Image Labeling: Complete Guide to Computer Vision Training Data

💡 Key Takeaways
- Image labeling involves annotating visual data with tags, bounding boxes, or classifications to train machine learning models for object recognition and computer vision tasks
- Quality labeling requires complete object annotation, tight bounding boxes, specific label names, and consistent labeling instructions across all images in the dataset
- Modern image labeling combines manual annotation, AI-assisted tools, and automated workflows to scale efficiently while maintaining accuracy for large datasets
- Common applications include autonomous vehicles, medical imaging, retail automation, and security systems that rely on accurate object detection and classification
- Proper quality control, team coordination, and specialized annotation platforms are used for managing large-scale labeling projects successfully
Ever wondered what truly powers today’s AI vision systems? Not the flashy headlines about “AI labeling itself,” nor the illusion that crowd-sourced micro-tasks can magically produce high-quality data at scale. The real story is far more deliberate -and far more human. Behind every breakthrough in Computer Vision lies a foundation of meticulously labeled data. From self driving cars navigating busy streets to medical AI detecting tumors in CT scans, the accuracy of these systems depends entirely on the quality of their training data. Image labeling transforms raw visual information into structured datasets that enable machine learning models to recognize patterns, detect objects, and make intelligent decisions.
Nowadays, the process of annotating images has evolved from simple manual classification to sophisticated workflows involving AI-assisted tools and automated quality control. Today’s data scientists face the challenge of creating high quality datasets at scale while maintaining consistency and accuracy across thousands or millions of images. This comprehensive guide will walk you through everything you need to know about image labeling, from basic concepts to enterprise-scale operations.
👉 Hey... whether you’re building your first computer vision model or managing annotation teams for production systems, understanding the principles and practices of effective image labeling is key for success. Let’s explore how to create the labeled data that powers today’s most advanced AI applications.
What is Image Labeling?
Image labeling is the systematic process of adding meaningful annotations to images to create training data for supervised machine learning models. This fundamental step in computer vision pipeline involves human annotators or automated systems identifying and marking objects, features, or characteristics within image data to teach algorithms what to recognize and how to interpret visual information.
The core purpose of image labeling extends beyond simple tagging. When you label images, you’re essentially creating a visual vocabulary that enables neural networks to understand the relationship between pixels and real-world concepts. Each annotation becomes a teaching example that helps models identify patterns, make predictions, and classify new, unseen data with confidence.
Modern annotation approaches encompass various techniques depending on the specific computer vision tasks at hand. Bounding boxes define rectangular regions around objects for detection algorithms. Polygons and segmentation masks provide pixel-level precision for complex shapes. Keypoint annotation marks specific features like facial landmarks or joint positions. Image classification assigns category labels to entire images rather than specific regions.
The distinction between training and validation datasets plays also a critical role in model development (and is something to remember!). Training data teaches algorithms through labeled examples, while validation sets test performance on unseen images to evaluate generalization capabilities. This separation ensures that models can handle real-world scenarios beyond their initial training set.
Data scientists must carefully consider the direct impact of annotation quality on final model performance. Inconsistent labels, missing objects, or inaccurate boundaries propagate errors throughout the machine learning pipeline, resulting in unreliable predictions when deployed in production environments. High quality datasets with precise annotations enable computer vision models to achieve the accuracy levels required for critical applications like medical diagnosis or autonomous navigation.
Types of Image Labeling Tasks
The world of image labeling encompasses diverse annotation methods, each designed for specific computer vision applications and model architectures. Understanding these different approaches helps teams select the most appropriate labeling strategy for their particular use case and performance requirements.
Image Classification
Image classification represents the most straightforward form of image labeling, where annotators assign one or more category labels to entire images. This approach treats each image as a single unit, focusing on the overall content rather than specific object locations or boundaries.
Binary classification handles simple yes/no decisions, such as determining whether an image contains a defect in manufacturing quality control. Multi-class classification extends this concept to multiple mutually exclusive categories, like classifying animals as cats, dogs, or birds. Multilabel classification allows multiple tags per image, enabling systems to recognize that a single photo might contain both a car and a person.
