How hard is it to create a dataset for AI?

Artificial intelligence models rely on an essential resource: datasets. These data sets, used to train algorithms, directly influence the performance and accuracy of AI systems.
However, behind the apparent simplicity of the concept, creating a dataset adapted to the needs of a machine learning model proves to be a much more complex process than it seems.
💡 Between the collection of data, their annotation, their cleaning and the possible management of biases, each stage requires significant resources and specific expertise. So why is it so difficult to design a quality dataset for AI?
Why is a dataset essential for AI?
Artificial intelligence is based on Machine Learning, a process in which a model analyzes (more or less) large amounts of data to identify patterns and deliver predictions. Without a dataset, an AI model cannot learn or improve. The same goes for the quality of the data used: a well-constructed dataset makes it possible to train an effective model, while an incomplete or poorly structured dataset risks causing biases and errors.
Datasets thus serve as AI raw material. They allow learning algorithms to identify trends and generalize their knowledge to new cases. For example, an image recognition model will not be able to correctly identify a cat if the underlying dataset contains only images of dogs. Diversity and representativeness of data are therefore decisive elements in guaranteeing reliable results.
Beyond the simple acquisition of information, a well-designed dataset also plays a role in the adaptability of the model. AI models need to evolve over time to adapt to new trends and contexts. This means integrating new data on a regular basis and adjusting learning accordingly. A dynamic dataset, updated and maintained with care, therefore makes it possible to ensure the relevance and effectiveness of a model over the long term.
So you get it, I believe: performance of an artificial intelligence model depends largely on the quality of the dataset used for its training. A poorly constructed dataset can distort learning, introduce biases, and limit the ability of the model to generalize its knowledge. Several criteria are used to assess the reliability of a dataset - see below:
1. Data accuracy
A quality dataset should contain accurate and verified data. Any errors in the values, whether incorrect, poorly formatted, or ambiguous information, may interfere with model learning. Rigor in collecting, verifying and validating data is therefore essential to ensure reliable results.
2. Data diversity
An AI model must be able to adapt to a variety of situations. To do this, the dataset must reflect the diversity of the real world. For example, a model of facial recognition should be trained with images of people of different ages, genders, and backgrounds to prevent it from working properly only on a limited profile of individuals.
3. Representativeness of the dataset
Beyond diversity, a dataset must be representative of the population or problem that it seeks to model. If certain categories of data are over-represented or under-represented, the model risks giving disproportionate importance to certain characteristics and producing biased results.
4. Sufficient data volume
Machine learning is based on the analysis of large amounts of data. The larger a dataset is, the more likely a model is to learn to detect trends effectively. However, quantity alone is not enough: a large dataset that is poorly annotated or contains redundant data will be less effective than a smaller but better structured dataset.
5. Absence of bias
Biases are one of the main challenges in building a dataset. They may be introduced unintentionally during data collection or may result from poor representativeness of the dataset. For example, an automatic language processing model trained only on texts written by a specific category of speakers may misunderstand other forms of language. Identifying and limiting these biases is essential to ensure the fairness and accuracy of the model.
6. Quality of the annotation(s)
Data annotation plays a key role, especially in supervised tasks. Inaccurate or inconsistent annotation leads to learning errors. To ensure good annotation quality, it is often necessary to have trained annotators and rigorous validation processes.
How to collect data adapted to the needs of an AI model?
Data collection is a fundamental step in implementing an artificial intelligence model. Without relevant, well-structured data, even the best algorithm won't be able to provide actionable results. This phase involves several strategic choices: Where to find the data, How to collect them And what are the ethical and legal issues to consider.
