Comment créer et annoter un dataset pour l'IA ? Tout ce que vous devez savoir

Introduction : qu'est-ce qu'un jeu de données, et quelle importance pour l'intelligence artificielle ?
Aujourd'hui, nous allons aborder une étape essentielle du processus de développement mais souvent sous-estimée : la création et la collecte de datasets pour l'Intelligence Artificielle (IA). Que vous soyez un professionnel de la donnée ou un fan de l'IA, ce guide vise à vous fournir des conseils pratiques pour construire un dataset solide et fiable.
Le Machine Learning (ML), une branche essentielle de l'Intelligence Artificielle, dépend fortement de la qualité des datasets initiaux utilisés dans les cycles de développement. Avoir suffisamment de données adaptées pour des applications spécifiques en Machine Learning est fondamental. Cet article vous donnera un aperçu des meilleures pratiques de création de datasets pour le Machine Learning et de leur utilisation pour des tâches spécifiques. Vous comprendrez ce qui est nécessaire pour collecter et générer les données appropriées pour chaque algorithme de Machine Learning.
💡 Souvenez-vous, l'IA repose sur 3 piliers : les Datasets, la Puissance de Calcul et les Modèles. Découvrez en suivant ce lien comment évaluer un modèle de Machine Learning.
1. Comprendre l'importance d'un dataset de qualité pour l'IA
Tout projet d'IA dépend fortement de la qualité des données sur lesquelles le modèle sous-jacent est entraîné. Un dataset bien conçu est à l'IA ce que de bons ingrédients sont à un chef : essentiel pour un résultat exceptionnel. Un dataset pour le Machine Learning est en fait un ensemble de données utilisé pour entraîner un modèle de ML. La création d'un bon dataset est donc une étape critique dans le processus d'entrainement et d'évaluation des modèles de ML. Il est important de comprendre comment générer des données pour le Machine Learning et de déterminer quelles données sont nécessaires pour créer un dataset complet et efficace.
Dans la pratique, un dataset c'est :
- Une collection de données cohérentes pouvant prendre divers formats (textes, nombres, images, vidéos, etc.).
- Un ensemble où chaque valeur est associée à un attribut et une observation, par exemple, des données sur des individus avec des attributs comme leur âge, leur poids, leur adresse, etc.
- Un ensemble cohérent, ayant fait l'objet de contrôles pour s'assurer de la validité des sources de données, pour éviter de travailler avec des données inexactes, biaisés, ou ne respectant pas les règles liées à la propriété intellectuelle.
Un dataset, ce n'est pas :
- Un simple assemblage aléatoire de données : les datasets doivent être structurés et organisés de manière logique et cohérente.
- Exempt de contrôle qualité : la vérification et la validation des données sont essentielles pour assurer leur fiabilité.
- Toujours utilisable dans son état original : souvent, un nettoyage et une transformation des données sont nécessaires avant leur utilisation.
- Une source infaillible : même les meilleurs datasets peuvent contenir des erreurs, des problèmes de qualité, ou des biais qui nécessitent une analyse et une correction.
- Un ensemble statique : un bon dataset peut nécessiter des mises à jour et des révisions pour rester pertinent et utile.
La qualité et la taille d'un dataset jouent un rôle déterminant dans la précision et la performance du modèle IA. En général, plus un modèle a accès à des données fiables et de qualité, meilleures seront ses performances. Cependant, il est important de trouver un équilibre entre la quantité de données stockées pour le traitement et les ressources humaines et informatiques nécessaires pour les traiter.

2. Définir l'objectif de votre dataset
Avant de vous lancer dans la constitution d'un dataset, c'est-à-dire avant de plonger dans la phase laborieuse de collecte de données, clarifiez l'objectif de votre IA. Que cherchez-vous à accomplir ? Cette définition guidera vos choix en termes de types et de volume de données nécessaires.
Obtenir des données : faut-il utiliser un dataset existant, des données synthétiques ou collecter les données ?
Lorsqu'on initie un développement IA sans posséder de données, il est utile de se tourner vers les datasets open source publics. Ces datasets, provenant des communautés Open Source ou d'organisations publiques, offrent un large éventail d'informations utiles à certains cas d'usage.