Applications span content moderation platforms that automatically flag inappropriate material, medical diagnosis systems that classify X-rays as normal or abnormal, and retail systems that categorize product images for search and recommendation engines. The key to successful classification lies in establishing clear class definitions that minimize ambiguity and ensure consistent labeling across all team members.
Best practices emphasize balanced datasets where each class contains sufficient examples for robust learning. Annotators should follow standardized criteria and receive training on edge cases to maintain consistency throughout large datasets.
Object Detection
Object detection moves beyond whole-image classification to identify and locate specific objects within images using bounding boxes. This labeling task requires annotators to draw rectangular boundaries around each object of interest while assigning appropriate class labels to the detected instances.
The coordinate system defines object location through x and y position values along with width and height dimensions of rectangular boxes. Multiple objects per image create complex scenarios where annotators must identify every relevant instance, even when objects overlap or appear partially obscured.
Each bounding box serves as both a location indicator and a classification label, enabling object detection models to answer two critical questions: “What objects are present?” and “Where are they located?” This dual information makes object detection particularly valuable for applications requiring spatial awareness and object counting capabilities.

Real-world applications demonstrate the versatility of object detection across industries. Autonomous driving systems detect vehicles, pedestrians, and traffic signs to navigate safely. Surveillance networks identify suspicious activities or unauthorized persons in restricted areas. Inventory management systems count products on retail shelves and track stock levels automatically. Sports analytics platforms track player movements and ball positions for performance analysis.
💡 The precision of bounding box placement directly affects model accuracy. Tight boxes that closely follow object boundaries provide better training signals than loose annotations with excessive background space. However, boxes must completely contain the target object to avoid cutting off important features that models need for recognition.
Instance Segmentation
Instance segmentation elevates annotation precision by creating detailed polygon outlines around individual object instances, providing pixel-level accuracy that surpasses the capabilities of rectangular bounding boxes. This technique enables models to understand exact object shapes and distinguish between overlapping instances of the same class.
Unlike bounding boxes that capture surrounding background pixels, polygon annotations follow the precise contours of irregular objects. This approach becomes important and a clear game-changer when dealing with complex shapes like clothing items, organic objects, or architectural elements where rectangular boundaries would include significant non-object areas.
The distinction between instance and semantic segmentation lies in object separation. Instance segmentation treats each object as a unique entity, enabling models to count individual instances and track them separately. A crowd scene might contain multiple people, each receiving its own polygon annotation and unique identifier.

Medical imaging applications rely heavily on instance segmentation for precise tumor boundaries, organ delineation, and tissue classification where accuracy directly impacts patient outcomes. Robotics systems use detailed object outlines for precise manipulation and grasping tasks. Precision agriculture employs segmentation to analyze individual plants, identify disease spots, and optimize treatment applications. Satellite imagery analysis depends on polygon annotations to map building footprints, agricultural fields, and environmental features.
👉 The labor-intensive nature of polygon annotation requires specialized tools and trained annotators who understand the importance of precise boundary placement. Quality control becomes critical as small errors in polygon vertices can significantly impact model performance.
Semantic Segmentation
Semantic segmentation represents the most comprehensive form of image annotation, requiring labelers to classify every pixel in an image according to predefined categories. This pixel-level labeling creates dense prediction maps that provide complete scene understanding without distinguishing between individual object instances.
Color-coded masks assign different hues to represent various object categories or material types throughout the entire image. Road pixels might appear in gray, vegetation in green, vehicles in red, and sky in blue, creating a comprehensive map of scene components. This approach enables models to understand spatial relationships and material properties across complex environments.

The comprehensive nature of semantic segmentation makes it particularly valuable for applications requiring complete environmental understanding. Autonomous navigation systems need pixel-level road surface identification to distinguish drivable areas from obstacles. Urban planning applications analyze satellite imagery to classify land use patterns and infrastructure development. Environmental monitoring systems track vegetation health, water bodies, and urban sprawl through detailed pixel classification.