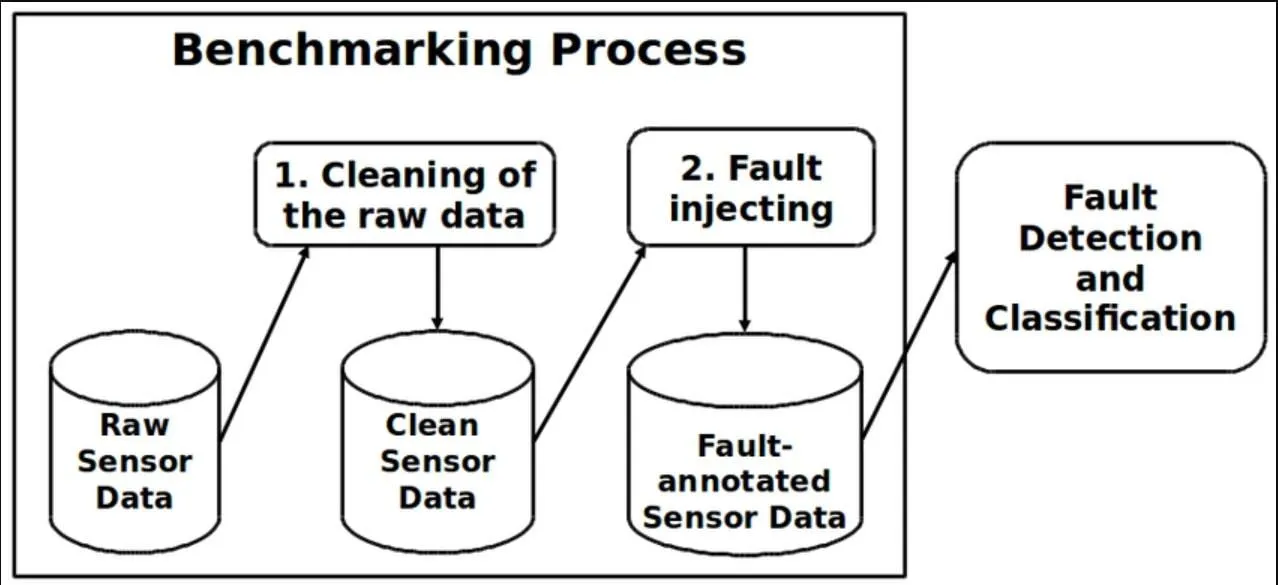
1. What are the main data sources?
There are several ways to get data to train an AI model. The choice depends on the field of application, technical constraints and quality requirements.
- Public data : Many open source datasets are available via platforms such as Kaggle, Hugging Face or Google Dataset Search (or even Innovatiana: Open Datasets). These sources allow access to a variety of data without having to collect them yourself.
- Proprietary data : Some companies have their own databases, generated from their interactions with users (logs, transactions, histories, etc.).
- Synthetic data : When collecting real data is complex, it is possible to generate artificial data through AI models that can mimic existing data trends.
- Scraping and extracting web : Data accessible online can be extracted via web scraping tools, subject to compliance with the terms of use of the websites.
- Sensors and IoT : For some applications (health, industry, mobility), the data comes directly from connected sensors or smart objects that record various parameters in real time.
2. What are the data collection methods?
Once the source has been identified, the collection can be carried out in various ways:
- Manual collection : In some cases, data must be entered and annotated manually, especially in areas requiring specific expertise (medical, legal, etc.).
- Crowdsourcing : Platforms like Amazon Mechanical Turk make it possible to collect and annotate data by mobilizing annotators on a large scale (but pay attention to quality)
- Experts : companies like Innovatiana or Sama implement complex annotation processes to annotate data at scale. These processes involve Data Labeling experts and the professions of their clients (doctors, lawyers, etc.).
- Automation and APIs : Some databases offer API access to retrieve data in a programmed and structured manner.
- Acquisition through partners : Collaborations with other companies or institutions can make it possible to obtain specific data sets that are difficult to collect alone.
3. What are the ethical and legal issues?
Data collection for AI raises several issues, especially when it comes to privacy and regulatory compliance.
- Protection of personal data : When a dataset contains sensitive information (names, addresses, user behaviors), it is essential to comply with current regulations such as the GDPR in Europe or the Privacy Act in Canada.
- User consent : If the data comes from individuals, it is often necessary to obtain their explicit consent to collect and use it.
- Bias and discrimination : Biased collection can generate models that reproduce social inequalities or involuntary discrimination. Checking the diversity and representativeness of data is therefore a major challenge.
- Copyright and usage restrictions : Some data, especially those extracted from the web, are protected by licenses and cannot be used freely.
Why is data annotation a complex and expensive step in implementing an AI model?
Data annotation is an essential step in the development of an artificial intelligence model, especially in supervised learning. It consists in associating each data with a tag or metadata allowing the model to learn to identify patterns and to generalize its predictions.
💡 While this phase is critical to ensure accurate results, it represents one of the most complex and expensive challenges in implementing an AI model.
1. What does data annotation consist of?
Annotation is the process by which raw data (images, text, text, video, audio, etc.) is enriched with information that can be used by a machine learning algorithm. Here are some examples of annotation based on data type:
- Text : Assigning categories to sentences (spam or non-spam), identifying named entities (people, places, organizations), syntactic segmentation.
- Images and videos : Object detection, semantic segmentation, facial recognition, motion tracking.
- Audio data : Transcription of words, classification of sounds, detection of emotions.
Annotation can be done manually by experts or non-specialized annotators, but also semi-automatically using annotation assistance algorithms.
