Image Labeling: una guía completa para Computer Vision Data

💡 Para grabar
- La anotación de imágenes es el proceso de agregar etiquetas, delimitadores o clasificaciones a datos visuales con el fin de entrenar modelos de aprendizaje automático para tareas de reconocimiento de objetos y visión artificial.
- La anotación de alta calidad requiere que cada objeto esté completamente identificado, que las casillas sean precisas, que los números de las etiquetas sean consistentes y que las instrucciones sean consistentes en el conjunto de datos.
- Métodos modernos de anotación de imágenes que combinan la anotación manual, las herramientas compatibles con la IA y los flujos de trabajo automatizados para aumentar la productividad y, al mismo tiempo, mantener una alta precisión en grandes volúmenes de datos.
- Las aplicaciones más comunes incluyen automóviles autónomos, imágenes médicas, automatización de minorías y sistemas de seguridad, todos los cuales se basan en la detección y clasificación precisas de objetos.
- Un control de calidad riguroso, una coordinación eficaz del equipo y plataformas de anotación especializadas son esenciales para gestionar de manera eficiente los proyectos de anotación a gran escala.
⚙️ ¿Qué es lo que realmente impulsa la visión artificial moderna?
¿Alguna vez se ha preguntado que es lo que realmente impulsa los sistemas de visión artificial actuales? No son ellos quienes promueven la «IA con anotaciones automáticas» ni la ilusión de que las microáreas distribuidas por ellas solas pueden producir datos de alta calidad a gran escala. La realidad es mucho más estructurada y profundamente humana.
Sin embargo, hay un avance importante en la visión artificial, hay una base de datos meticulosamente anotada. Desde vehículos autónomos que registran la congestión hasta sistemas médicos que detectan tumores mediante tomografía computarizada, la precisión de estas tecnologías depende completamente de la calidad de los datos de entrenamiento.
La anotación de imágenes convierte la información visual sin procesar en conjuntos de datos estructurados, lo que permite que los modelos de aprendizaje automático reconozcan patrones, detecten objetos y tomen decisiones inteligentes.
🧠 Desde la clasificación manual hasta los flujos de trabajo híbridos
Hoy en día, el proceso de anotación de imágenes ha evolucionado considerablemente: no existe una forma sencilla de clasificar las fotos manualmente, sin implementar flujos de trabajo sofisticados que incorporen herramientas de asistencia de inteligencia artificial y controles de calidad automatizados.
Los científicos de datos están comprometidos con una falta de confianza constante: crear conjuntos de datos masivos y homogéneos y, al mismo tiempo, garantizar la coherencia y la precisión en millas, incluidos millones, de imágenes.
👉 Esta guía completa le explicará todo lo que necesita saber sobre el etiquetado de imágenes, desde las operaciones básicas hasta las operaciones a gran escala.
🚀 Si eres...
... en el proceso de crear su primer modelo de visión artificial o de supervisar el equipo de anotación de los sistemas de producción, comprender los principios y las mejores prácticas de la anotación visual de datos es fundamental para su éxito. Vamos a descubrir cómo crear datos anotados que estimulen las aplicaciones de inteligencia artificial más avanzadas de las noticias.
🔍 ¿Qué es el Image Labeling?
El etiquetado o anotación de imágenes es el proceso sistemático de agregar anotaciones significativas a las imágenes para crear datos de entrenamiento para modelos de aprendizaje supervisado.
Este paso fundamental en el proceso de visión artificial involucrará a anotadores humanos o sistemas automatizados responsables de identificar y marcar objetos, características o estructuras presentes en las imágenes para enseñar a los algoritmos a reconocer e interpretar el mundo visual.
El objetivo va mucho más allá de la simple etiqueta: cada anotación crea un lenguaje visual que las redes neuronales utilizan para entender la relación entre el píxel y los conceptos reales. Cada etiqueta es un ejemplo educativo que ayuda a los modelos a identificar patrones, predecir y clasificar nuevas imágenes con confianza.
🧩 Tipos de tareas de anotación de imágenes
Clasificación de imágenes
Esta es la forma más sencilla de hacer anotaciones: el anotador asigna una o más etiquetas a una imagen completa. Este enfoque considera cada imagen como una unidad completa, centralizada en su contenido general en lugar de la ubicación de objetos específicos.
- La clasificación binaria Responde a las preguntas sencillas: «Sí/No», por ejemplo: ¿Hay algún defecto en este producto?
