Aprendizaje reforzado a partir de la retroalimentación humana (RLHF): una guía detallada

Aprendizaje reforzado a partir de la retroalimentación humana« (Reinforcement Learning with Human Feedback o RLHF) es una técnica de Aprendizaje automático (ML) que utiliza la retroalimentación humana para garantizar que los modelos lingüísticos grandes (LLM) u otros sistemas de IA ofrecen respuestas similares a las formuladas por los humanos.
El aprendizaje RLHF está desempeñando un papel revolucionario en la transformación de la inteligencia artificial. Se considera la técnica estándar de la industria para hacer que los LLM sean más efectivos y precisos en la forma en que imitan las respuestas humanas. El mejor ejemplo es Chat GPT, cuando el equipo de OpenAI desarrolló ChatGPT y aplicó el RLHF al modelo GPT para que ChatGPT pudiera responder como lo hace hoy (es decir, de una manera casi natural).
Esencialmente, RLHF incluye comentarios y comentarios humanos en el modelo de aprendizaje por refuerzo. Esto ayuda a mejorar la eficiencia de las aplicaciones de inteligencia artificial y las alinea con las expectativas humanas.
Teniendo en cuenta la importancia y la utilidad del RLHF para desarrollar modelos complejos, la comunidad de investigadores y desarrolladores de IA ha invertido mucho en este concepto. En este artículo, hemos intentado popularizar su principio, explicando todo lo que necesitas saber sobre el aprendizaje mediante el «aprendizaje por refuerzo a partir de la retroalimentación humana» (RLHF), incluidos su concepto básico, su principio de funcionamiento, sus beneficios y mucho más. Si hay algo que recordar, es que este proceso implica la movilización de moderadores y evaluadores en el ciclo de desarrollo de la IA. Innovatiana ofrece los siguientes servicios de evaluación de la IA: no dudes en preguntarnos !
En la IA, ¿qué es el aprendizaje mediante el «aprendizaje por refuerzo a partir de la retroalimentación humana» (RLHF)?
Aprendizaje realizado por «Aprendizaje reforzado a partir de la retroalimentación humana» (RLHF) es una técnica de aprendizaje automático (ML) que incluye la retroalimentación humana para ayudar a los modelos de aprendizaje automático a aprender por sí mismos de manera más efectiva. Las técnicas de aprendizaje por refuerzo (RL) permitencapacite el software y los modelos para tomar decisiones que maximicen las recompensas. Esto conduce a resultados más precisos.
La RLHF implica incorporar la retroalimentación humana en la función de recompensa, lo que hace que el modelo ML realice tareas que coincidan con las necesidades y objetivos humanos. Le da al modelo el poder de interpretar correctamente las instrucciones humanas, incluso si no se describen con claridad. Además, también ayuda al modelo existente a mejorar su capacidad de generar lenguaje natural.
En la actualidad, En particular, el RLHF se implementa en todas las aplicaciones de inteligencia artificial generativa, especialmente en los grandes modelos lingüísticos (LLM).
El concepto fundamental detrás del RLHF
Para entender mejor el RLHF, es importante entender primero el aprendizaje por refuerzo (RL) entonces el papel de Retroalimentación humano en este.
El aprendizaje por refuerzo (RL) es una técnica de aprendizaje automático en la que el agente/modelo interactúa con su entorno para aprender a tomar decisiones. Para ello, realiza acciones que afectan a su entorno, lo hace pasar a un nuevo estado y devuelve una recompensa. La recompensa que recibe es similar a la retroalimentación, lo que mejora la toma de decisiones del agente. Este proceso de retroalimentación es continuo para mejorar la toma de decisiones de los agentes. Sin embargo, diseñar un sistema de recompensas efectivo es difícil. Ahí es donde entran en juego la interacción humana y la retroalimentación.
La retroalimentación humana aborda las deficiencias del sistema de recompensas al incluir un señal de recompensa humana a través de un supervisor humano. De esta forma, la toma de decisiones del agente se hace más efectiva. La mayoría de los sistemas de RLHF implican tanto la recopilación de comentarios humanos como la automatización de señales de recompensa para un entrenamiento más rápido.
