¿Es difícil crear un conjunto de datos para la IA?

Los modelos de inteligencia artificial se basan en un recurso esencial: los conjuntos de datos. Estos conjuntos de datos, que se utilizan para entrenar algoritmos, influyen directamente en el rendimiento y la precisión de los sistemas de IA.
Sin embargo, detrás de la aparente simplicidad del concepto, la creación de un conjunto de datos adaptado a las necesidades de un modelo de aprendizaje automático demuestra ser un proceso mucho más complejo de lo que parece.
💡 Entre la recopilación de datos, su anotación, su limpieza y la posible gestión de sesgos, cada etapa requiere importantes recursos y conocimientos específicos. Entonces, ¿por qué es tan difícil diseñar un conjunto de datos de calidad para la IA?
¿Por qué es esencial un conjunto de datos para la IA (inteligencia artificial)?
La inteligencia artificial se basa en el aprendizaje automático, un proceso en el que un modelo analiza (más o menos) grandes cantidades de datos para identificar patrones y producir predicciones. Sin un conjunto de datos, un modelo de IA no puede aprender ni mejorar. Lo mismo ocurre con la calidad de los datos utilizados: un conjunto de datos bien construido permite entrenar un modelo eficaz, mientras que un conjunto de datos incompleto o mal estructurado corre el riesgo de provocar sesgos y errores.
Por lo tanto, los conjuntos de datos sirven como Materia prima de IA. Permiten aprender algoritmos para identificar tendencias y generalizar sus conocimientos a nuevos casos. Por ejemplo, un modelo de reconocimiento de imágenes no podrá identificar correctamente a un gato si su conjunto de datos contiene solo imágenes de perros. La diversidad y la representatividad de los datos son, por lo tanto, elementos decisivos para garantizar resultados fiables.
Más allá de la simple adquisición de información, un conjunto de datos bien diseñado también desempeña un papel en la adaptabilidad del modelo. Los modelos de IA deben evolucionar con el tiempo para adaptarse a las nuevas tendencias y contextos. Esto significa integrar nuevos datos de forma regular y ajustar el aprendizaje en consecuencia. Por lo tanto, un conjunto de datos dinámico, actualizado y mantenido con cuidado, permite garantizar la relevancia y la eficacia de un modelo a largo plazo.
El rendimiento de un modelo de inteligencia artificial depende en gran medida de la calidad del conjunto de datos utilizado para su formación. Un conjunto de datos mal construido puede distorsionar el aprendizaje, introducir sesgos y limitar la capacidad del modelo para generalizar su conocimiento. Se utilizan varios criterios para evaluar la confiabilidad de un conjunto de datos.
1. Precisión de los datos
Un conjunto de datos de calidad debe contener datos precisos y verificados. Cualquier error en los valores, ya sea incorrecto, con un formato deficiente o información ambigua, puede interferir con el aprendizaje del modelo. Por lo tanto, el rigor a la hora de recopilar, verificar y validar los datos es esencial para garantizar resultados confiables.
2. Diversidad de datos
Un modelo de IA debe poder adaptarse a una variedad de situaciones. Para ello, el conjunto de datos debe reflejar la diversidad del mundo real. Por ejemplo, un modelo de reconocimiento facial debe capacitarse con imágenes de personas de diferentes edades, géneros y orígenes para evitar que funcione correctamente solo en un perfil limitado de personas.
3. La representatividad del conjunto de datos
Más allá de la diversidad, un conjunto de datos debe ser representativo de la población o el problema que busca modelar. Si ciertas categorías de datos están sobrerrepresentadas o infrarrepresentadas, el modelo corre el riesgo de dar una importancia desproporcionada a ciertas características y producir resultados sesgados.
4. Volumen de datos suficiente
El aprendizaje automático se basa en el análisis de grandes cantidades de datos. Cuanto más grande sea un conjunto de datos, más probabilidades hay de que un modelo aprenda a detectar tendencias de manera eficaz. Sin embargo, la cantidad por sí sola no es suficiente: un conjunto de datos grande que está mal anotado o contiene datos redundantes será menos efectivo que un conjunto de datos más pequeño pero mejor estructurado.