- La clasificación multiclase Asigne solo una categoría entre varias (gato, perro, pajaro, etc.).
- La clasificación de múltiples etiquetas permite varias categorías simultáneas (una foto puede contener tanto un automóvil como una persona).
Las aplicaciones incluyen la moderación de contenido, el diagnóstico médico (radiografías normales/anormales) y la categorización de imágenes de productos para su investigación y recomendación.
Detección de objetos
La detección de objetos va más allá de la clasificación global: identifica y localiza cada objeto en la imagen central Cajas Delimitadoras. Cada cuadrado, definido por coordenadas (x, y, derecha, alto), se utiliza como indicador de posición y como etiqueta de clase.
La misma imagen puede contener varios objetos, a veces parcialmente visibles o superpuestos entre ellos.
Este método permite a los modelos responder a dos preguntas fundamentales:
«¿Qué objetos hay? y «¿Dónde están?» ».
Las aplicaciones de la conducción autónoma (coches, peatones, señales) hasta la videovigilancia, la gestión de inventarios y el análisis deportivo.
💡 La precisión de los gráficos de las cajas influye directamente en el rendimiento del modelo: las cajas ajustadas y consistentes proporcionan mejores señales de aprendizaje.

Segmentación de instancias
La segmentación de las instancias mejora la precisión de las anotaciones para crear contornos poligonales detallados alrededor de cada objeto individual, lo que proporciona una precisión a nivel de píxel que supera las capacidades de los delimitadores rectangulares simples.
Esta técnica permite a los modelos comprender la forma exacta de los objetos y distinguir entre las instancias que se superponen dentro de la misma categoría.
A diferencia de los delimitadores, que solo incluyen puntos de fondo, las anotaciones poligonales siguen con precisión los contornos precisos de los objetos irregulares. Este diseño es esencial, y de hecho transformador, cuando se abordan formas complejas, como papel, objetos orgánicos o elementos arquitectónicos, por lo que los límites rectangulares incluirían una parte significativa de áreas no relacionadas.
La diferencia entre segmentar instancias y segmentación semántica radical en la separación de objetos. La segmentación de instancias considera cada objeto como una entidad única, lo que permite a los modelos controlar y rasterizar cada instancia de forma individual. Por ejemplo, una escena multitudinaria puede contener a varias personas, cada una de las cuales recibe su propia anotación poligonal y un identificador independiente.

Las aplicaciones diagnósticas mediante imágenes médicas dependen en gran medida de la segmentación de las instancias para definir con precisión los límites de los tumores, la delimitación de los órganos y la clasificación de los tejidos, por lo que la precisión afecta directamente a los resultados de los pacientes. Las aplicaciones de diagnóstico basadas en imágenes de Robotics se basan en gran medida en segmentar instancias Delinea con precisión los contornos de los tumores, distingue los órganos y clasifica los tejidos, una precisión que depende directamente de los resultados clínicos de los pacientes. Los sistemas robóticos utilizan estos contornos detallados de los objetos para realizar manipulaciones y convulsiones con gran precisión.
En agricultura de precisión, la segmentación permite analizar cada planta individualmente, identificar las áreas cerradas y optimizar las terapias. Por último, el análisis de imágenes de satélite usa anotaciones poligonales para mapear aceites de construcción, parcelas agrícolas y características ambientales. Los elementos utilizan los contornos detallados de nuestros objetos para realizar tareas precisas de manipulación y manipulación. La agricultura de precisión implica la segmentación para analizar las plantas individuales, identificar las áreas afectadas por el confinamiento y optimizar las aplicaciones de tratamiento. El análisis de las imágenes de satélite depende de las anotaciones poligonales para mapear las superficies de los edificios, los campos agrícolas y las características ambientales.
👉 La naturaleza particularmente exigente de la anotación de polígonos requiere Herramientas especializadas y anotadores entrenados, consciente de la importancia de un esquema preciso. El control de calidad es crucial, porque los pequeños errores en la verdad de un polígono pueden tener un impacto significativo en el rendimiento del modelo.
Segmentación semántica
La segmentación semántica representa la forma más completa de etiquetar imágenes. Consta de clasifica cada píxel de una imagen según categorías predefinidas. Esta anotación a nivel de píxel genera mapas de predicción densos, que proporcionan una comprensión global de la escena sin distinguir instancias individuales del mismo objeto.