La RLHF y su papel en los grandes modelos lingüísticos (LLM)
Para el público en general, incluidos los especialistas ajenos a la comunidad de investigación de la IA, cuando oímos hablar de la RLHF, es principalmente relacionados con los grandes modelos lingüísticos (LLM). Como se mencionó anteriormente, el RLHF es la técnica estándar de la industria para hacer que los LLM sean más efectivos y precisos a la hora de imitar las respuestas humanas.
Los LLMS están diseñados para predecir la siguiente palabra/símbolo de una oración. Por ejemplo, si ahora escribes el principio de una oración en un modelo lingüístico GPT, la completará añadiendo frases lógicas (o a veces alucinaba o incluso sesgados, pero ese es otro debate).
Sin embargo, los humanos no solo quieren que el LLM complete oraciones. Quieren que comprenda sus complejas solicitudes y responda en consecuencia. Por ejemplo, supongamos que le pides al LLM que «escriba un artículo de 500 palabras sobre ciberseguridad». En este caso, es posible que interprete las instrucciones de forma incorrecta y responda diciéndote cómo escribir un artículo sobre ciberseguridad en lugar de escribir un artículo para ti. Esto ocurre principalmente debido a un sistema de recompensas ineficaz. Esto es exactamente lo que significa la RLHF para los LLM. ¿Me estás siguiendo?
La RLHF mejora las habilidades de los LLM al incorporar un sistema de recompensas con comentarios humanos. Esto enseña al modelo a tener en cuenta los consejos humanos y a responder de la manera que mejor se alinee con las expectativas humanas. En resumen, el RLHF es la clave para que los LLM obtengan respuestas similares a las de los humanos. Esto también podría, de alguna manera, explicar por qué un modelo como ChatGPT presta más atención a las preguntas que se formulan de manera cortés (como en la vida real, un «por favor» en una pregunta tiene más probabilidades de obtener una respuesta de calidad).
-hand-innv.png)
¿Por qué es importante el RLHF?
La industria de la inteligencia artificial (IA) está en auge hoy en día con la aparición de una amplia gama de aplicaciones, que incluyen el procesamiento del lenguaje natural (PNL), los coches autónomos, las predicciones bursátiles, etc. Sin embargo, el objetivo principal de casi todas las aplicaciones de IA es replicar las respuestas humanas o tomar decisiones similares a las de los humanos.
La RLHF desempeña un papel importante en el entrenamiento de modelos y aplicaciones de IA para responder de una manera más humana. En el proceso de desarrollo del RLHF, el modelo inicialmente da una respuesta que se parece un poco a la que podría formular un humano. Luego, un supervisor humano (como nuestro equipo de moderadores en Innovatiana) proporciona comentarios directos y puntúa la respuesta en función de varios aspectos relacionados con los valores humanos, como el estado de ánimo, la cordialidad, los sentimientos asociados con un texto o una imagen, etc. Por ejemplo, un modelo traduce un texto que parece técnicamente correcto, pero que puede parecer antinatural para el lector. Es lo que Retroalimentación el ser humano puede detectar. De esta manera, el modelo continúa aprendiendo de las respuestas humanas y mejora sus resultados para que coincidan con las expectativas humanas.
Si usa ChatGPT con regularidad, es posible que haya notado que ChatGPT ofrece opciones y, a veces, le pide que elija la mejor respuesta. ¡Has participado sin darte cuenta en su proceso de formación como supervisor!
La importancia del RLHF es evidente en términos de los siguientes aspectos:
- Hacer que la IA sea más precisa : Mejora la precisión de los modelos al incorporar un circuito de retroalimentación humana adicional.
- Facilitar parámetros de entrenamiento complejos : La RLHF ayuda a entrenar modelos con parámetros complejos, como adivinar la sensación asociada con la música o el texto (tristeza, alegría, estado mental particular, etc.).