Medical image analysis leverages semantic segmentation for tissue classification, anatomical structure identification, and pathology detection where precise boundaries matter for diagnosis and treatment planning. The technique enables radiologists to quantify organ volumes, measure tumor progression, and plan surgical procedures with enhanced precision.
💡 The challenge of semantic segmentation lies in maintaining consistency across large images with complex scenes. Annotators must make thousands of pixel-level decisions while following strict guidelines about object boundaries and class definitions. Quality control requires systematic validation to ensure accurate and complete coverage of all image regions.
Image Labeling Best Practices
Creating high quality datasets requires systematic approaches that ensure consistency, accuracy, and completeness across all annotation tasks. These proven strategies form the foundation for successful computer vision projects and help teams avoid common pitfalls that can derail model performance.
Complete Object Annotation
The principle of complete object annotation demands that labelers identify and mark every instance of target objects within each image, regardless of size, visibility, or complexity. This comprehensive approach prevents false negative errors where models fail to recognize objects simply because similar instances were overlooked during training.
Consistent coverage across the entire dataset ensures that models learn to recognize objects in various contexts and conditions. Partial labeling creates confusion in machine learning algorithms, which may interpret unlabeled objects as background elements and subsequently ignore similar objects in real-world scenarios.
Hidden and partially visible objects require special attention from annotation teams. Small objects that appear distant or unclear should still receive proper labels to improve model robustness across different scales and viewing conditions. Occluded objects where only portions are visible need complete boundary estimation as if the full object were present.
A practical example from traffic sign detection illustrates this principle clearly. Labeling projects must include every visible sign, from large highway markers to small regulatory notices partially hidden behind vegetation. Skipping smaller or partially obscured signs would teach the model to ignore these critical safety indicators in real-world deployment scenarios.
The completeness requirement extends to edge cases and unusual presentations that might seem unimportant but actually represent valuable learning opportunities. These challenging examples often determine the difference between models that work in controlled laboratory conditions and those that succeed in unpredictable real-world environments.
Precise Boundary Definition
Accurate boundary placement forms the cornerstone of effective object detection and segmentation training. Tight bounding boxes that minimize empty space while fully enclosing target objects provide optimal training signals for machine learning models to understand object extent and location.
The goal involves finding the balance between complete object inclusion and minimal background capture. Boxes should encompass all visible parts of the target object without significant padding that would include irrelevant background pixels. This precision becomes particularly important when objects appear close together or overlap within the scene.

Complete object inclusion takes precedence over aesthetic considerations. Even when objects appear partially cut off at image edges, bounding boxes should extend to include all visible portions rather than creating artificially tightened boundaries that might confuse model training.
Occluded objects present unique challenges where annotators must estimate complete object boundaries based on visible portions. Rather than drawing boxes only around visible parts, best practice involves projecting the likely full object extent to provide models with realistic size and shape expectations.
Overlapping annotations become acceptable when objects genuinely overlap in three-dimensional space. Multiple objects sharing the same image region should each receive appropriate boundaries, even when this creates overlapping boxes that reflect the spatial reality of complex scenes.
Specific Label Naming
The specificity of category labels directly impacts model flexibility and future deployment options. Granular categories that capture meaningful distinctions enable more sophisticated applications while preserving the option to combine classes later for broader categorization needs.
Rather than using generic labels like “dog,” effective annotation strategies employ specific breed classifications such as “golden_retriever,” “labrador,” or “german_shepherd”. This approach allows models to learn fine-grained distinctions that might prove valuable for specialized applications while maintaining the ability to group all breeds under a general “dog” category when needed.
Future flexibility considerations favor specific over general labeling approaches. Converting broad categories into specific subcategories requires complete re-annotation of existing datasets, while combining specific labels into broader groups can be accomplished through simple relabeling operations during model training.
Consistent terminology across the entire dataset prevents confusion and ensures that all team members understand exactly what each label represents. Standardized naming conventions should address common variations, abbreviations, and edge cases that might arise during large-scale annotation projects.