2. Why is annotation critical to Machine Learning?
Without annotation, a supervised model cannot learn properly. It needs labeled examples to understand the relationship between inputs (raw data) and expected outputs (predictions). A well-annotated dataset makes it possible to improve:
- The precision of the models : The more rigorously a dataset is annotated, the more efficient the algorithm will be.
- Generalization : A varied and balanced annotation allows the model to better adapt to real cases, beyond the data seen during training.
- Interpretability : A model trained on well-annotated data is easier to audit and correct in case of errors.
3. What are the main constraints associated with annotation?
Annotating data is a particularly time-consuming and resource-intensive task for several reasons:
- Tedious manual work : Even with automation tools, much of the work is still manual. Annotating images or text can take hours or even days, depending on the size of the dataset.
- A need for expertise : Some types of annotation require specific skills. For example, annotating medical images or legal documents requires the intervention of experts in the field, which increases costs.
- Risks of errors and inconsistencies : Since the annotation is often carried out by several people, discrepancies may appear. It is therefore necessary to set up validation and proofreading processes to guarantee the quality of the annotations.
- A high cost : The recruitment of qualified annotators and the use of specialized platforms involve significant costs. Some companies outsource this task to crowdsourcing platforms (Amazon Mechanical Turk, Scale AI, etc.), but the quality of the annotations can then vary.
- Constant updating required : AI models evolve over time and often require updates to their dataset. This involves a continuous annotation effort to integrate new data and avoid model obsolescence.
4. Can data annotation be automated?
Faced with the constraints of manual annotation, several automation solutions have been developed:
- Assisted annotation models : Some algorithms are capable of proposing preliminary annotations that human annotators then validate.
- Semi-supervised annotation : The AI learns to annotate gradually thanks to a small number of labeled examples.
- Active learning : The model interacts with the annotators and selects the most relevant data to be annotated first.
👉 We believe that for multiple reasons (avoiding bias, ethical considerations, regulation, etc.), there will ALWAYS be a manual component to building a dataset for AI!
What are the challenges of cleaning and preparing data for an AI model?
The quality of the data used to train an artificial intelligence model directly influences its performance. A raw dataset often contains errors, inconsistencies, and imbalances that can skew learning. The data cleaning and preparation phase is therefore an essential but complex step, requiring careful processing to ensure usable results.
1. How to identify and manage noisy data?
Noisy data corresponds to incorrect, inaccurate, or outlier information that can interfere with the training of the model. They can come from several sources: human errors, faulty sensors, data transmission problems, etc.
- Detecting outliers : Statistical analysis makes it possible to identify unusual data (for example, an age of 200 years in a demographic dataset).
- Filtering and correction : Depending on the context, noisy data can be corrected or removed to prevent it from negatively affecting the model.
A noisy dataset can reduce the ability of a model to generalize properly. It is therefore essential to define detection and purification strategies adapted to each type of data.
2. Why is it important to remove duplicates?
The presence of duplicates distorts the statistics and can lead to a bias in learning the model. Duplicates can be identical (exact copy of a data) or almost identical (very similar data with minor variations).
- Impact on performance : A dataset containing many duplicates can distort training by giving disproportionate importance to certain data.
- Detection methods : The analysis of unique values, textual similarities or the use of clustering algorithms make it possible to identify and remove these duplicates.
Effective cleaning ensures that each piece of data brings useful, non-redundant information to the model.
3. Why standardize and standardize data?
Datasets often contain values measured in different units or with significant differences. Normalization is necessary to prevent certain characteristics from dominating model learning.
- Normalization : Transformation of values to bring them back into a defined interval (example: scaling between 0 and 1).
- Standardization : Centering data around a mean with a unit variance, useful when the data follows a Gaussian distribution.
Without standardization, a model may favor certain variables only because they have higher numerical values, not because they are actually relevant.
4. How do you balance classes in a dataset?
Class balancing is an important issue when a dataset contains an unequal distribution of categories. For example, in a classification of medical images, if 95% of the images correspond to healthy cases and only 5% to pathological cases, the model is likely to learn to systematically predict the majority class.
- Undersampling : Reduction in the number of examples in the majority class to rebalance the distribution.
- Oversampling : Artificial generation of new data to increase the presence of under-represented classes.
- Use of advanced techniques : Methods like SMOTE (Synthetic Minority Over-sampling Technique) make it possible to generate synthetic examples to improve the balance of the dataset.
A balanced dataset ensures that the model learns fairly and does not favor one category at the expense of others.