5. La ausencia de sesgo
Los sesgos son uno de los principales desafíos a la hora de crear un conjunto de datos. Pueden introducirse involuntariamente durante la recopilación de datos o pueden deberse a una baja representatividad del conjunto de datos. Por ejemplo, un modelo de procesamiento automático del lenguaje basado únicamente en textos escritos por una categoría específica de hablantes puede malinterpretar otras formas de lenguaje. Identificar y limitar estos sesgos es esencial para garantizar la imparcialidad y precisión del modelo.
6. La calidad de la anotación
La anotación de datos desempeña un papel clave, especialmente en las tareas supervisadas. La anotación inexacta o incoherente conduce a errores de aprendizaje. Para garantizar una buena calidad de anotación, a menudo es necesario contar con anotadores capacitados y procesos de validación rigurosos.
Cómo recopilar datos adaptados a las necesidades de un modelo de IA
La recopilación de datos es un paso fundamental para implementar un modelo de inteligencia artificial. Sin datos relevantes y bien estructurados, ni siquiera el mejor algoritmo podrá proporcionar resultados procesables. Esta fase implica varias opciones estratégicas: Dónde encontrar los datos, Cómo recogerlos ¿Y cuáles son los cuestiones éticas y legales para tener en cuenta.
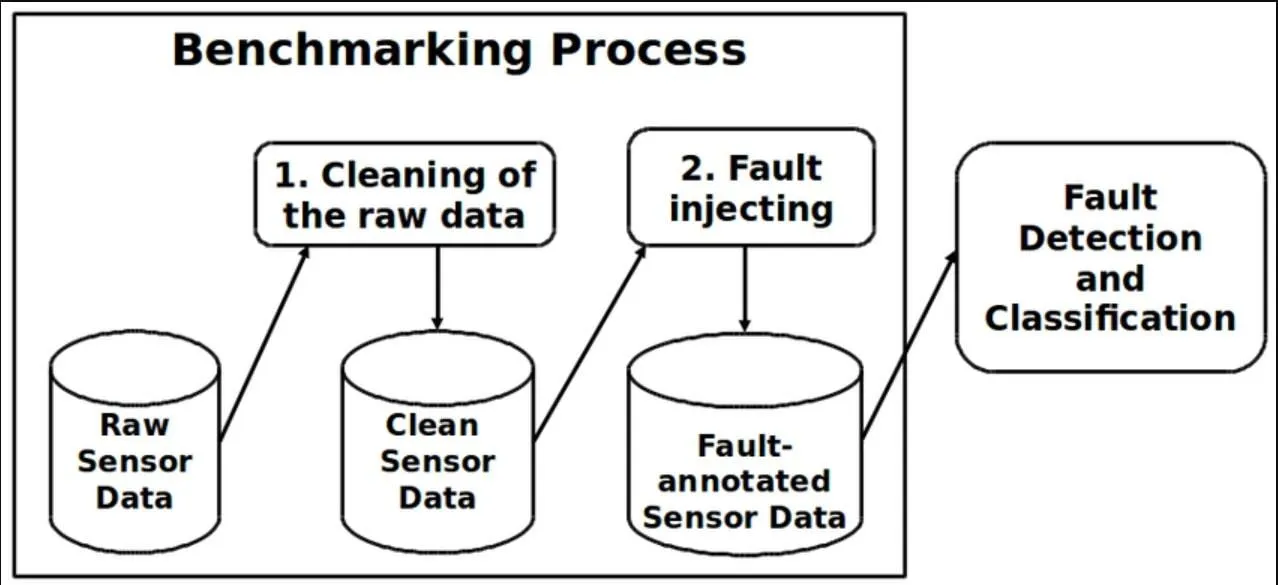
1. ¿Cuáles son las principales fuentes de datos?
Hay varias formas de obtener datos para entrenar un modelo de IA. La elección depende del campo de aplicación, las limitaciones técnicas y los requisitos de calidad.
- Datos públicos : Muchos conjuntos de datos de código abierto están disponibles a través de plataformas como Kaggle, Hugging Face o Google Dataset Search (o incluso Innovatiana): Conjuntos de datos abiertos). Estas fuentes permiten el acceso a una variedad de datos sin tener que recopilarlos usted mismo.
- Datos patentados : Algunas empresas tienen sus propias bases de datos, generadas a partir de sus interacciones con los usuarios (registros, transacciones, historiales, etc.).