Domain expertise plays a crucial role in establishing appropriate label hierarchies and specificity levels. Medical imaging projects benefit from precise anatomical terminology, while agricultural applications require specific crop variety identification that might seem unnecessarily detailed to general annotators but proves essential for effective model deployment.
Clear Labeling Instructions
Comprehensive annotation guidelines serve as the foundation for consistent, high-quality datasets that enable reliable model performance. These documents must address edge cases, ambiguous situations, and quality standards that maintain uniformity across different annotators and annotation sessions.
Detailed documentation should cover common scenarios that annotators encounter, providing specific guidance for handling unclear object boundaries, partial occlusions, and objects that span multiple categories. Written guidelines prevent inconsistent interpretation of challenging cases that could introduce systematic errors into the dataset.
Visual examples enhance written instructions by demonstrating correct and incorrect annotation approaches for representative scenarios. Before-and-after comparisons help annotators understand the difference between acceptable and problematic labeling choices, reducing errors and improving overall dataset quality.
Team consistency requires that all annotators follow identical standards and procedures regardless of their experience level or personal preferences. Regular training sessions and guideline updates ensure that annotation quality remains stable as projects evolve and new edge cases emerge.
The iterative refinement of labeling instructions based on common errors and project evolution helps teams adapt to changing requirements while maintaining historical consistency. Regular reviews of annotation quality can identify areas where guidelines need clarification or expansion to address recurring issues.
Modern Image Labeling Methods
The evolution of image annotation has transformed from purely manual processes to sophisticated hybrid approaches that combine human expertise with artificial intelligence. Understanding these different methodologies helps teams select the most appropriate strategy for their specific requirements, timeline, and budget constraints.
Manual Annotation
Traditional manual annotation relies on trained human annotators who manually draw bounding boxes, create polygons, and assign labels based on their visual interpretation and domain expertise. This approach delivers the highest accuracy levels for complex scenes and edge cases that challenge automated systems.
Human intelligence excels at handling ambiguous situations, unusual object presentations, and context-dependent decisions that require reasoning beyond simple pattern recognition. Experienced annotators can distinguish between similar-looking objects, interpret partial occlusions, and make judgment calls about borderline cases that would confuse algorithmic approaches.
The time-intensive nature of manual annotation becomes apparent when dealing with large datasets and complex labeling tasks. Individual images might require several minutes of careful attention, particularly for detailed segmentation work or scenes containing multiple objects with unclear boundaries.
Quality control in manual workflows typically involves multiple reviewer validation systems where senior annotators check the work of junior team members. Inter-annotator agreement measurements help identify inconsistencies and provide feedback for continuous improvement in annotation accuracy.
Despite the labor investment required, manual annotation remains the gold standard for establishing ground truth datasets, particularly in domains where accuracy requirements are extremely high or where automated tools lack sufficient training data to perform reliably.
AI-Assisted Labeling
Modern AI-assisted approaches leverage machine learning models to generate initial annotations that human reviewers then validate, correct, and refine. This hybrid methodology significantly reduces the time required for dataset creation while maintaining the accuracy benefits of human oversight.
Pre-labeling workflows begin with trained models analyzing unlabeled images to generate preliminary bounding boxes, classifications, or segmentation masks. Human annotators then review these automated suggestions, making corrections where necessary and adding missed objects that the model failed to detect.
Smart annotation tools incorporate advanced techniques like Meta’s Segment Anything 2, which can generate high-quality object boundaries with minimal human input. These foundation models understand general object concepts and can propose accurate segmentation masks that annotators can quickly approve or adjust.
The efficiency gains from AI-assisted labeling are substantial, with many teams reporting 70-95% reductions in annotation time compared to purely manual approaches. This acceleration enables the creation of larger datasets within realistic budget and timeline constraints.
Human-in-the-loop systems optimize the combination of machine speed with human accuracy, allowing teams to focus their expertise on challenging cases while letting automated tools handle routine annotations. This division of labor maximizes both efficiency and quality in large-scale annotation projects.