Parfois, les Data Scientists se tournent vers les données synthétiques. De quoi s'agit-il ? Il s'agit de données générées artificiellement, souvent à l'aide d'algorithmes, pour simuler des données réelles. Elles sont utilisées dans divers domaines pour l'entraînement et la validation de modèles lorsque les données réelles sont insuffisantes, coûteuses à obtenir, ou pour préserver la confidentialité. Ces données imitent les caractéristiques statistiques des données réelles, permettant ainsi de tester et d'affiner les modèles d'IA dans un environnement contrôlé. Toutefois, il est préférable d'utiliser des données réelles pour éviter un écart entre les caractéristiques des données synthétiques et des données réelles (ces écarts étant aussi appelés "distorsions"). Bien que pratiques et relativement simples à obtenir, les données synthétiques peuvent rendre des modèles de Machine Learning moins précis ou moins performants lorsqu'ils sont appliqués à de vraies situations.
De l'importance de la qualité des données...
Bien que les datasets publics ou les données synthétiques puissent apporter des insights précieux, la collecte de vos propres données, adaptées à vos besoins spécifiques, est souvent plus avantageuse. Quelle que soit la source de vos données, il existe une constante : la qualité des données et la nécessité de les étiqueter correctement pour leur apporter une couche d'information sémantique sont des aspects importants à considérer pour vos travaux dans le domaine de l'IA.
-hand-innv.png)
3. La collecte des données : une étape stratégique du processus de développement IA
La collecte des données d'entraînement est une étape critique dans le processus de développement IA. Plus vous serez minutieux et rigoureux durant cette étape, plus l'algorithme de ML sera efficace. Ainsi, la collecte d'un maximum de données pertinentes, tout en équilibrant leur diversité, leur représentativité et vos capacités matérielles et logicielles, est un travail de premier plan, quoique souvent négligé.
Lors de la construction et de l'optimisation de vos modèles de Machine Learning, votre stratégie devrait être d'utiliser vos propres données. Ces données sont naturellement adaptées à vos besoins spécifiques et représentent le meilleur moyen d'optimiser votre modèle pour les types de données qu'il rencontrera dans des situations réelles. Selon l'ancienneté de votre entreprise, vous devriez disposer de ces données en interne, dans des Data Lakes dans le meilleur des cas, ou dans diverses bases de données structurées et non-structurées collectées au fil des ans.
Si obtenir des données en interne est l'une des meilleures approches, contrairement aux multinationales, les plus petites structures (notamment les startups), n'ont pas toujours à leur disposition des ensembles de données construits par des milliers de collaborateurs. Il faut donc être inventif, et imaginer d'autres moyens d'obtenir les données. Voici deux méthodes qui ont fait leurs preuves :
Le "crawling" et le "scrapping"
- Le "crawling" consiste à parcourir un grand nombre de pages web qui pourraient vous intéresser.
- Le "scrapping" est le processus de collecte de données à partir de ces pages.
Ces tâches, qui peuvent varier en complexité, permettent de recueillir différents types de datasets comme du texte brut, des textes introductifs pour des modèles spécifiques, du texte avec métadonnées pour des modèles de classification, du texte multilingue pour des modèles de traduction, et des images avec légendes pour l'entraînement de modèles de classification d'images ou de conversion d'image en texte.
Utiliser des datasets diffusés par les chercheurs
Il est probable que d'autres chercheurs se soient déjà intéressés à des problématiques similaires à la vôtre. Dans ce cas, il est possible de trouver et d'utiliser les datasets qu'ils ont créés ou employés. Si ces datasets sont disponibles en libre accès sur une plateforme open source, vous pouvez les récupérer directement. Sinon, n'hésitez pas à contacter les chercheurs pour voir s'ils acceptent de partager leurs données.
4. Nettoyage et préparation des données
Cette étape consiste à contrôler votre dataset pour en éliminer les erreurs, les doublons, et le structurer. Un dataset propre est indispensable pour un apprentissage efficace de l'IA.
Formater, nettoyer et réduire les données
Pour créer un dataset de qualité, il y a trois étapes clés :
- Le formatage des données, qui consiste à réaliser des contrôles pour assurer la cohérence des données. Par exemple, est-ce que le format des dates dans vos données est identique pour chaque entrée ?
- Le nettoyage des données, qui implique l'élimination de valeurs manquantes, erronées ou peu représentatives pour améliorer la précision de l'algorithme.
- La réduction des données, qui consiste à diminuer la taille du dataset en retirant les informations non pertinentes ou les moins pertinentes.