- Datos sintéticos : Cuando la recopilación de datos reales es compleja, es posible generar datos artificiales a través de modelos de IA que pueden imitar las tendencias de datos existentes.
- Raspado y extracción de telarañas : Los datos accesibles en línea se pueden extraer mediante herramientas de extracción web, siempre que se cumplan las condiciones de uso de los sitios web.
- Sensores e IoT : Para algunas aplicaciones (salud, industria, movilidad), los datos provienen directamente de sensores conectados u objetos inteligentes que registran varios parámetros en tiempo real.
2. ¿Cuáles son los métodos de recopilación de datos?
Una vez identificada la fuente, la recolección se puede llevar a cabo de varias maneras:
- Recogida manual : En algunos casos, los datos deben ingresarse y anotarse manualmente, especialmente en áreas que requieren experiencia específica (médica, legal, etc.).
- Colaboración colectiva : Las plataformas como Amazon Mechanical Turk permiten recopilar y anotar datos mediante la movilización de anotadores a gran escala (pero prestando atención a la calidad)
- Expertos : empresas como Innovadora o Sama implementa procesos de anotación complejos para anotar datos a escala. Estos procesos involucran a expertos en etiquetado de datos y a las profesiones de sus clientes (médicos, abogados, etc.).
- Automatización y API : Algunas bases de datos ofrecen acceso mediante API para recuperar datos de forma programada y estructurada.
- Adquisición a través de socios : Las colaboraciones con otras empresas o instituciones pueden permitir obtener conjuntos de datos específicos que son difíciles de recopilar por sí solos.
3. ¿Cuáles son las cuestiones éticas y legales?
La recopilación de datos para la IA plantea varios problemas, especialmente en lo que respecta a la privacidad y el cumplimiento normativo.
- Protección de datos personales : Cuando un conjunto de datos contiene información confidencial (nombres, direcciones, comportamientos de los usuarios), es esencial cumplir con las regulaciones actuales, como el GDPR en Europa o la Ley de Privacidad en Canadá.
- Consentimiento del usuario : Si los datos provienen de personas, a menudo es necesario obtener su consentimiento explícito para recopilarlos y usarlos.
- Prejuicio y discriminación : La recopilación sesgada puede generar modelos que reproducen las desigualdades sociales o la discriminación involuntaria. Por lo tanto, comprobar la diversidad y la representatividad de los datos es un gran desafío.
- Restricciones de derechos de autor y uso : Algunos datos, especialmente los extraídos de la web, están protegidos por licencias y no se pueden usar libremente.
¿Por qué la anotación de datos es un paso complejo y costoso para implementar un modelo de IA?
La anotación de datos es un paso esencial en el desarrollo de un modelo de inteligencia artificial, especialmente en el aprendizaje supervisado. Consiste en asociar cada dato a una etiqueta o metadatos, lo que permite al modelo aprender a identificar patrones y generalizar sus predicciones.
💡 Si bien esta fase es fundamental para garantizar resultados precisos, representa uno de los desafíos más complejos y costosos a la hora de implementar un modelo de IA.
1. ¿En qué consiste la anotación de datos?
La anotación es el proceso mediante el cual los datos sin procesar (imágenes, texto, texto, vídeo, audio, etc.) se enriquecen con información que puede utilizar un algoritmo de aprendizaje automático. Estos son algunos ejemplos de anotaciones basadas en el tipo de datos:
- Texto : Asignación de categorías a frases (spam o no spam), identificación de entidades nombradas (personas, lugares, organizaciones), segmentación sintáctica.
- Imágenes y vídeos : Detección de objetos, segmentación semántica, reconocimiento facial, seguimiento de movimiento.
- Datos de audio : Transcripción de palabras, clasificación de sonidos, detección de emociones.
La anotación puede ser realizada manualmente por expertos o anotadores no especializados, pero también de forma semiautomática mediante algoritmos de asistencia a la anotación.
2. ¿Por qué la anotación es fundamental para el aprendizaje automático?
Sin anotación, un modelo supervisado no puede aprender correctamente. Necesita ejemplos etiquetados para comprender la relación entre las entradas (datos sin procesar) y las salidas esperadas (predicciones). Un conjunto de datos bien anotado permite mejorar:
- La precisión de los modelos : Cuanto más rigurosamente se anote un conjunto de datos, más eficiente será el algoritmo.