- Usuarios satisfactorios : Hace que las modelos respondan de una manera más humana, lo que aumenta la satisfacción de los usuarios.
En resumen, el RLHF es un Herramienta de ciclo de desarrollo de IA para optimizar el rendimiento de los modelos de aprendizaje automático y permitirles imitar las respuestas y la toma de decisiones humanas.
Proceso de formación en RLHF paso a paso
Reforzar el aprendizaje con retroalimentación humana o»Aprendizaje reforzado a partir de la retroalimentación humana«(RLHF) amplía el aprendizaje autosupervisado al que se someten los grandes modelos lingüísticos como parte del proceso de formación. Sin embargo, el RLHF no es un modelo de aprendizaje autosuficiente, ya que el uso de evaluadores y entrenadores humanos encarece todo el proceso. Por lo tanto, la mayoría de las empresas utilizan el RLHF para Sintonizador fino un modelo previamente entrenado, es decir, completar un ciclo de desarrollo de IA automatizado con un intervención humana.
El proceso paso a paso de desarrollo y capacitación de RLHF es el siguiente:
Paso 1. Entrenamiento previo de un modelo lingüístico
El primer paso es entrenar previamente el modelo lingüístico (como BERT, GPT o LLama, por nombrar algunos) mediante un gran cantidad de datos de texto. Este proceso de formación permite al modelo lingüístico comprender los diversos matices del lenguaje humano, como la semántica o la sintaxis y, por supuesto, el idioma.

Las principales actividades de esta etapa son las siguientes:
1. Elija un modelo lingüístico básico para el proceso RLHF. Por ejemplo, OpenAI usa una versión ligera de GPT-3 para su modelo RLHF.
2. Recopile datos sin procesar de Internet y otras fuentes y preprocéselos para que sean adecuados para la capacitación.
3. Entrene el modelo lingüístico con los datos.
4. Evalúe el modelo lingüístico posterior a la formación utilizando un conjunto de datos diferente.
Para que el LM adquiera más conocimientos sobre las preferencias humanas, los seres humanos participan en la generación de respuestas a indicaciones o preguntas. Estas respuestas también se utilizan para entrena el modelo de recompensas.
Paso 2. Entrenar un modelo de recompensas
Un modelo de recompensa es un modelo lingüístico que envía una señal de clasificación al modelo lingüístico original. Básicamente, sirve como una herramienta de alineación que integra las preferencias humanas en el proceso de aprendizaje de la IA. Por ejemplo, un modelo de IA genera dos respuestas a la misma pregunta, por lo que el modelo de recompensa indicará qué respuesta se acerca más a las preferencias humanas.

Las principales actividades involucradas en la formación del modelo de recompensa son las siguientes:
- Establezca el modelo de recompensa, que puede ser un sistema modular o un modelo lingüístico de extremo a extremo.
- Entrene el modelo de recompensa con un conjunto de datos diferente al que se utilizó al entrenar previamente el modelo lingüístico. El conjunto de datos está compuesto por pares de avisos y recompensas, es decir, cada aviso refleja una salida esperada con las recompensas asociadas por mostrar la naturaleza deseable de la salida.
- Entrena al modelo usando indicaciones (o «indicaciones») y pares de recompensas por asociar salidas específicas con los valores de recompensa correspondientes.
- Integrar la retroalimentación humana en la capacitación del modelo de recompensa para refinar el modelo. Por ejemplo, ChatGPT integra los comentarios humanos al pedir a los usuarios que clasifiquen la respuesta haciendo clic con el pulgar hacia abajo o con el pulgar hacia arriba.
Paso 3. Afinación fina del modelo lingüístico o LM con aprendizaje por refuerzo
El último paso, y el más importante, es Afinación fina del modelo de comprensión del lenguaje natural con aprendizaje por refuerzo. Este refinamiento es fundamental para garantizar que el modelo lingüístico proporcione respuestas confiables a las instrucciones de los usuarios. Para ello, los especialistas en IA utilizan varias técnicas de aprendizaje por refuerzo, comoOptimización de la política proximal (PPO) y el Divergencia Kullback-Leibler (L).