Ces étapes sont essentielles pour obtenir un dataset utile et optimisé en Machine Learning.
Préparer les données
Les datasets ont souvent des défauts qui peuvent affecter la précision et la performance des modèles de Machine Learning. Parmi les problèmes courants, on trouve le déséquilibre des classes (une classe prédominante sur une autre), les données manquantes (compromettant la précision et la généralisation du modèle), le "bruit" (informations incorrectes ou non pertinentes, telles que des images trop floues) et les valeurs aberrantes (très élevées ou très basses, faussant les résultats). Pour remédier à ces problèmes, les Data Scientists doivent nettoyer et préparer les données en amont pour assurer la fiabilité et l'efficacité du modèle.
Augmentation des données
La "data augmentation" est une technique clé en apprentissage automatique pour enrichir un ensemble de données. Elle consiste à créer de nouvelles données à partir des données existantes par diverses transformations. Par exemple, dans le traitement d'images, cela peut impliquer de modifier l'éclairage, de faire pivoter ou de zoomer sur une image. Cette méthode augmente la diversité des données, permettant à un modèle d'IA d'apprendre à partir d'exemples plus variés, et améliore ainsi sa capacité à généraliser à de nouvelles situations.
L'augmentation des jeux de données est surtout une façon astucieuse d'augmenter la quantité de données d'entraînement sans devoir collecter de nouvelles données réelles.
5. L'annotation : le langage de vos données
Annoter un dataset, c'est attribuer des étiquettes aux données pour les rendre interprétables par l'IA, une opération qui requiert rigueur et précision car elle influence directement la prise de décision de l'algorithme, c'est-à-dire la manière dont l'IA traitera les données. Cette tâche peut être grandement facilitée par l'utilisation de plateformes d'annotation dédiées comme Kili, V7 Labs ou Label Studio. Ces outils offrent des interfaces intuitives et des fonctionnalités avancées pour une annotation précise, contribuant ainsi à l'efficacité et à l'exactitude des modèles de Machine Learning.
L'annotation des données pour l'IA implique généralement une expertise humaine pour étiqueter précisément les données, une étape essentielle pour l'entraînement des modèles. Plus vos jeux de données sont complexes, spécifiques ou demande une formation à des règles ou mécanismes particuliers, plus l'expertise humaine de Data Labelers devient nécessaire. Avec l'avancée technologique, les capacités d'annotation