- Generalización : Una anotación variada y equilibrada permite que el modelo se adapte mejor a los casos reales, más allá de los datos observados durante el entrenamiento.
- Interpretabilidad : Un modelo entrenado con datos bien anotados es más fácil de auditar y corregir en caso de errores.
3. ¿Cuáles son las principales restricciones asociadas a la anotación?
La anotación de datos es una tarea que consume mucho tiempo y recursos por varios motivos:
- Tedioso trabajo manual : Incluso con las herramientas de automatización, gran parte del trabajo sigue siendo manual. La anotación de imágenes o texto puede llevar horas o incluso días, según el tamaño del conjunto de datos.
- Necesidad de experiencia : Algunos tipos de anotación requieren habilidades específicas. Por ejemplo, la anotación de imágenes médicas o documentos legales requiere la intervención de expertos en la materia, lo que aumenta los costos.
- Riesgos de errores e inconsistencias : Dado que la anotación suele ser realizada por varias personas, pueden aparecer discrepancias. Por lo tanto, es necesario establecer procesos de validación y corrección para garantizar la calidad de las anotaciones.
- Un coste elevado : La contratación de anotadores calificados y el uso de plataformas especializadas implican costos importantes. Algunas empresas subcontratan esta tarea a plataformas de crowdsourcing (Amazon Mechanical Turk, Scale AI, etc.), pero la calidad de las anotaciones puede variar.
- Se requiere una actualización constante : Los modelos de IA evolucionan con el tiempo y, a menudo, requieren actualizaciones en su conjunto de datos. Esto implica un esfuerzo continuo de anotación para integrar nuevos datos y evitar la obsolescencia de los modelos.
4. ¿Se puede automatizar la anotación de datos?
Ante las limitaciones de la anotación manual, se han desarrollado varias soluciones de automatización:
- Modelos de anotación asistida : Algunos algoritmos son capaces de proponer anotaciones preliminares que luego validan los anotadores humanos.
- Anotación semisupervisada : La IA aprende a anotar gradualmente gracias a una pequeña cantidad de ejemplos etiquetados.
- Aprendizaje activo : El modelo interactúa con los anotadores y selecciona los datos más relevantes para anotarlos primero.
¿Cuáles son los desafíos de limpiar y preparar datos para un modelo de inteligencia artificial?
La calidad de los datos utilizados para entrenar un modelo de inteligencia artificial influye directamente en su rendimiento. Un conjunto de datos sin procesar a menudo contiene errores, inconsistencias y desequilibrios que pueden sesgar el aprendizaje. La fase de limpieza y preparación de los datos es, por lo tanto, un paso esencial pero complejo, que requiere un procesamiento cuidadoso para garantizar resultados utilizables.
1. ¿Cómo identificar y gestionar los datos ruidosos?
Los datos ruidosos corresponden a información incorrecta, inexacta o atípica que puede interferir con el entrenamiento del modelo. Pueden provenir de varias fuentes: errores humanos, sensores defectuosos, problemas de transmisión de datos, etc.
- Detección de valores atípicos : El análisis estadístico permite identificar datos inusuales (por ejemplo, una antigüedad de 200 años en un conjunto de datos demográficos).
- Filtrado y corrección : Según el contexto, los datos ruidosos se pueden corregir o eliminar para evitar que afecten negativamente al modelo.
Un conjunto de datos ruidoso puede reducir la capacidad de un modelo para generalizar correctamente. Por lo tanto, es esencial definir estrategias de detección y purificación adaptadas a cada tipo de datos.
2. ¿Por qué es importante eliminar los duplicados?
La presencia de duplicados distorsiona las estadísticas y puede generar un sesgo en el aprendizaje del modelo. Los duplicados pueden ser idénticos (copia exacta de los datos) o casi idénticos (datos muy similares con pequeñas variaciones).
- Impacto en el rendimiento : Un conjunto de datos que contiene muchos duplicados puede distorsionar el entrenamiento al dar una importancia desproporcionada a ciertos datos.
- Métodos de detección : El análisis de valores únicos, las similitudes textuales o el uso de algoritmos de agrupamiento permiten identificar y eliminar estos duplicados.
