Est-ce difficile de créer un dataset pour l'IA ?

Les modèles d’intelligence artificielle reposent sur une ressource essentielle : les datasets. Ces ensembles de données, utilisés pour entraîner les algorithmes, influencent directement la performance et la précision des systèmes d’IA.
Pourtant, derrière la simplicité apparente du concept, la création d’un dataset adapté aux besoins d’un modèle d’apprentissage automatique se révèle être un processus bien plus complexe qu’il n’y paraît.
💡 Entre la collecte des données, leur annotation, leur nettoyage et l’éventuelle gestion des biais, chaque étape demande des ressources importantes et une expertise spécifique. Alors, pourquoi est-il si difficile de concevoir un dataset de qualité pour l’IA ?
Pourquoi un dataset est-il indispensable pour l’IA (intelligence artificielle) ?
L’intelligence artificielle repose sur l’apprentissage automatique, un processus dans lequel un modèle analyse de (plus ou moins) grandes quantités de données pour identifier des schémas et produire des prédictions. Sans dataset, un modèle d’IA ne peut ni apprendre, ni s’améliorer. Il en va de même pour la qualité des données utilisées : un dataset bien construit permet d’entraîner un modèle efficace, tandis qu’un dataset incomplet ou mal structuré risque d’entraîner des biais et des erreurs.
Les datasets servent ainsi de matière première à l’IA. Ils permettent aux algorithmes d’apprentissage de repérer les tendances et de généraliser leurs connaissances à de nouveaux cas. Par exemple, un modèle de reconnaissance d’images ne pourra pas identifier correctement un chat si son dataset ne contient que des images de chiens. La diversité et la représentativité des données sont donc des éléments déterminants pour garantir des résultats fiables.
Au-delà de la simple acquisition d’informations, un dataset bien conçu joue aussi un rôle dans l’adaptabilité du modèle. Les modèles d’IA doivent évoluer au fil du temps pour s’adapter aux nouvelles tendances et contextes. Cela implique d’intégrer régulièrement de nouvelles données et d’ajuster l’apprentissage en conséquence. Un dataset dynamique, mis à jour et maintenu avec soin, permet donc d’assurer la pertinence et l’efficacité d’un modèle sur le long terme.
La performance d’un modèle d’intelligence artificielle dépend en grande partie de la qualité du dataset utilisé pour son entraînement. Un dataset mal construit peut fausser l’apprentissage, introduire des biais et limiter la capacité du modèle à généraliser ses connaissances. Plusieurs critères permettent d’évaluer la fiabilité d’un dataset.
1. La précision des données
Un dataset de qualité doit contenir des données exactes et vérifiées. Toute erreur dans les valeurs, qu’il s’agisse d’informations incorrectes, mal formatées ou ambiguës, risque de perturber l’apprentissage du modèle. La rigueur dans la collecte, la vérification et la validation des données est donc essentielle pour garantir des résultats fiables.
2. La diversité des données
Un modèle d’IA doit être capable de s’adapter à des situations variées. Pour cela, le dataset doit refléter la diversité du monde réel. Par exemple, un modèle de reconnaissance faciale doit être entraîné avec des images de personnes de différents âges, genres et origines pour éviter qu’il ne fonctionne correctement que sur un profil limité d’individus.
3. La représentativité du dataset
Au-delà de la diversité, un dataset doit être représentatif de la population ou du problème qu’il cherche à modéliser. Si certaines catégories de données sont sur-représentées ou sous-représentées, le modèle risque d’accorder une importance disproportionnée à certaines caractéristiques et de produire des résultats biaisés.
4. Un volume de données suffisant
L’apprentissage automatique repose sur l’analyse de grandes quantités de données. Plus un dataset est volumineux, plus un modèle a de chances d’apprendre à détecter des tendances de manière efficace. Toutefois, la quantité seule ne suffit pas : un grand dataset mal annoté ou contenant des données redondantes sera moins efficace qu’un dataset plus restreint mais mieux structuré.
5. L’absence de biais
Les biais sont l’un des principaux défis dans la construction d’un dataset. Ils peuvent être introduits involontairement lors de la collecte des données ou résulter d’une mauvaise représentativité du dataset. Par exemple, un modèle de traitement automatique du langage entraîné uniquement sur des textes écrits par une catégorie spécifique de locuteurs risque de mal comprendre d’autres formes de langage. Identifier et limiter ces biais est essentiel pour garantir l’équité et la justesse du modèle.