De mascarillas de colores se puede utilizar para diferenciar categorías o tipos de materiales a lo largo de la imagen: las carreteras pueden aparecer en gris, la vegetación en verde, los coches en rojo y el cielo azul. Este método permite a los modelos comprender relaciones espaciales y el propiedades del material en entornos complejos.

💡 Principal desafío: mantener la consistencia en imágenes grandes y complejas: los anotadores tienen que tomar miles de decisiones perfectas, con un control de calidad restringido para garantizar una anotación completa y precisa.
Mejores prácticas para anotar imágenes
La creación de conjuntos de datos de alta calidad requiere un enfoque sistemático que garantice coherencia, precisión y exhaustividad en todas las tareas de anotación. Estas políticas comparables forman la base de cualquier proyecto de visión artificial existente y ayudan a los equipos a evitar errores comunes que pueden afectar el rendimiento del modelo.
Anotación de objeto completa
El principio de anotación completa de objetos establece que los anotadores deben identificar y marcar todas las instancias de los objetos objetivo presentes en cada imagen, sin importar su tamaño, visibilidad o nivel de complejidad.
Esta metodología integral permite evitar los errores de tipo falso negativo, en los cuales los modelos no logran reconocer ciertos objetos porque instancias similares no fueron etiquetadas durante el entrenamiento.
Una cobertura uniforme de todo el conjunto de datos garantiza que los modelos aprendan a reconocer objetos en diferentes contextos y condiciones. Por el contrario, la anotación parcial genera confusión en los algoritmos de aprendizaje automático, ya que los objetos no etiquetados pueden ser interpretados como parte del fondo y, posteriormente, ignorados en escenarios reales.
Los objetos ocultos o parcialmente visibles requieren una atención especial. Incluso los objetos pequeños, borrosos o lejanos deben ser anotados para mejorar la robustez del modelo frente a diferentes escalas y condiciones visuales.
Los objetos ocluidos, de los cuales solo se ve una parte, también deben contar con una estimación completa de sus límites, como si el objeto estuviera completamente visible.
Un ejemplo concreto se encuentra en la detección de señales de tráfico: los proyectos de anotación deben incluir todas las señales visibles, desde los grandes carteles de autopista hasta las señales pequeñas parcialmente cubiertas por vegetación. Omitir las más pequeñas o las parcialmente visibles puede enseñar al modelo a ignorar estos indicadores críticos durante su implementación en el mundo real.
El requisito de exhaustividad también se extiende a los casos límite y a las presentaciones inusuales que, aunque puedan parecer secundarias, constituyen ejemplos de aprendizaje muy valiosos. Estas situaciones complejas suelen marcar la diferencia entre los modelos que funcionan únicamente en laboratorio y aquellos capaces de rendir bien en entornos reales e impredecibles.
Precise definition of contornos
Un posicionamiento preciso de los contornos constituye la piedra angular del entrenamiento en detección y segmentación de objetos. Las cajas delimitadoras precisas minimizan el espacio vacío e incluyen completamente los objetos objetivo, proporcionando las señales de aprendizaje óptimas para que los modelos comprendan la extensión y la ubicación exacta de los objetos.
El objetivo es encontrar un equilibrio entre la inclusión completa del objeto y la reducción del ruido de fondo. Las cajas deben abarcar todas las partes visibles del objeto, sin incluir de forma innecesaria los píxeles del fondo. Esta precisión se vuelve crítica cuando los objetos están muy cerca o se superponen dentro de la escena.

La inclusión total del objeto tiene prioridad sobre las consideraciones estéticas: incluso cuando un objeto está parcialmente cortado por los bordes de la imagen, la caja debe extenderse a todas las partes visibles, en lugar de crear límites limitados artificialmente que el modelo pueda crear artificialmente.
Los objetos ocluido representando un problema en particular: los anotadores deben estimar los contornos completos a partir de las partes visibles. En lugar de dibujar un cuadro solo alrededor de las partes visibles, la mejor práctica es projecte all the possible alcance para proporcionar al modelo expectativas realistas de tamaño y forma.
Les Anotaciones superpuestas son aceptables cuando los objetos están realmente superpuestos en un espacio tridimensional. Cada objeto que incluya la misma área de imagen debe asignarse a su propio límite, incluso si crea superposiciones que reflejen la realidad espacial de escenas complejas.