Una limpieza eficaz garantiza que cada dato aporte información útil y no redundante al modelo.
3. ¿Por qué estandarizar y estandarizar los datos?
Los conjuntos de datos suelen contener valores medidos en unidades diferentes o con diferencias significativas. La normalización es necesaria para evitar que ciertas características dominen el aprendizaje de modelos.
- Normalización : Transformación de valores para devolverlos a un intervalo definido (ejemplo: escalar entre 0 y 1).
- Estandarización : Centrar los datos en torno a una media con una varianza unitaria, útil cuando los datos siguen una distribución gaussiana.
Sin estandarización, un modelo puede favorecer ciertas variables solo porque tienen valores numéricos más altos, no porque sean realmente relevantes.
4. ¿Cómo se equilibran las clases en un conjunto de datos?
El equilibrio de clases es un tema importante cuando un conjunto de datos contiene una distribución desigual de categorías. Por ejemplo, en una clasificación de imágenes médicas, si el 95% de las imágenes corresponden a casos sanos y solo el 5% a casos patológicos, es probable que el modelo aprenda a predecir sistemáticamente la clase mayoritaria.
- Submuestreo : Reducción del número de ejemplares en la clase mayoritaria para reequilibrar la distribución.
- Sobremuestreo : Generación artificial de nuevos datos para aumentar la presencia de clases subrepresentadas.
- Uso de técnicas avanzadas : Métodos como la SMOTE (Synthetic Minority Oversampling Technique) permiten generar ejemplos sintéticos para mejorar el equilibrio del conjunto de datos.
Un conjunto de datos equilibrado garantiza que el modelo aprenda de manera justa y no favorezca una categoría a expensas de otras.
5. ¿Cómo hago frente a los valores faltantes?
Los conjuntos de datos reales suelen contener valores faltantes, lo que puede ser un problema para algunos algoritmos. Existen varias estrategias para abordarlos:
- Eliminar datos incompletos : Si falta una variable en demasiados casos, puede ser apropiado excluirla del conjunto de datos.
- Imputación de valores : reemplazar los valores faltantes por medias, medianas o valores predictivos basados en otras variables.
- Uso de algoritmos que toleran los valores faltantes : Algunos modelos, como los árboles de decisión, pueden funcionar con datos incompletos.
La elección del método depende del volumen de datos faltantes y de su impacto en el aprendizaje.
¿Cuáles son los desafíos de limpiar y preparar datos para un modelo de inteligencia artificial?
Un conjunto de datos sin procesar a menudo contiene errores, inconsistencias y desequilibrios que pueden interferir con el aprendizaje de un modelo de IA. Antes de usarlo, es necesario limpiarlo y estructurarlo para garantizar predicciones de mejor calidad. Este paso, si bien es técnico y requiere mucho tiempo, es esencial para evitar que el modelo se vea influenciado por datos inexactos o mal distribuidos. Se deben tener en cuenta varios aspectos para optimizar la preparación de los datos.
Detección y corrección de datos ruidosos
Los datos ruidosos son valores erróneos, inconsistentes o atípicos que pueden interferir con el aprendizaje del modelo. Pueden provenir de errores humanos, sensores defectuosos o sesgos en la recopilación. Para identificarlos, se utilizan métodos estadísticos como el análisis de valores extremos o los algoritmos de detección de anomalías. Una vez identificados, estos datos se pueden corregir, reemplazar o eliminar en función de su impacto en el modelo.
Eliminar duplicados para evitar sesgos
Los duplicados distorsionan la distribución de los datos y pueden dar un peso excesivo a algunas observaciones. Un conjunto de datos que contenga varias ocurrencias del mismo caso puede provocar un aprendizaje sesgado al promover tendencias artificiales. La detección de duplicados se basa en reglas de comparación y técnicas de agrupamiento, lo que permite eliminar las entradas redundantes y, al mismo tiempo, mantener una diversidad de datos óptima.
Normalización y estandarización de valores
Un conjunto de datos puede contener datos expresados en diferentes escalas, lo que puede sesgar los resultados del modelo. La normalización permite devolver los valores a un intervalo determinado (por ejemplo, entre 0 y 1), mientras que la estandarización ajusta los datos para que sigan una distribución centrada en una media con varianza unitaria. Estas transformaciones evitan que una variable domine a las demás simplemente por su escala numérica.