6. La qualité de l’annotation
L’annotation des données joue un rôle clé, notamment dans les tâches supervisées. Une annotation imprécise ou incohérente entraîne des erreurs d’apprentissage. Pour garantir une bonne qualité d’annotation, il est souvent nécessaire d’avoir des annotateurs formés et des processus de validation rigoureux.
Comment collecter des données adaptées aux besoins d’un modèle IA
La collecte de données est une étape fondamentale dans la mise en œuvre d’un modèle d’intelligence artificielle. Sans données pertinentes et bien structurées, même le meilleur algorithme ne pourra pas fournir de résultats exploitables. Cette phase implique plusieurs choix stratégiques : où trouver les données, comment les collecter et quels sont les enjeux éthiques et légaux à considérer.
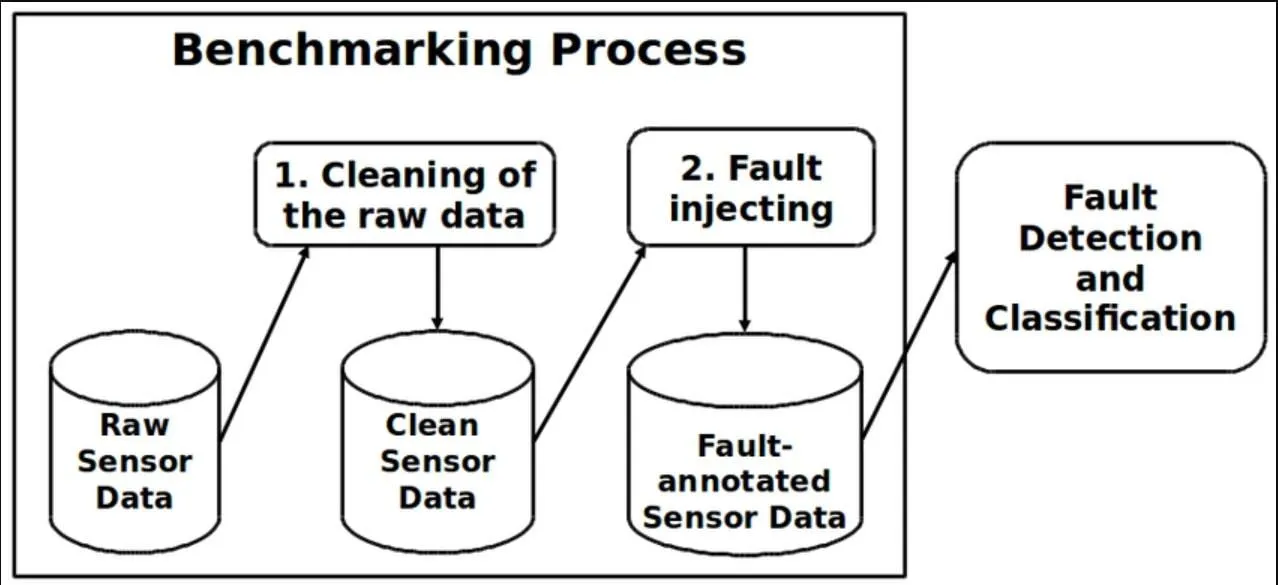
1. Quelles sont les principales sources de données ?
Il existe plusieurs moyens d’obtenir des données pour entraîner un modèle d’IA. Le choix dépend du domaine d’application, des contraintes techniques et des exigences en matière de qualité.
- Données publiques : De nombreux datasets open source sont disponibles via des plateformes comme Kaggle, Hugging Face ou Google Dataset Search (ou encore Innovatiana : Open Datasets). Ces sources permettent d’accéder à des données variées sans avoir à les collecter soi-même.
- Données propriétaires : Certaines entreprises possèdent leurs propres bases de données, générées à partir de leurs interactions avec les utilisateurs (logs, transactions, historiques, etc.).
- Données synthétiques : Lorsque la collecte de données réelles est complexe, il est possible de générer des données artificielles via des modèles d’IA capables d’imiter les tendances des données existantes.