Denominación precisa de etiquetas
El nivel de especificidad Dde las categorías de etiquetas tiene un impacto directo en la flexibilidad del modelo y sobre las posibilidades de despliegue Futuro. Las categorías más precisas, que capturan distinciones importantes, permiten aplicaciones más sofisticadas y, al mismo tiempo, mantienen la capacidad de agrupar las clases de manera más apropiada para necesidades de categorización más amplias.
En lugar de utilizar etiquetas genéricas como «perro», un método de anotación eficaz favorece las clasificaciones específicas, como «golden_retriever», «Labrador» o «Pastor Alemán».
Esta granularidad permite a los modelos aprender distinciones específicas útiles para aplicaciones especializadas, al tiempo que mantienen la capacidad de clasificar estas subclases en una categoría general («perro») si es necesario.
Las consideraciones de flexibilidad futura por lo tanto, son partes en una situación específica en lugar de un general. La transformación de una categoría extensa en subcategorías específicas requiere un reanotación completa sin embargo, del conjunto de datos, lo contrario (combinar etiquetas específicas en categorías generales) se puede descifrar fácilmente durante el entrenamiento del modelo.
Instrucciones de anotación ("Annotation guidelines") claras
Instrucciones de anotación completas y precisas constituyen la base para crear conjuntos de datos consistentes y de alta calidad, garantizando así un rendimiento confiable de los modelos.
Estos documentos deben abordar los casos límite (edge cases), las situaciones ambiguas y las normas de calidad, con el fin de mantener la coherencia entre los anotadores y a lo largo de las diferentes sesiones de trabajo.
La documentación detallada debe cubrir las situaciones más comunes a las que se enfrentan los anotadores, proporcionando instrucciones específicas para gestionar contornos borrosos, oclusiones parciales y objetos que pertenecen a varias categorías.
Las directrices escritas ayudan a evitar interpretaciones incoherentes de casos complejos que podrían introducir errores sistemáticos en el conjunto de datos. Los ejemplos visuales refuerzan estas instrucciones al ilustrar las formas correctas e incorrectas de anotar en distintos escenarios representativos. Las comparaciones antes/después permiten a los anotadores entender la diferencia entre un etiquetado aceptable y un error típico, reduciendo las equivocaciones y mejorando la calidad general de las anotaciones.
La coherencia del equipo exige que todos los anotadores sigan las mismas normas y procedimientos, independientemente de su experiencia o preferencias personales. Las sesiones de formación periódicas y las actualizaciones de las directrices son fundamentales para mantener la calidad, garantizando la adaptación continua de los proyectos a medida que surgen nuevos casos de uso.
La mejora continua de las directrices, basada en el análisis de errores frecuentes y en la evolución de las necesidades del proyecto, ayuda a los equipos a adaptarse sin perder coherencia histórica.
Las revisiones periódicas de la calidad de las anotaciones permiten identificar los puntos que requieren mayor claridad o ajustes, corrigiendo así los problemas recurrentes y elevando los estándares globales de precisión.
Métodos «modernos» de anotación de imágenes para IA
La anotación manual tradicional depende de la capacidad de los anotadores para crear etiquetas basadas en su interpretación visual y en su experiencia técnica o de dominio.
Este método ofrece el nivel más alto de precisión, especialmente en escenas complejas o casos especiales que ponen a prueba los sistemas automatizados. La inteligencia humana sobresale en situaciones ambiguas, en representaciones inusuales de objetos y en decisiones contextuales que requieren razonamiento más allá del simple reconocimiento de patrones.
Los anotadores experimentados saben diferenciar objetos similares, interpretar oclusiones parciales y tomar decisiones adecuadas en casos límite que podrían confundir a un algoritmo. Sin embargo, este enfoque es altamente demandante en tiempo, especialmente para conjuntos de datos extensos o tareas complejas.
Cada imagen puede requerir varios minutos de trabajo, en particular cuando se trata de anotaciones de segmentación detalladas o de escenas con numerosos objetos y contornos poco definidos. El control de calidad en los flujos de trabajo manuales suele basarse en un sistema de validación multinivel, en el cual los anotadores sénior revisan y validan el trabajo de sus pares o de miembros más jóvenes del equipo.
Las medidas de acuerdo entre anotadores (como el coeficiente Kappa de Cohen) permiten detectar inconsistencias y ofrecer retroalimentación útil para mejorar de forma continua la precisión general de las anotaciones.