Equilibrar las clases para una mejor representatividad
Un conjunto de datos desequilibrado puede dar como resultado un modelo que favorezca a la clase mayoritaria e ignore las clases subrepresentadas. Este problema es común en áreas como la detección de fraudes o el diagnóstico médico, donde los casos positivos suelen ser minoritarios. El equilibrio se puede lograr submuestreando la clase mayoritaria, sobremuestreando las clases minoritarias o generando datos sintéticos con técnicas como el SMOTE.
Gestión de los valores faltantes
Los conjuntos de datos suelen contener valores faltantes que pueden interferir con algunos algoritmos. Según la cantidad y la naturaleza de los valores faltantes, se adoptan diferentes estrategias: eliminar los registros incompletos, imputarlos por la media o la mediana, o incluso estimar los valores faltantes mediante algoritmos de predicción. La elección del método depende del tipo de datos y del impacto esperado en el modelo.
¿Cómo evitar y gestionar los sesgos en un conjunto de datos de IA?
Los sesgos en un conjunto de datos de inteligencia artificial influyen directamente en la calidad de las predicciones de un modelo. Cuando un conjunto de datos refleja desequilibrios o representaciones parciales del mundo real, el algoritmo entrenado puede reproducir estos sesgos y generar resultados erróneos o discriminatorios. Por lo tanto, es esencial identificar estos sesgos ya en la fase de preparación de los datos y aplicar las técnicas adecuadas para corregirlos.
Comprender los sesgos en un conjunto de datos
Un sesgo en un conjunto de datos corresponde a una distorsión sistemática de los datos que influye en el modelo de aprendizaje. Puede deberse a un muestreo desigual, a errores de anotación o a una escasa representatividad de las categorías observadas. Estos sesgos suelen dar lugar a modelos que favorecen ciertas tendencias sobre otras y pueden generar predicciones injustas o ineficaces.
Identificar las fuentes de sesgo
Los sesgos pueden provenir de varias etapas del proceso de recopilación y preparación de datos:
- Sesgo de selección : Algunas categorías de datos están infrarrepresentadas o sobrerrepresentadas, lo que sesga las predicciones del modelo.
- Sesgo de anotación : Los anotadores humanos pueden introducir errores no intencionados o juicios subjetivos en el etiquetado de datos.
- Sesgos históricos : Los datos utilizados para entrenar el modelo pueden reflejar tendencias existentes en la sociedad que no siempre son neutrales o equitativas.
- Sesgos algorítmicos : El algoritmo puede amplificar los desequilibrios ya presentes en los datos al aprender de manera desproporcionada sobre ciertas categorías.
💡 El análisis exploratorio de datos, con visualizaciones y estadísticas descriptivas, a menudo permite detectar estos sesgos con antelación.
Aplicar técnicas de corrección de sesgos
Una vez que se han identificado los sesgos, se pueden implementar varios métodos para mitigarlos:
- Reequilibrio de clases : Si ciertas categorías están infrarrepresentadas, es posible añadir datos de forma artificial (sobremuestreo) o reducir la presencia de categorías dominantes (submuestreo).
- Ajustar las anotaciones : La doble validación por parte de varios anotadores puede limitar los sesgos subjetivos.
- Diversificación de las fuentes de datos : La integración de datos de diferentes orígenes permite mejorar la representatividad del conjunto de datos.
- Eliminación de sesgos algorítmicos : Algunos algoritmos pueden ajustar las ponderaciones de las clases para limitar el impacto de los sesgos detectados.
🧐 El objetivo no es eliminar por completo los sesgos, lo que a menudo es imposible, sino reducirlos lo suficiente para que el modelo sea más equitativo y eficiente en una variedad de contextos.
Conclusión
La creación de un conjunto de datos para la IA es un proceso exigente que va mucho más allá de la simple recopilación de datos. Desde la anotación hasta la gestión de sesgos, pasando por la limpieza y el equilibrio de las clases, cada paso tiene un impacto directo en el rendimiento del modelo.
Una preparación cuidadosa es esencial para garantizar predicciones confiables y evitar errores. Incluso con la automatización, la experiencia humana sigue siendo esencial para garantizar la calidad y la representatividad de los datos.



