimizes concerns of bias or overgeneralization of the model.
- Enhanced Security : RLHF makes AI applications safe because the human feedback loop prohibits AI systems from triggering inappropriate behavior.
In summary, RLHF is the key to optimizing AI systems and make them work in a way that is in line with human values and intentions.
Challenges and Limits of the RLHF
The enthusiasm for the RLHF also comes with a set of challenges and limitations. Some of the main challenges/limitations of the RLHF are as follows:
- Human bias : Chances are that the RLHF model can deal with human bias, as human raters may unfairly influence their biases in responses.
- Scalability : Since the RLHF relies heavily on human feedback, it is difficult to scale the model for larger tasks due to the extensive demand for time and resources.
- Dependence on the Human Factor : The accuracy of the RLHF model is influenced by the human factor. As a result, inefficient human responses, especially in advanced queries, can compromise model performance.
- Formulation of the question : The quality of the model's response depends mainly on the wording of the question. If the wording of the question is unclear, the model may still not be able to respond appropriately despite extensive RLHF limitations.
Conclusion — What is the future of RLHF?
Undoubtedly, “Reinforcement Learning from Human Feedback” (RLHF) promises a bright future and is ready to continue playing a major role in the AI industry. With the main objective of having an AI that mimics human behaviors and mechanisms, the RLHF will continue to improve this aspect through new/advanced techniques. Additionally, there will be an increasing focus on resolving its limitations and ensuring a balance between AI capabilities and ethical concerns.
At Innovatiana, we hope to contribute to AI development processes involving the RLHF: our moderators are specialized, familiar with tools and labeling techniques. They are able to support you in your most complex AI assessment tasks!