💡 A pesar del tiempo y los costos involucrados, la anotación manual permanece la referencia absoluta para crear conjuntos de datos de referencia («verdad básica» o "ground truth"), especialmente en áreas donde la precisión es fundamental o cuando las herramientas automatizadas no tienen datos de entrenamiento adecuados.
Anotación asistida por inteligencia artificial
La anotación asistida por inteligencia artificial representa un enfoque moderno que utiliza modelos de aprendizaje automático para generar anotaciones iniciales, las cuales son posteriormente validadas, corregidas y refinadas por anotadores humanos.
Este método híbrido reduce significativamente el tiempo de producción, manteniendo al mismo tiempo los beneficios de la supervisión y el criterio humano. Los flujos de trabajo de preanotación comienzan analizando imágenes sin etiquetar mediante modelos previamente entrenados, que generan cajas delimitadoras, clasificaciones o máscaras de segmentación.
A continuación, los anotadores revisan estas sugerencias automáticas, corrigen los errores y añaden los objetos omitidos por el sistema. Las herramientas modernas de anotación ya incorporan técnicas avanzadas como Segment Anything 2 (Meta), capaz de generar contornos de objetos con gran precisión y mínima intervención humana.
Estos modelos fundamentales comprenden conceptos visuales generales y pueden sugerir máscaras de segmentación muy precisas, que los anotadores únicamente deben validar o ajustar ligeramente. Las ganancias de eficiencia son notables: numerosos equipos han observado reducciones del 70 % al 95 % en el tiempo de anotación en comparación con los métodos puramente manuales.
Esta aceleración permite crear conjuntos de datos mucho más grandes dentro de plazos y presupuestos realistas. Los sistemas “human-in-the-loop” optimizan la complementariedad entre la velocidad de las máquinas y la precisión humana.
Así, los anotadores se concentran en casos complejos, mientras que los algoritmos se encargan de las tareas repetitivas, maximizando tanto la eficiencia como la calidad de los proyectos de anotación a gran escala.
Anotación totalmente automatizada
La anotación automática representa la vanguardia en la creación de conjuntos de datos, utilizando modelos fundamentales y sistemas avanzados de inteligencia artificial capaces de etiquetar miles de imágenes sin intervención humana directa.
Aunque su aplicación todavía se limita a ciertos casos de uso, esta tecnología muestra un potencial creciente en áreas específicas. Los modelos fundamentales, previamente entrenados con enormes volúmenes de datos, pueden reconocer objetos comunes y generar etiquetas para nuevas imágenes gracias a su amplia base de conocimiento.
Estos sistemas ofrecen excelentes resultados con objetos estándar en contextos típicos, aunque pueden presentar dificultades en dominios especializados o frente a representaciones atípicas.
La generación de datos sintéticos constituye otro método automatizado: los entornos virtuales crean imágenes realistas acompañadas de etiquetas perfectas, conocidas de antemano. Este enfoque resulta particularmente útil cuando la recopilación de datos reales es difícil o costosa, como en el caso de fenómenos poco comunes o condiciones ambientales extremas.
Los algoritmos de aprendizaje activo (active learning) permiten identificar las imágenes más valiosas para anotar, maximizando el progreso del modelo por hora de esfuerzo invertido y optimizando el uso de los recursos de anotación.
Los beneficios económicos de la anotación automatizada son evidentes en proyectos a gran escala, donde la anotación manual sería inviable o excesivamente costosa.
No obstante, una validación rigurosa de la calidad sigue siendo esencial para garantizar que las etiquetas generadas cumplan con los estándares requeridos para un entrenamiento fiable de los modelos.
💡 Las limitaciones actuales están relacionadas con la especialización y el conocimiento experto (por ejemplo, en los campos médico, legal o técnico): los sistemas automatizados, entrenados con datos genéricos, pueden no interpretar correctamente los términos u objetos específicos de un dominio concreto. Una verificación estadística de precisión ayuda a los equipos a determinar cuándo las etiquetas automáticas son suficientes y cuándo es necesaria la intervención humana para mantener la fiabilidad del conjunto de datos.
Control de calidad y gestión de equipos
Mantener una anotación de alta precisión dentro de equipos numerosos y durante largos periodos de tiempo requiere procesos rigurosos de control de calidad y una gestión eficiente del flujo de trabajo.