- Scraping et extraction web : Les données accessibles en ligne peuvent être extraites via des outils de web scraping, sous réserve du respect des conditions d’utilisation des sites web.
- Capteurs et IoT : Pour certaines applications (santé, industrie, mobilité), les données proviennent directement de capteurs connectés ou d’objets intelligents qui enregistrent en temps réel divers paramètres.
2. Quelles sont les méthodes de collecte des données ?
Une fois la source identifiée, la collecte peut être réalisée de différentes manières :
- Collecte manuelle : Dans certains cas, les données doivent être saisies et annotées manuellement, notamment dans des domaines nécessitant une expertise spécifique (médical, juridique, etc.).
- Crowdsourcing : Des plateformes comme Amazon Mechanical Turk permettent de collecter et d’annoter des données en mobilisant des annotateurs à grande échelle (mais attention à la qualité)
- Experts : des sociétés comme Innovatiana ou Sama mettent en place des processus d'annotation complexe pour annoter des données à l'échelle. Ces processus impliquent des experts du Data Labeling et des métiers de leurs clients (médecins, juristes, etc.).
- Automatisation et APIs : Certaines bases de données proposent des accès API permettant de récupérer des données de manière programmée et structurée.
- Acquisition via des partenaires : Des collaborations avec d’autres entreprises ou institutions peuvent permettre d’obtenir des jeux de données spécifiques et difficiles à collecter seul.
3. Quelles sont les problématiques éthiques et légales ?
La collecte de données pour l’IA soulève plusieurs enjeux, notamment en matière de respect de la vie privée et de conformité réglementaire.
- Protection des données personnelles : Lorsqu’un dataset contient des informations sensibles (noms, adresses, comportements des utilisateurs), il est essentiel de respecter les réglementations en vigueur comme le RGPD en Europe ou la Loi sur la protection des renseignements personnels au Canada.
- Consentement des utilisateurs : Si les données proviennent d’individus, il est souvent nécessaire d’obtenir leur accord explicite pour les collecter et les exploiter.
- Biais et discrimination : Une collecte biaisée peut engendrer des modèles qui reproduisent des inégalités sociales ou des discriminations involontaires. Vérifier la diversité et la représentativité des données est donc un enjeu majeur.
- Droits d’auteur et restrictions d’usage : Certaines données, notamment celles extraites du web, sont protégées par des licences et ne peuvent pas être utilisées librement.
Pourquoi l’annotation des données est-elle une étape complexe et coûteuse dans la mise en œuvre d’un modèle d’IA ?
L’annotation des données est une étape incontournable dans le développement d’un modèle d’intelligence artificielle, notamment en apprentissage supervisé. Elle consiste à associer à chaque donnée une étiquette ou une métadonnée permettant au modèle d’apprendre à identifier des motifs et à généraliser ses prédictions.
💡 Bien que cette phase soit essentielle pour garantir des résultats précis, elle représente l’un des défis les plus complexes et les plus coûteux de la mise en œuvre d’un modèle d’IA.
1. En quoi consiste l’annotation des données ?
L’annotation est le processus par lequel des données brutes (images, textes, vidéos, signaux audio, etc.) sont enrichies avec des informations exploitables par un algorithme d’apprentissage automatique. Voici quelques exemples d’annotation en fonction du type de données :
- Texte : Attribution de catégories à des phrases (spam ou non-spam), identification d’entités nommées (personnes, lieux, organisations), segmentation syntaxique.
- Images et vidéos : Détection d’objets, segmentation sémantique, reconnaissance faciale, suivi de mouvement.
- Données audio : Transcription de paroles, classification de sons, détection d’émotions.
L’annotation peut être réalisée manuellement par des experts ou des annotateurs non spécialisés, mais aussi de manière semi-automatisée grâce à des algorithmes d’aide à l’annotation.
2. Pourquoi l’annotation est-elle essentielle au Machine Learning ?
Sans annotation, un modèle supervisé ne peut pas apprendre correctement. Il a besoin d’exemples étiquetés pour comprendre la relation entre les entrées (données brutes) et les sorties attendues (prédictions). Un dataset bien annoté permet d’améliorer :
- La précision des modèles : Plus un dataset est annoté avec rigueur, plus l’algorithme sera performant.