5. How do I deal with missing values?
Real datasets often contain missing values, which can be a problem for some algorithms. There are several strategies for dealing with them:
- Deleting incomplete data : If a variable is missing in too many cases, it may be appropriate to exclude it from the dataset.
- Imputation of values : Replacing missing values with means, medians, or predictive values based on other variables.
- Use of algorithms that are tolerant of missing values : Some models, like decision trees, can work with incomplete data.
The choice of method depends on the volume of missing data and their impact on learning.
What are the challenges of cleaning and preparing data for an artificial intelligence model?
A raw dataset often contains errors, inconsistencies, and imbalances that can interfere with learning an AI model. Before being used, it needs to be cleaned and structured to ensure better quality predictions. This step, while technical and time-consuming, is essential to prevent the model from being influenced by inaccurate or poorly distributed data. Several aspects must be taken into account to optimize data preparation.
Detection and correction of noisy data
Noisy data is erroneous, inconsistent, or outlier values that may interfere with model learning. They can come from human errors, faulty sensors, or biases in collection. To identify them, statistical methods such as extreme value analysis or anomaly detection algorithms are used. Once identified, this data can be corrected, replaced, or deleted depending on its impact on the model.
Removing duplicates to avoid bias
Duplicates skew the distribution of data and can give excessive weight to some observations. A dataset containing several occurrences of the same case can cause biased learning by promoting artificial trends. The detection of duplicates is based on comparison rules and clustering techniques, making it possible to eliminate redundant entries while maintaining optimal data diversity.
Normalization and standardization of values
A dataset can contain data expressed at different scales, which can skew model results. Normalization allows values to be brought back into a given interval (for example, between 0 and 1), while standardization adjusts the data to follow a distribution centered on a mean with unit variance. These transformations prevent one variable from dominating the others simply because of its numerical scale.
Balancing classes for better representativeness
An unbalanced dataset can result in a model that favors the majority class and ignores under-represented classes. This problem is common in areas such as fraud detection or medical diagnosis, where positive cases are often in the minority. Balancing can be achieved by subsampling the majority class, oversampling minority classes, or generating synthetic data with techniques such as SMOTE.
Handling missing values
Datasets often contain missing values that can interfere with some algorithms. Depending on the quantity and nature of the missing values, different strategies are adopted: removal of incomplete records, imputation by the mean or median, or even estimation of missing values using prediction algorithms. The choice of method depends on the type of data and the expected impact on the model.
How to avoid and manage biases in an AI dataset?
Biases in an artificial intelligence dataset directly influence the quality of a model's predictions. When a dataset reflects imbalances or partial representations of the real world, the trained algorithm can reproduce these biases and generate erroneous or discriminatory results. It is therefore essential to identify these biases as early as the data preparation phase and to apply appropriate techniques to correct them.
Understanding biases in a dataset
A bias in a dataset corresponds to a systematic distortion of the data that influences the learning model. It may be due to unequal sampling, annotation errors, or poor representativeness of the observed categories. These biases often result in models that favor certain trends over others and can generate unfair or ineffective predictions.
Identify sources of bias
Biases can come from various stages in the data collection and preparation process:
- Selection bias : Some data categories are under-represented or over-represented, which skews the model's predictions.
- Annotation bias : Human annotators can introduce unintended errors or subjective judgments into data labeling.
- Historical biases : The data used to train the model may reflect existing trends in society that are not always neutral or equitable.
- Algorithmic biases : The algorithm can amplify imbalances already present in the data by learning disproportionately about certain categories.
💡 Exploratory data analysis, with visualizations and descriptive statistics, often makes it possible to detect these biases in advance.
Apply bias correction techniques
Once biases have been identified, several methods can be put in place to mitigate them:
- Class rebalancing : If certain categories are under-represented, it is possible to artificially add data (oversampling) or to reduce the presence of dominant categories (subsampling).
- Adjusting annotations : Double validation by several annotators can limit subjective biases.
- Diversifying data sources : Integrating data from different origins makes it possible to improve the representativeness of the data set.
- Algorithmic de-biasing : Some algorithms are able to adjust class weights to limit the impact of detected biases.
🧐 The objective is not to completely eliminate biases, which is often impossible, but to reduce them sufficiently so that the model is more equitable and efficient in a variety of contexts.
Conclusion
Creating a dataset for AI is a demanding process that goes far beyond simply collecting data. From annotation to bias management, including cleaning and balancing classes, each step has a direct impact on the performance of the model.
Careful preparation is essential to ensure reliable predictions and avoid mistakes. Even with automation, human expertise remains essential to ensure the quality and representativeness of data.