sont de plus en plus complétées par des outils automatisés. Ces outils utilisent des algorithmes pour pré-annoter les données, réduisant ainsi le temps et l'effort requis pour l'annotation manuelle, tout en nécessitant une vérification et une validation humaines pour assurer la précision et la pertinence des étiquettes attribuées. Les dernières mises à jour des plateformes de labellisation du marché offrent des fonctionnalités avancées de sélection automatique ou de revue, qui rendent le travail d'annotation de moins en moins laborieux pour les annotateurs. Grâce à ces outils, le Data Labeling devient une profession à part entière.
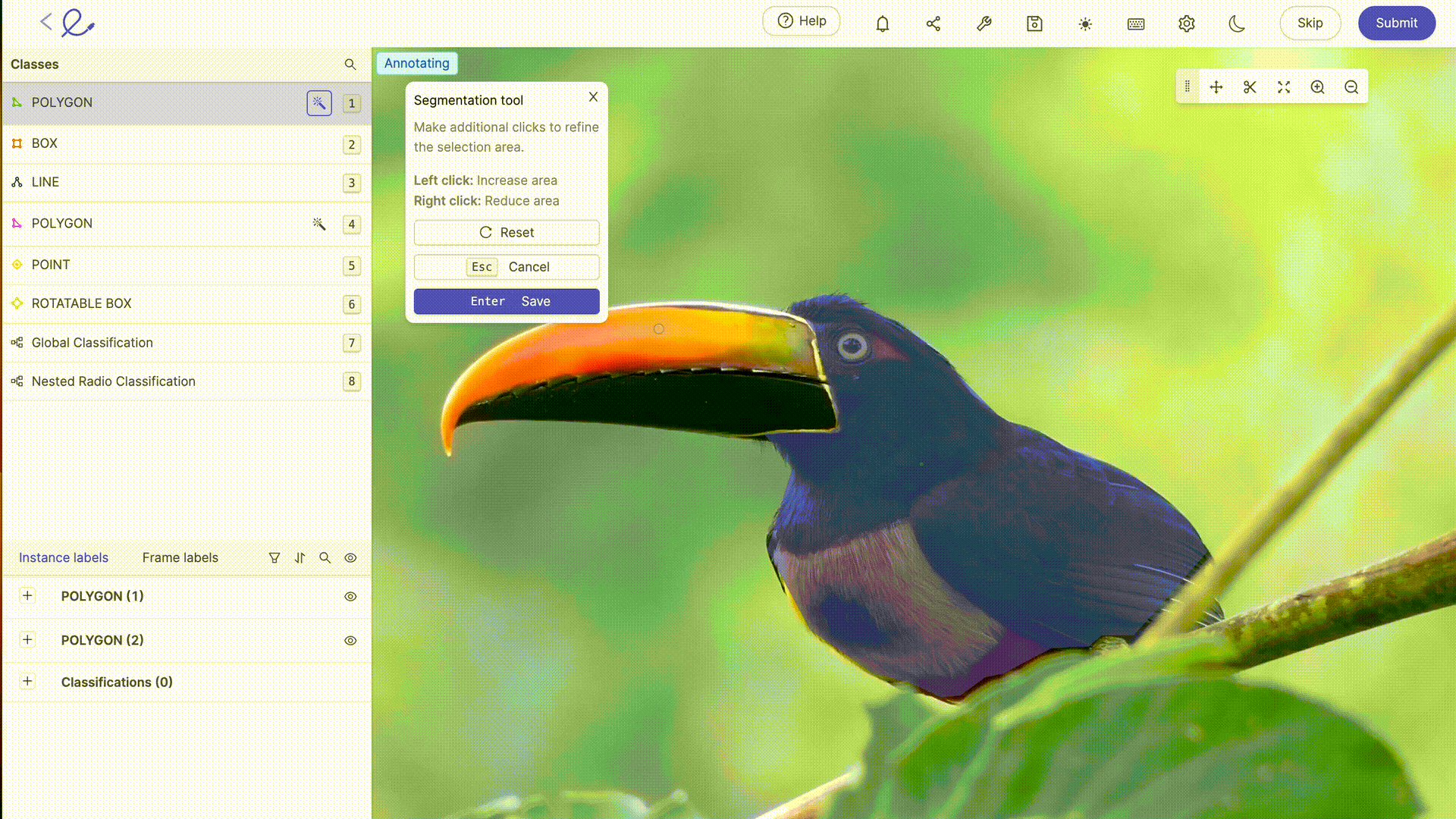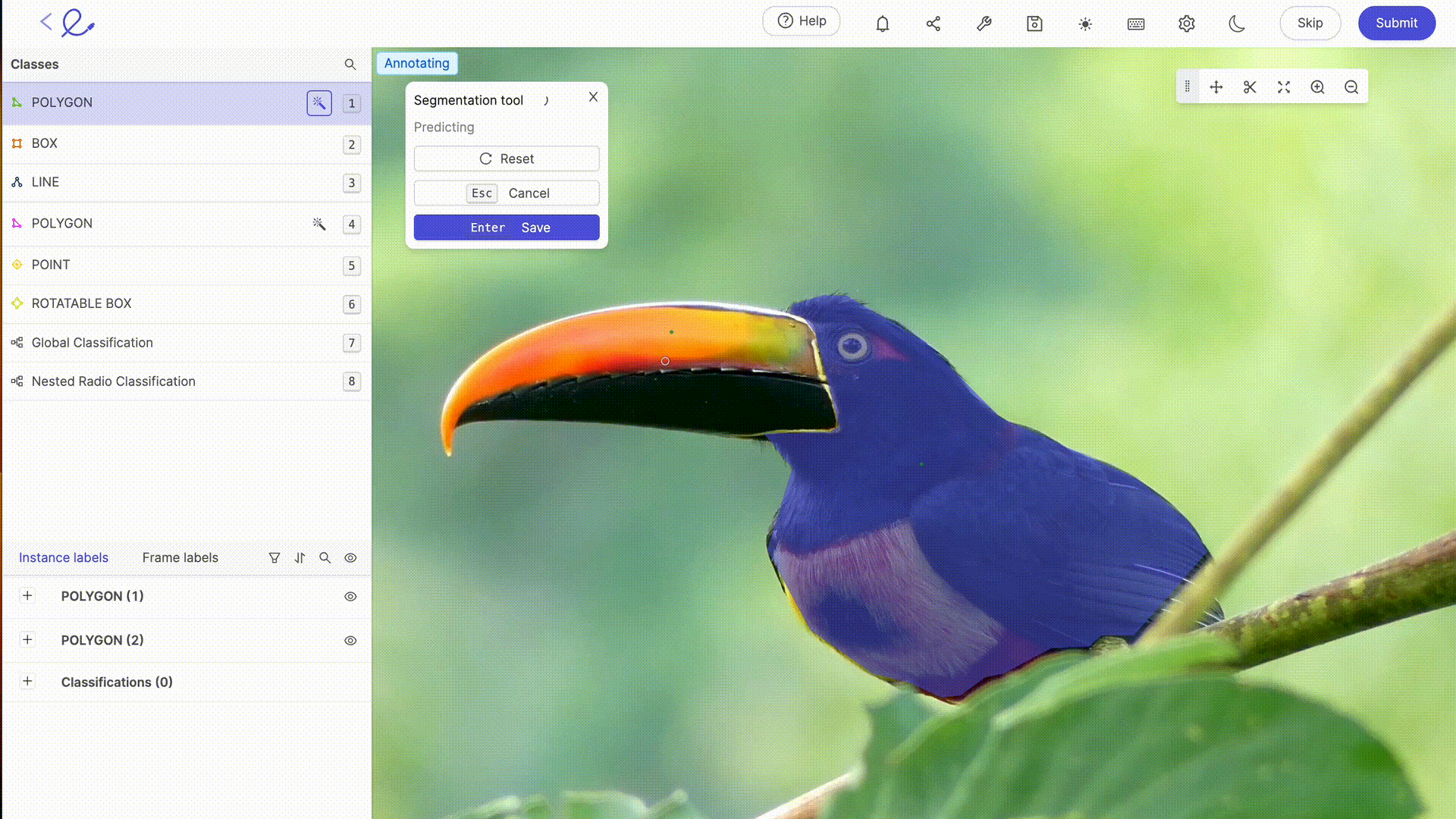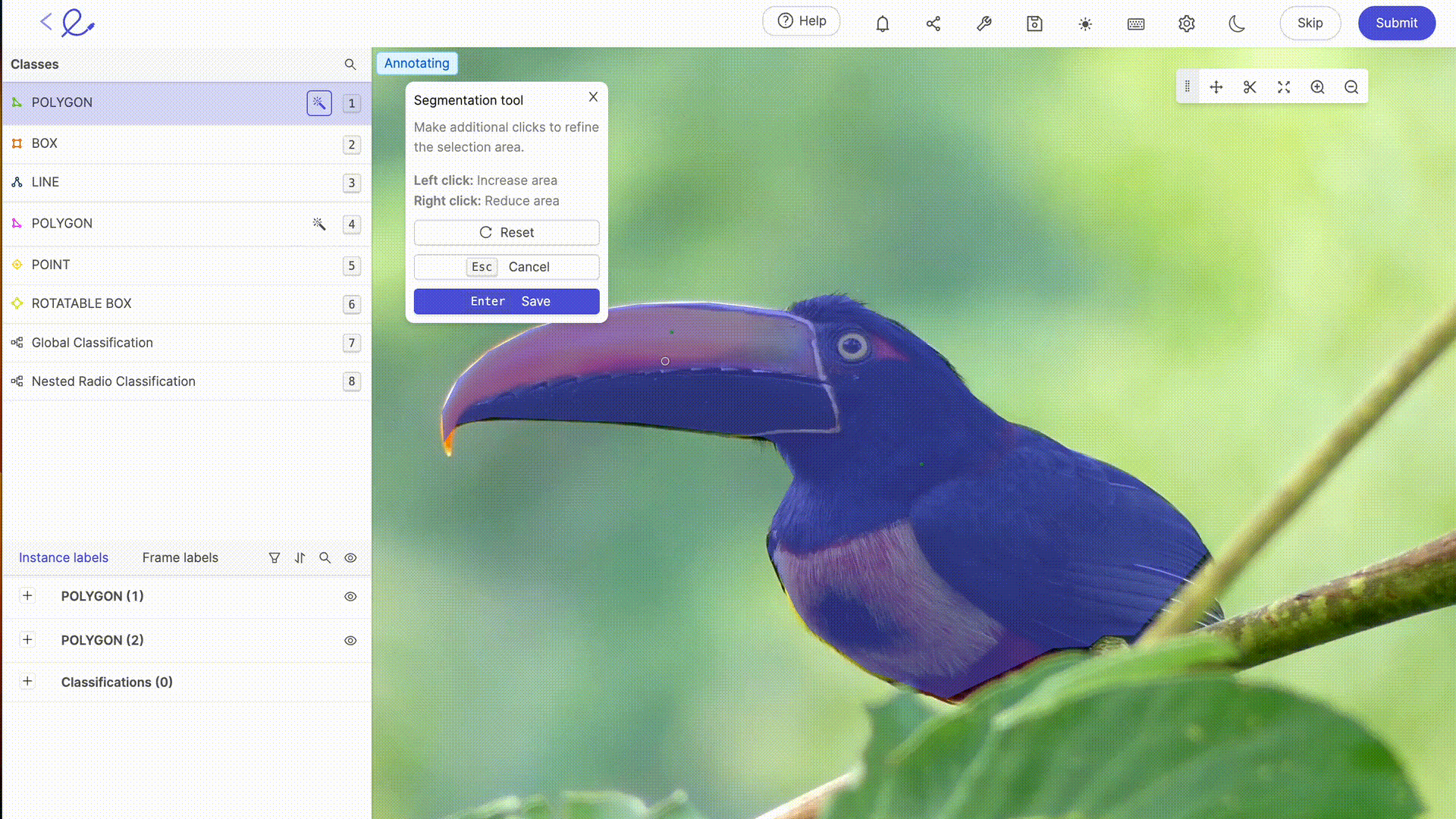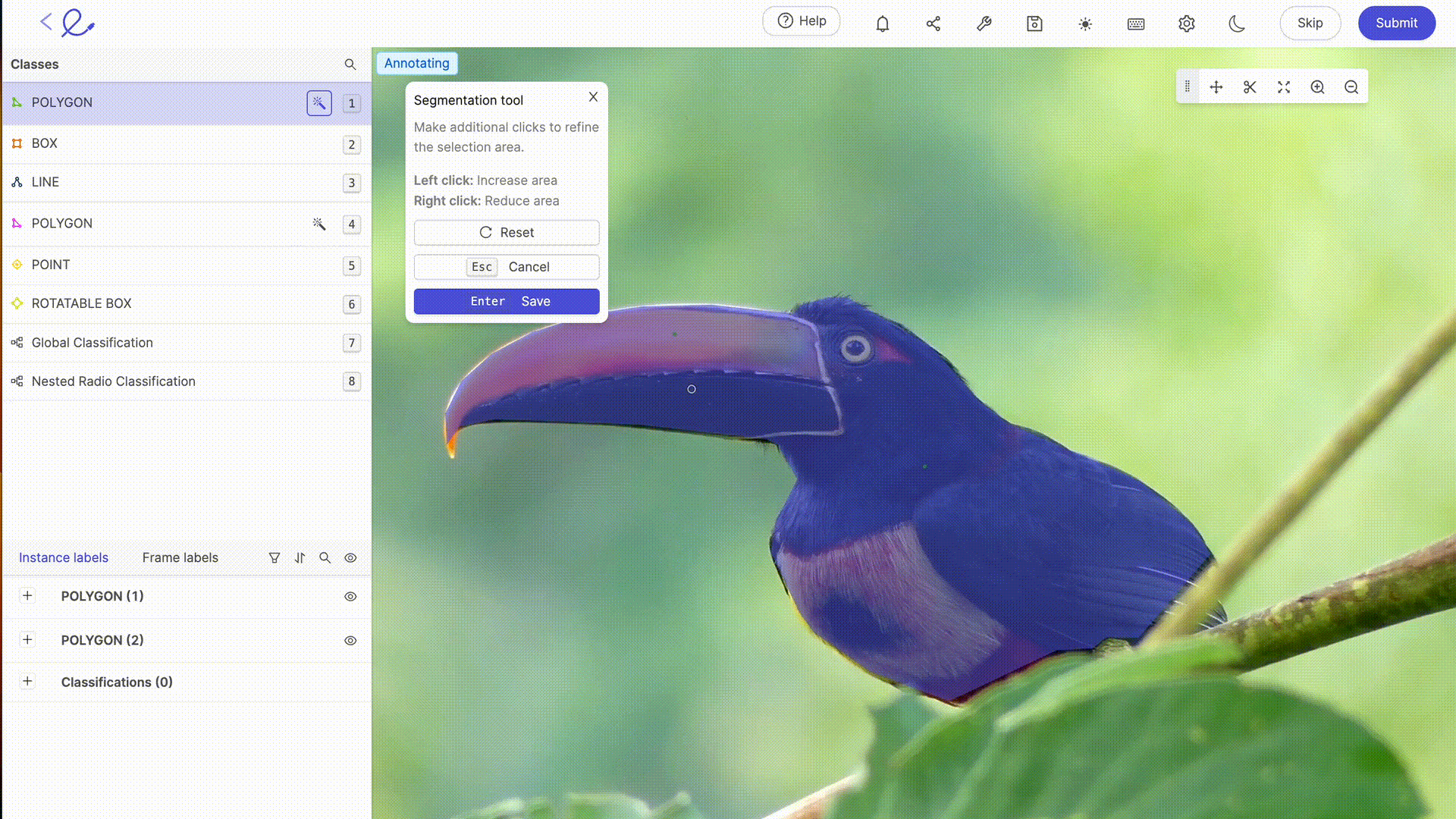
6. Optimiser un dataset : tester et itérer
Après avoir collecté et annoté un volume conséquent de données, la suite logique consiste à tester votre dataset pour évaluer les performances de votre modèle d'IA. Dès lors, il s'agit d'une approche itérative, et vous allez devoir revenir sur les étapes précédentes pour améliorer la qualité des données ou des labels produits.
Pour évaluer la qualité d'un dataset, voici quelques questions que vous pouvez vous poser :