- La généralisation : Une annotation variée et équilibrée permet au modèle de mieux s’adapter à des cas réels, au-delà des données vues lors de l’entraînement.
- L’interprétabilité : Un modèle entraîné sur des données bien annotées est plus facile à auditer et à corriger en cas d’erreurs.
3. Quelles sont les principales contraintes liées à l’annotation ?
L’annotation des données est une tâche particulièrement chronophage et gourmande en ressources, pour plusieurs raisons :
- Un travail manuel fastidieux : Même avec des outils d’automatisation, une grande partie du travail reste manuelle. L’annotation d’images ou de textes peut prendre des heures, voire des jours, en fonction de la taille du dataset.
- Un besoin d’expertise : Certains types d’annotation nécessitent des compétences spécifiques. Par exemple, annoter des images médicales ou des documents juridiques demande l’intervention d’experts du domaine, ce qui augmente les coûts.
- Des risques d’erreurs et d’incohérences : L’annotation étant souvent réalisée par plusieurs personnes, des divergences peuvent apparaître. Il est donc nécessaire de mettre en place des processus de validation et de relecture pour garantir la qualité des annotations.
- Un coût élevé : Le recrutement d’annotateurs qualifiés et l’utilisation de plateformes spécialisées entraînent des coûts importants. Certaines entreprises externalisent cette tâche à des plateformes de crowdsourcing (Amazon Mechanical Turk, Scale AI, etc.), mais la qualité des annotations peut alors varier.
- Une mise à jour constante nécessaire : Les modèles d’IA évoluent avec le temps et nécessitent souvent des mises à jour de leur dataset. Cela implique un effort continu d’annotation pour intégrer de nouvelles données et éviter l’obsolescence du modèle.
4. Peut-on automatiser l’annotation des données ?
Face aux contraintes de l’annotation manuelle, plusieurs solutions d’automatisation sont développées :
- Les modèles d’annotation assistée : Certains algorithmes sont capables de proposer des annotations préliminaires que des annotateurs humains valident ensuite.
- L’annotation semi-supervisée : L’IA apprend à annoter progressivement grâce à un petit nombre d’exemples étiquetés.
- L’apprentissage actif : Le modèle interagit avec les annotateurs et sélectionne les données les plus pertinentes à annoter en priorité.
Quels défis posent le nettoyage et la préparation des données pour un modèle d’intelligence artificielle ?
La qualité des données utilisées pour entraîner un modèle d’intelligence artificielle influence directement sa performance. Un dataset brut contient souvent des erreurs, des incohérences et des déséquilibres qui peuvent fausser l’apprentissage. La phase de nettoyage et de préparation des données est donc une étape essentielle, mais complexe, nécessitant des traitements minutieux pour garantir des résultats exploitables.
1. Comment identifier et gérer les données bruitées ?
Les données bruitées correspondent à des informations incorrectes, imprécises ou aberrantes pouvant perturber l’entraînement du modèle. Elles peuvent provenir de plusieurs sources : erreurs humaines, capteurs défectueux, problèmes de transmission des données, etc.
- Détection des valeurs aberrantes : L’analyse statistique permet d’identifier des données inhabituelles (par exemple, un âge de 200 ans dans un dataset démographique).
- Filtrage et correction : Selon le contexte, les données bruitées peuvent être corrigées ou supprimées pour éviter qu’elles influencent négativement le modèle.
Un dataset bruité peut réduire la capacité d’un modèle à généraliser correctement. Il est donc essentiel de définir des stratégies de détection et d’épuration adaptées à chaque type de données.
2. Pourquoi est-il important de supprimer les doublons ?
La présence de doublons fausse les statistiques et peut entraîner un biais dans l’apprentissage du modèle. Les doublons peuvent être identiques (copie exacte d’une donnée) ou quasi-identiques (données très similaires avec des variations mineures).
- Impact sur la performance : Un dataset contenant de nombreux doublons peut fausser l’entraînement en accordant une importance disproportionnée à certaines données.
- Méthodes de détection : L’analyse des valeurs uniques, des similarités textuelles ou l’utilisation d’algorithmes de clustering permettent d’identifier et de supprimer ces doublons.
Un nettoyage efficace garantit que chaque donnée apporte une information utile et non redondante au modèle.