Las principales actividades relacionadas con la refinación de LM son las siguientes:
1. La entrada del usuario se envía a la política RL (la versión ajustada de la LM).). La política RL genera la respuesta. La respuesta de la política RL y el resultado inicial de la LM se evalúan luego mediante el modelo de recompensas, que proporciona un valor de recompensa escalar en función de la calidad de las respuestas.
2. El proceso anterior continúa en un ciclo de retroalimentación, por lo que el modelo de recompensas sigue concediendo recompensas al mayor número posible de muestras. De esta manera, la política de RL comenzará gradualmente a generar respuestas en un estilo similar al de los humanos.
3. La divergencia (KL) es un método estadístico para evaluar la diferencia entre dos distribuciones de probabilidad.. Se utiliza para comparar la distribución de probabilidad entre las respuestas políticas actuales de RL con la distribución de referencia que refleja las mejores respuestas de estilo humano.
4. Optimización de políticas proximales (PPO) es un algoritmo de aprendizaje por refuerzo que optimiza eficazmente las políticas en entornos complejos que implican espacios de estado/acción de alta dimensión. Es muy útil para refinar la LM porque equilibra la explotación y la exploración durante el entrenamiento. Dado que los agentes de la RLHF necesitan aprender de la retroalimentación humana y la exploración mediante el ensayo y el error, este equilibrio es vital. De esta manera, la PPO ayuda a lograr un aprendizaje sólido y rápido.
Eso es todo, ¡y eso ya es bastante bueno! Así es como se lleva a cabo un proceso completo de entrenamiento en RLHF, que comienza con un proceso previo al entrenamiento y termina con un agente de IA con un Afinación fina minucioso.
¿Cómo se usa RLHF en ChatGPT?
Ahora que sabemos cómo funciona un RLHF, tomemos un ejemplo concreto: analicemos cómo el RLHF está integrado en el proceso de entrenamiento de ChatGPT, el chatbot de IA más popular del mundo.