Automated Annotation
Fully automated annotation represents the cutting edge of dataset creation, utilizing foundation models and advanced AI systems to label thousands of images without direct human intervention. While not yet suitable for all applications, automated approaches show promise for specific domains and use cases.
Foundation models trained on massive datasets can recognize common objects and generate labels for new images based on their extensive pre-training. These systems excel at identifying standard objects in typical contexts but may struggle with domain-specific items or unusual presentations.
Synthetic data generation offers another automated approach where computer graphics systems create realistic images with automatically known ground truth labels. This technique works particularly well for scenarios where real-world data collection is difficult or expensive, such as rare medical conditions or extreme weather situations.
Active learning algorithms identify the most valuable images to label for maximum model improvement, optimizing the allocation of annotation resources. These systems analyze model uncertainty to prioritize images that would provide the greatest learning benefit if properly labeled.
The cost-effectiveness of automated annotation becomes apparent in large-scale projects where manual labeling would be prohibitively expensive. However, quality validation remains essential to ensure that automated labels meet the standards required for reliable model training.
💡 Current limitations include domain specificity challenges where automated systems trained on general datasets may not understand specialized terminology or object types. Accuracy validation through statistical sampling helps teams understand when automated labels are sufficient and when human review is necessary.
Quality Control and Team Management
Maintaining annotation accuracy across large teams and extended project timelines requires systematic quality control processes and effective workflow management. These organizational strategies ensure that datasets meet the standards necessary for reliable model performance while managing the human factors that influence annotation consistency.
Multi-Reviewer Workflows
Consensus labeling approaches involve multiple annotators working on the same images, with disagreements triggering review processes that resolve conflicts through discussion or expert arbitration. This method helps identify systematic errors and improves overall dataset reliability through collective validation.
Hierarchical review structures organize annotation teams into junior and senior roles, where less experienced annotators create initial labels that senior reviewers validate and correct. This mentorship approach maintains quality while enabling team scaling and knowledge transfer across the organization.
Inter-annotator agreement measurements provide quantitative assessments of labeling consistency using statistical measures like Cohen’s kappa for binary tasks or Fleiss’ kappa for multiple annotators. These metrics help identify areas where guidelines need clarification and track improvement over time.
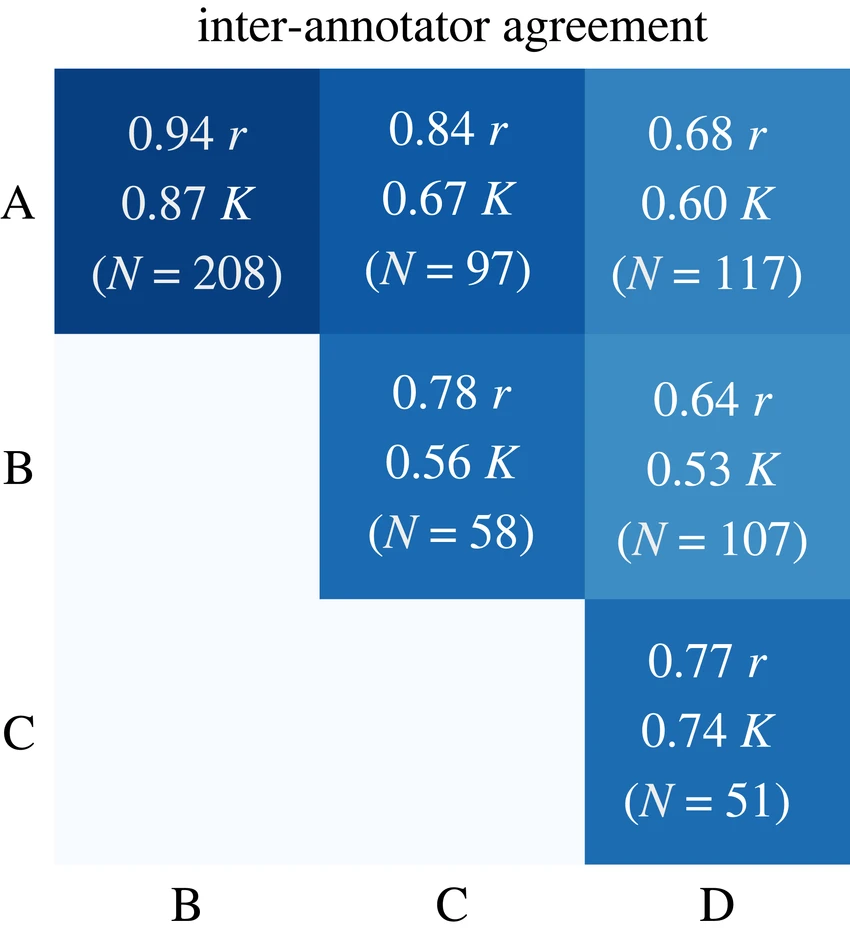
Target agreement scores above 0.8 indicate acceptable consistency for most production systems, though critical applications like medical imaging may require higher standards. Regular monitoring of these metrics helps project managers identify when additional training or guideline refinement is necessary.