3. Pourquoi normaliser et standardiser les données ?
Les datasets contiennent souvent des valeurs mesurées dans des unités différentes ou présentant des écarts importants. Une normalisation est nécessaire pour éviter que certaines caractéristiques ne dominent l’apprentissage du modèle.
- Normalisation : Transformation des valeurs pour les ramener dans un intervalle défini (exemple : mise à l’échelle entre 0 et 1).
- Standardisation : Centrage des données autour d’une moyenne avec une variance unitaire, utile lorsque les données suivent une distribution gaussienne.
Sans normalisation, un modèle risque de privilégier certaines variables uniquement parce qu’elles possèdent des valeurs numériques plus élevées, et non parce qu’elles sont réellement pertinentes.
4. Comment équilibrer les classes dans un dataset ?
L’équilibrage des classes est un enjeu important lorsqu’un dataset contient une répartition inégale des catégories. Par exemple, dans une classification d’images médicales, si 95 % des images correspondent à des cas sains et seulement 5 % à des cas pathologiques, le modèle risque d’apprendre à prédire systématiquement la classe majoritaire.
- Sous-échantillonnage (undersampling) : Réduction du nombre d’exemples dans la classe majoritaire pour rééquilibrer la distribution.
- Sur-échantillonnage (oversampling) : Génération artificielle de nouvelles données pour augmenter la présence des classes sous-représentées.
- Utilisation de techniques avancées : Des méthodes comme SMOTE (Synthetic Minority Over-sampling Technique) permettent de générer des exemples synthétiques pour améliorer l’équilibre du dataset.
Un dataset équilibré garantit que le modèle apprend de manière équitable et ne favorise pas une catégorie au détriment des autres.
5. Comment gérer les valeurs manquantes ?
Les datasets réels contiennent souvent des valeurs absentes, ce qui peut poser problème pour certains algorithmes. Il existe plusieurs stratégies pour les traiter :
- Suppression des données incomplètes : Si une variable est absente dans un trop grand nombre de cas, il peut être pertinent de l’exclure du dataset.
- Imputation de valeurs : Remplacement des valeurs manquantes par des moyennes, des médianes ou des valeurs prédictives basées sur d’autres variables.
- Utilisation d’algorithmes tolérants aux valeurs manquantes : Certains modèles, comme les arbres de décision, peuvent fonctionner avec des données incomplètes.
Le choix de la méthode dépend du volume de données manquantes et de leur impact sur l’apprentissage.
Quels défis posent le nettoyage et la préparation des données pour un modèle d’intelligence artificielle ?
Un dataset brut contient souvent des erreurs, des incohérences et des déséquilibres qui peuvent fausser l’apprentissage d’un modèle d’IA. Avant d’être utilisé, il doit être nettoyé et structuré pour garantir une meilleure qualité des prédictions. Cette étape, bien que technique et chronophage, est essentielle pour éviter que le modèle ne soit influencé par des données inexactes ou mal réparties. Plusieurs aspects doivent être pris en compte pour optimiser la préparation des données.
Détection et correction des données bruitées
Les données bruitées sont des valeurs erronées, incohérentes ou aberrantes qui risquent de fausser l’apprentissage du modèle. Elles peuvent provenir d’erreurs humaines, de capteurs défectueux ou de biais dans la collecte. Pour les identifier, des méthodes statistiques comme l’analyse des valeurs extrêmes ou des algorithmes de détection d’anomalies sont utilisées. Une fois repérées, ces données peuvent être corrigées, remplacées ou supprimées en fonction de leur impact sur le modèle.
Suppression des doublons pour éviter les biais
Les doublons faussent la répartition des données et peuvent donner un poids excessif à certaines observations. Un dataset contenant plusieurs occurrences du même cas peut engendrer un apprentissage biaisé en favorisant des tendances artificielles. La détection des doublons repose sur des règles de comparaison et des techniques de clustering, permettant d’éliminer les entrées redondantes tout en conservant une diversité optimale des données.
Normalisation et standardisation des valeurs
Un dataset peut contenir des données exprimées dans des échelles différentes, ce qui peut fausser les résultats du modèle. La normalisation permet de ramener les valeurs dans un intervalle donné (par exemple, entre 0 et 1), tandis que la standardisation ajuste les données pour qu’elles suivent une distribution centrée sur une moyenne avec une variance unitaire. Ces transformations évitent qu’une variable domine les autres simplement en raison de son échelle numérique.