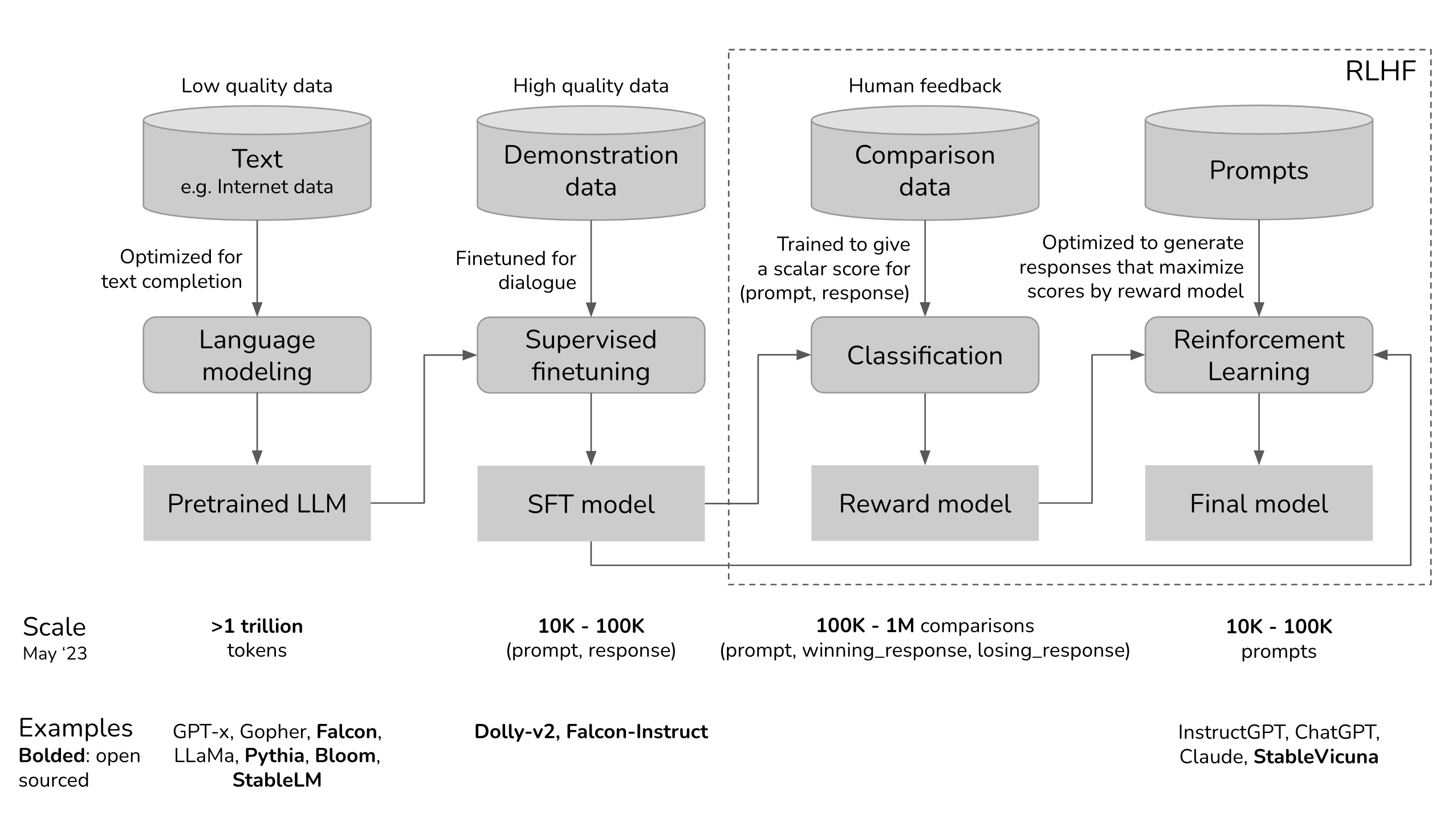
ChatGPT utiliza el marco RLHF para entrenar el modelo lingüístico a fin de proporcionar respuestas apropiadas a un contexto y similares a las de los humanos.. Los tres pasos principales incluidos en su proceso de formación son:
1. Afinación fina Del modelo lingüístico
El proceso comienza con elusar datos de aprendizaje supervisado para refinar el modelo lingüístico inicial. Esto requiere crear un conjunto de datos de conversaciones en el que los entrenadores de IA desempeñen las funciones de asistente y usuario de la IA. En otras palabras, los entrenadores de IA utilizan las sugerencias escritas por el modelo para escribir sus respuestas. De esta manera, el conjunto de datos se construye con una mezcla de texto escrito por el modelo y generado por el humano, lo que significa una recopilación de varias respuestas del modelo.
2. Crear un modelo de recompensas
Tras refinar el modelo inicial, entra en juego el modelo de recompensas. En esta etapa, el modelo de recompensa se crea para reflejar las expectativas humanas. Para ello, anotadores humanos clasifican las respuestas generadas por el modelo según las preferencias humanas, la calidad y otros factores.
Las clasificaciones se utilizan para entrenar el segundo modelo de aprendizaje automático, llamado modelo de recompensa. Este modelo es capaz de predecir hasta qué punto la función de recompensa de una respuesta se alinea con las preferencias humanas.
3. Mejorar el modelo con el aprendizaje por refuerzo
Una vez que el modelo de recompensa esté listo, el último paso es mejorar los principales resultados del modelo lingüístico y el modelo mediante el aprendizaje por refuerzo. En este caso, la optimización de políticas proximales (PPO) ayuda al LLM a generar respuestas con puntajes más altos de acuerdo con el modelo de recompensas.
Los tres pasos anteriores son iterativos, lo que significa que se realizan en un bucle para mejorar el rendimiento y la precisión de todo el modelo.