- Les données sont-elles représentatives de la population ou du phénomène étudié ?
- La collecte des données a-t-elle été effectuée de manière éthique et légale ?
- Les données sont-elles suffisamment variées pour couvrir différents cas d'utilisation ?
- La qualité des données a-t-elle été affectée durant le cycle de collecte et d'annotation, par exemple pendant le processus de transfert ou de stockage ?
- Les données contiennent-elles des biais ou des erreurs qui pourraient influencer les résultats du modèle ?
- Existe-t-il des dépendances ou des corrélations inattendues entre les variables ?
Ces questions vous aideront à évaluer de manière approfondie la qualité de vos données pour garantir l'efficacité et la fiabilité de vos modèles IA.
En conclusion...
Nous arrivons à la fin de cet article. Vous l'aurez compris : la création et l'annotation d'un dataset sont des étapes fondamentales dans le développement de solutions d'IA. En suivant nos conseils, nous espérons que vous pourrez poser les bases solides nécessaires pour entraîner des modèles d'IA performants et fiables. Bonne chance dans vos expérimentations et projets, et n'oubliez pas : un bon dataset est la clé de la réussite de votre projet d'IA !
Pour finir, nous avons pensé à vous en rassemblant une liste des 10 meilleurs sites pour trouver des datasets destinés au Machine Learning. Si cette liste vous semble incomplète ou si vous avez des besoins plus spécifiques en termes de données, notre équipe est à votre disposition pour vous assister dans la collecte et l'annotation de datasets personnalisés et de haute qualité. N'hésitez pas à faire appel à nos services pour affiner vos projets de Machine Learning.
Notre top 10 des sites où trouver des datasets pour le Machine Learning
- Kaggle dataset : 🔗 https://www.kaggle.com/datasets
- Hugging Face datasets : 🔗 https://huggingface.co/docs/datasets/index
- Amazon Datasets : 🔗 https://registry.opendata.aws
- Moteur de recherche de datasets de Google : 🔗 https://datasetsearch.research.google.com
- Plateforme de diffusion de données publiques de l'État français : 🔗 https://data.gouv.fr
- Portail de données ouvertes de l'Union Européenne : 🔗 http://data.europa.eu/euodp
- Datasets de la communauté Reddit : 🔗 https://www.reddit.com/r/datasets
- UCI Machine Learning Repository : 🔗 https://archive.ics.uci.edu
- Site de l'INSEE : 🔗 https://www.insee.fr/fr/information/2410988
(BONUS) - SDSC, plateforme de mise à disposition de données annotées pour les cas d'usage médicaux : 🔗 https://www.surgicalvideo.io/