Équilibrage des classes pour une meilleure représentativité
Un dataset déséquilibré peut entraîner un modèle qui privilégie la classe majoritaire et ignore les classes sous-représentées. Ce problème est fréquent dans des domaines comme la détection de fraudes ou le diagnostic médical, où les cas positifs sont souvent en minorité. L’équilibrage peut être réalisé par sous-échantillonnage de la classe majoritaire, sur-échantillonnage des classes minoritaires ou génération de données synthétiques avec des techniques comme SMOTE.
Traitement des valeurs manquantes
Les datasets contiennent souvent des valeurs absentes qui peuvent perturber certains algorithmes. Selon la quantité et la nature des valeurs manquantes, différentes stratégies sont adoptées : suppression des enregistrements incomplets, imputation par la moyenne ou la médiane, ou encore estimation des valeurs manquantes à l’aide d’algorithmes de prédiction. Le choix de la méthode dépend du type de données et de l’impact attendu sur le modèle.
Comment éviter et gérer les biais dans un dataset d’IA ?
Les biais dans un dataset d’intelligence artificielle influencent directement la qualité des prédictions d’un modèle. Lorsqu’un dataset reflète des déséquilibres ou des représentations partielles du monde réel, l’algorithme entraîné peut reproduire ces biais et générer des résultats erronés ou discriminatoires. Il est donc essentiel d’identifier ces biais dès la phase de préparation des données et d’appliquer des techniques adaptées pour les corriger.
Comprendre les biais dans un dataset
Un biais dans un dataset correspond à une distorsion systématique des données qui influence le modèle d’apprentissage. Il peut être dû à un échantillonnage inégal, à des erreurs d’annotation ou à une mauvaise représentativité des catégories observées. Ces biais entraînent souvent des modèles qui favorisent certaines tendances au détriment d’autres et peuvent générer des prédictions injustes ou inefficaces.
Identifier les sources de biais
Les biais peuvent provenir de différentes étapes du processus de collecte et de préparation des données :
- Biais de sélection : Certaines catégories de données sont sous-représentées ou sur-représentées, ce qui fausse les prédictions du modèle.
- Biais d’annotation : Les annotateurs humains peuvent introduire des erreurs involontaires ou des jugements subjectifs dans l’étiquetage des données.
- Biais historiques : Les données utilisées pour entraîner le modèle peuvent refléter des tendances existantes dans la société, qui ne sont pas toujours neutres ou équitables.
- Biais algorithmiques : L’algorithme peut amplifier des déséquilibres déjà présents dans les données en apprenant de manière disproportionnée sur certaines catégories.
💡 Une analyse exploratoire des données, avec des visualisations et des statistiques descriptives, permet souvent de détecter ces biais en amont.
Appliquer des techniques de correction des biais
Une fois les biais identifiés, plusieurs méthodes peuvent être mises en place pour les atténuer :
- Rééquilibrage des classes : Si certaines catégories sont sous-représentées, il est possible d’ajouter artificiellement des données (sur-échantillonnage) ou de réduire la présence des catégories dominantes (sous-échantillonnage).
- Ajustement des annotations : Une double validation par plusieurs annotateurs peut permettre de limiter les biais subjectifs.
- Diversification des sources de données : Intégrer des données provenant de différentes origines permet d’améliorer la représentativité du data set.
- Dé-biaisage algorithmique : Certains algorithmes sont capables d’ajuster les pondérations des classes pour limiter l’impact des biais détectés.
🧐 L'objectif n’est pas d’éliminer totalement les biais, ce qui est souvent impossible, mais de les réduire suffisamment pour que le modèle soit plus équitable et performant dans des contextes variés.
Conclusion
Créer un dataset pour l’IA est un processus exigeant qui va bien au-delà de la simple collecte de données. De l’annotation à la gestion des biais, en passant par le nettoyage et l’équilibrage des classes, chaque étape impacte directement la performance du modèle.
Une préparation rigoureuse est essentielle pour garantir des prédictions fiables et éviter les erreurs. Même avec l’automatisation, l’expertise humaine reste indispensable pour assurer la qualité et la représentativité des données.