¿Cuáles son los desafíos de usar RLHF en ChatGPT?
Si bien el RLHF de ChatGPT ha mejorado significativamente la eficiencia de la respuesta, presenta algunos desafíos, como los siguientes:
- Abordar las diferentes preferencias humanas. Cada ser humano tiene preferencias diferentes. Como resultado, es difícil definir un modelo de recompensa que satisfaga todos los tipos de preferencias.
- Trabajo humano para la moderación, como la «retroalimentación humana». Depender del trabajo humano para optimizar las respuestas es costoso y lento (y a veces poco ético).
- Usar el lenguaje de manera consistente. Se requiere una atención especial para garantizar la coherencia del idioma (inglés, francés, español, malgache, etc.) y, al mismo tiempo, mejorar las respuestas.
Ventajas del RLHF
De todas las discusiones realizadas hasta ahora, es obvio que la RLHF desempeña un papel de liderazgo en la optimización de las aplicaciones de inteligencia artificial. Algunos de los principales beneficios que ofrece son:
- Adaptabilidad: El RLHF ofrece una estrategia de aprendizaje dinámica que se adapta en función de la retroalimentación. Esto les ayuda a adaptar su comportamiento en función de los comentarios e interacciones en tiempo real y a adaptarse bien a una amplia gama de tareas.
- Mejora continua: Los modelos basados en el RLHF son capaces de mejorar continuamente en función de las interacciones de los usuarios y de más comentarios. De esta forma, seguirán mejorando su rendimiento a lo largo del tiempo.
- Reducir el sesgo del modelo: El RLHF reduce el sesgo del modelo al incluir la retroalimentación humana, lo que minimiza las preocupaciones de sesgo o generalización excesiva del modelo.
- Seguridad mejorada : La RLHF hace que las aplicaciones de IA sean seguras porque el circuito de retroalimentación humana prohíbe que los sistemas de IA activen un comportamiento inapropiado.
En resumen, El RLHF es la clave para optimizar los sistemas de IA y hacer que funcionen de una manera que esté en línea con los valores e intenciones humanos.
Retos y límites de la RLHF
El entusiasmo por la RLHF también viene acompañado de una serie de desafíos y limitaciones. Algunos de los principales desafíos y limitaciones de la RLHF son los siguientes:
- Prejuicio humano : Lo más probable es que el modelo RLHF pueda abordar los prejuicios humanos, ya que los evaluadores humanos pueden influir involuntariamente en sus sesgos en las respuestas.
- Escalabilidad : Dado que la RLHF depende en gran medida de la retroalimentación humana, es difícil escalar el modelo para tareas más grandes debido a la gran demanda de tiempo y recursos.
- Dependencia del factor humano : La precisión del modelo RLHF está influenciada por el factor humano. Como resultado, las respuestas humanas ineficientes, especialmente en las consultas avanzadas, pueden comprometer el rendimiento del modelo.
- Formulación de la pregunta : La calidad de la respuesta del modelo depende principalmente de la redacción de la pregunta. Si la redacción de la pregunta no está clara, es posible que el modelo aún no pueda responder adecuadamente a pesar de las amplias limitaciones del RLHF.
Conclusión: ¿Cuál es el futuro de RLHF?
Sin lugar a dudas, el «aprendizaje por refuerzo a partir de la retroalimentación humana» (RLHF) promete un futuro brillante y está listo para seguir desempeñando un papel importante en la industria de la IA. Con el objetivo principal de disponer de una IA que imite los comportamientos y mecanismos humanos, la RLHF seguirá mejorando este aspecto a través de técnicas nuevas y avanzadas. Además, se prestará cada vez más atención a resolver sus limitaciones y garantizar un equilibrio entre las capacidades de la IA y las preocupaciones éticas. En Innovatiana, esperamos contribuir a los procesos de desarrollo relacionados con la RLHF: nuestros moderadores están especializados, están acostumbrados a las herramientas y son capaces de apoyarlo en sus tareas de evaluación de IA más complejas.