Blind validation processes involve independent reviewers assessing subsets of annotations without seeing the original labels, providing unbiased quality assessments that reveal systematic errors or drift in annotation standards over time.
Automated Quality Checks
Algorithm-based quality monitoring systems can identify outlier annotations that deviate significantly from expected patterns, flagging potential errors for human review. These automated checks complement manual quality control by catching issues that might escape human attention.
Consistency validation ensures that labels follow project guidelines and naming conventions through automated rule checking. These systems can detect inconsistent terminology, missing required attributes, or annotations that violate geometric constraints.
Statistical monitoring tracks annotation speed, accuracy trends, and reviewer performance metrics to identify potential issues before they affect large portions of the dataset. Sudden changes in annotation patterns might indicate tool problems, guideline misunderstandings, or annotator fatigue.
Real-time feedback systems provide immediate alerts for common errors and guidance for improvement, helping annotators correct issues during the labeling process rather than discovering problems during post-annotation review phases.
Automated quality metrics can include boundary precision measurements, object count validation, and class distribution analysis that ensures datasets maintain appropriate balance across different categories and scenarios.
Image Labeling Platforms and Tools
The selection of appropriate annotation software significantly impacts project efficiency, quality control capabilities, and team collaboration effectiveness. Modern platforms offer diverse features designed for different use cases, from simple bounding box annotation to complex multi-modal labeling workflows.
Open Source Solutions
Label Studio provides a flexible, customizable platform supporting multiple data types and annotation interfaces. Its open-source nature allows teams to modify the software for specific requirements while benefiting from community contributions and ongoing development.
The platform supports various annotation types including bounding boxes, polygons, keypoints, and text classification, making it suitable for diverse computer vision tasks. Integration capabilities enable connection with machine learning pipelines and automated quality control systems.
CVAT (Computer Vision Annotation Tool) specializes in video annotation and collaborative workflows, offering features specifically designed for temporal data and multi-frame object tracking. The platform includes built-in quality control mechanisms and supports distributed annotation teams.
LabelImg offers a straightforward solution for object detection bounding box annotation, providing an intuitive interface that enables rapid labeling of large image datasets. While less feature-rich than comprehensive platforms, its simplicity makes it ideal for straightforward annotation tasks.
Cost advantages of open-source solutions include elimination of licensing fees and the ability to customize functionality for specific project requirements. However, teams must consider the technical expertise required for setup, maintenance, and customization of these platforms.
Commercial Platforms
Roboflow provides an end-to-end computer vision platform that combines annotation tools with model training and deployment capabilities. The integrated workflow enables teams to move seamlessly from raw images to deployed models within a single environment.
Advanced features include automated quality checks, version control for datasets, and performance monitoring that tracks how annotation quality affects model accuracy. The platform supports collaborative workflows and provides detailed analytics on annotation progress and team productivity.
Azure Machine Learning offers Microsoft’s cloud-based labeling service with ML-assisted features that leverage pre-trained models to accelerate annotation workflows. Integration with the broader Azure ecosystem enables seamless connection to storage, compute, and deployment services.
Amazon SageMaker Ground Truth provides AWS annotation services with sophisticated workforce management capabilities, enabling teams to combine internal annotators with crowdsourced labor. The platform includes built-in quality control mechanisms and automated workflow management.
Enterprise features available in commercial platforms include advanced security controls, compliance certifications, and dedicated support that may be essential for organizations handling sensitive data or operating in regulated industries.
Specialized Tools
Medical imaging applications require specialized DICOM viewers and annotation tools designed for radiology workflows. These platforms understand medical image formats, coordinate systems, and clinical terminology specific to healthcare applications.
Autonomous vehicle development relies on specialized annotation tools that handle LiDAR point clouds, camera fusion, and 3D bounding boxes necessary for perception system training. These tools must manage complex sensor data and provide precise spatial annotations.
Satellite imagery analysis demands geospatial annotation capabilities with coordinate system support and large-scale image handling. Specialized tools for this domain understand geographic projections and enable annotation of features across vast geographic areas.
Domain-specific optimization ensures that annotation tools understand the unique requirements, terminology, and workflows of particular industries, providing efficiency gains that generic platforms cannot match.
Real-World Applications and Use Cases
The practical application of image labeling spans diverse industries where computer vision systems solve complex problems and automate critical decision-making processes. Understanding these real-world implementations demonstrates the tangible value of high-quality annotated datasets.
Autonomous Vehicles
Self driving cars represent one of the most demanding applications of computer vision technology, requiring precise object detection capabilities for vehicles, pedestrians, traffic signs, road markings, and lane boundaries. The safety-critical nature of autonomous navigation demands extremely high annotation accuracy and comprehensive coverage of edge cases.
Object detection systems must identify and track multiple objects simultaneously while predicting their likely movements and trajectories. Bounding box annotations capture vehicle positions, while keypoint annotation marks important features like headlights, turn signals, and license plates that provide behavioral cues.
Semantic segmentation enables vehicles to understand road surfaces, sidewalks, buildings, and vegetation classification for navigation planning. Pixel-level accuracy helps distinguish between drivable surfaces and obstacles, while instance segmentation separates individual objects for tracking and prediction purposes.
The complexity of 3D annotation becomes apparent when dealing with LiDAR point cloud data that provides depth perception and spatial understanding. Annotators must label objects in three-dimensional space, accounting for distance, relative motion, and occlusion patterns that affect sensor readings.
Safety requirements mandate extensive testing and validation datasets that cover diverse weather conditions, lighting scenarios, and traffic patterns. Edge cases like construction zones, emergency vehicles, and unusual road configurations require special attention to ensure robust performance across all driving scenarios.
Medical Imaging
Healthcare applications demand the highest levels of annotation accuracy due to the direct impact on patient diagnosis and treatment decisions. Medical image labeling requires domain expertise from trained radiologists and clinicians who understand anatomical structures and pathological presentations.
Diagnostic assistance systems analyze CT scans, X-rays, and MRI images to identify tumors, fractures, and other abnormalities that might escape human attention or require confirmation. Precise boundary annotation enables quantitative analysis of lesion size, growth patterns, and treatment response.
Anatomical segmentation provides detailed organ boundaries, tissue classification, and abnormality highlighting that supports surgical planning and treatment monitoring. Instance segmentation distinguishes between multiple nodules or lesions within the same organ system.
Clinical workflow integration requires annotation tools that work seamlessly with PACS (Picture Archiving and Communication Systems) and electronic health records. Radiologists must be able to access, annotate, and share medical images within their existing clinical environments.
Regulatory compliance adds complexity to medical annotation projects, with FDA approval requirements demanding extensive validation and documentation of annotation quality, inter-observer variability, and systematic error analysis.
Retail and E-commerce
Product recognition systems enable inventory management, visual search capabilities, and automated recommendation engines that enhance customer experience and operational efficiency. Image labeling supports multiple retail applications from warehouse automation to customer analytics.
Quality control applications detect manufacturing defects, packaging errors, and product damage through automated visual inspection systems. Precise annotation of defect types and locations enables machine learning models to identify quality issues faster and more consistently than human inspectors.
Customer analytics leverage surveillance camera data to understand shopping patterns, heat mapping, and demographic analysis. Privacy-conscious annotation approaches focus on behavior patterns rather than individual identification, requiring careful consideration of data protection regulations.
Brand monitoring systems detect logos, trademarks, and product placements across social media and marketing content. Trademark protection applications require precise logo annotation and brand element identification across diverse contexts and visual presentations.
Inventory management automation relies on product recognition systems that can identify specific items, track stock levels, and monitor shelf organization. Bounding box annotation enables counting algorithms while classification labels provide product category information.
Security and Surveillance
Security applications encompass facial recognition for access control, threat detection for weapons and suspicious behaviors, and crowd analysis for emergency response optimization. These systems must balance security effectiveness with privacy protection and regulatory compliance.
Threat detection systems identify weapons, suspicious packages, and abnormal behaviors through automated video analysis. Annotation requirements include precise object boundaries, behavioral pattern classification, and temporal sequence labeling for activity recognition.
Crowd analysis applications estimate density, flow patterns, and emergency evacuation routes through semantic segmentation of people and environmental features. These systems help venue managers optimize layouts and respond effectively to crowd control situations.
Privacy considerations require careful handling of facial recognition data, with many organizations implementing anonymization techniques that preserve security capabilities while protecting individual privacy rights. Annotation workflows must comply with data protection regulations and organizational privacy policies.
Perimeter monitoring systems detect unauthorized access, vehicle intrusions, and environmental changes around critical infrastructure. Multi-modal annotation combines visible light cameras with thermal imaging and motion sensors for comprehensive security coverage.
Scaling Image Labeling Operations
Growing annotation requirements from prototype to production systems demands strategic planning for workforce management, process optimization, and quality maintenance across larger datasets and longer project timelines.
Workforce Management
Internal annotation teams provide domain expertise and consistent quality control but require significant investment in training, tools, and management infrastructure. Building internal capabilities makes sense for organizations with ongoing annotation needs and specialized domain requirements.
Professional labeling services offer expertise and scalability for large projects while transferring quality control responsibilities to specialized providers. These services often provide cost advantages for organizations without internal annotation capabilities or those facing tight project deadlines.
Crowdsourcing platforms like Amazon Mechanical Turk enable distributed annotation across large numbers of workers, providing cost-effective scaling for suitable tasks. However, quality control becomes more challenging with distributed teams, requiring robust validation processes and clear task instructions. ℹ️ This proves efficient when quality requirements are low.
Hybrid approaches combine different workforce models to optimize cost and quality balance. Organizations might use internal teams for complex annotations while leveraging crowdsourcing for simpler tasks, or employ professional services for initial dataset creation with internal teams handling ongoing maintenance and updates.
Team scaling considerations include training time for new annotators, quality control overhead, and communication complexity that grows with team size. Effective scaling requires systematic onboarding processes and clear workflow management procedures.
-hand-innv.png)
Process Optimization
Active learning strategies prioritize the most informative images for labeling to maximize model improvement per annotation hour invested. These algorithms analyze model uncertainty to identify images that would provide the greatest learning benefit if properly labeled.
Transfer learning approaches leverage pre-trained models to reduce annotation requirements by starting with models that already understand general visual concepts. Fine-tuning these models on smaller, domain-specific datasets often achieves better results than training from scratch with larger annotation investments.
Data augmentation techniques generate additional training examples from existing labeled data through rotation, scaling, color adjustment, and other transformations. These approaches increase dataset diversity and model robustness without requiring additional annotation effort.
Continuous improvement processes incorporate feedback from model performance and deployment experience to refine annotation guidelines and quality standards. Regular evaluation of model accuracy helps identify areas where additional or improved annotations would provide the greatest benefit.
Automated workflow management tools help coordinate annotation tasks, track progress, and manage quality control across large teams and complex projects. These systems can automatically distribute work, monitor productivity, and flag quality issues for review.