Estas prácticas organizativas garantizan que los conjuntos de datos cumplan con los estándares necesarios para un aprendizaje automático confiable, al mismo tiempo que permiten gestionar los factores humanos que influyen en la coherencia y consistencia de las anotaciones.
Workflows with revisores
Los enfoques conocidos como etiquetado por consenso consisten en que varios anotadores trabajen sobre las mismas imágenes, de modo que sus resultados puedan compararse y analizarse colectivamente.
Las discrepancias se examinan y se resuelven mediante debate grupal o arbitraje por parte de expertos, lo que ayuda a detectar errores sistemáticos y mejorar la fiabilidad global del conjunto de datos a través de una validación cruzada colectiva.
Las estructuras jerárquicas de validación organizan los equipos en múltiples niveles: los anotadores junior producen las anotaciones iniciales, mientras que los revisores sénior verifican y corrigen su trabajo.
Este sistema fomenta el desarrollo de competencias, mantiene un alto nivel de calidad y promueve la transferencia de conocimiento dentro del equipo.
Las medidas de acuerdo entre anotadores - como el coeficiente Kappa de Cohen (para dos anotadores) o el coeficiente de Fleiss (para varios) - permiten cuantificar el nivel de coherencia entre las anotaciones.
Estas métricas estadísticas ayudan a identificar las áreas donde las directrices necesitan mayor claridad y sirven para monitorizar la evolución de la consistencia a lo largo del tiempo.
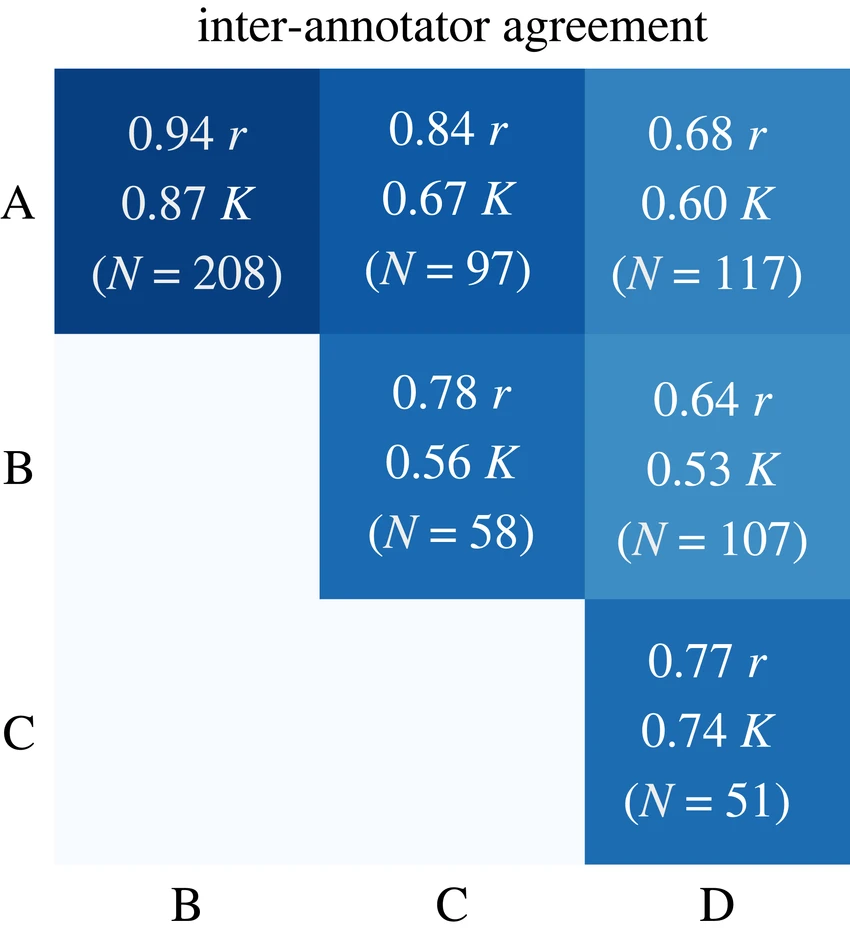
Un valor de acuerdo superior a 0,8 se considera, en general, aceptable para la mayoría de los proyectos de producción, mientras que las áreas críticas, como la imaginología médica, suelen requerir umbrales aún más altos.
Un seguimiento regular de estos indicadores permite a los gestores de proyecto detectar necesidades de formación, ajustes en las directrices o posibles desviaciones de calidad a lo largo del tiempo.
Los procesos de validación ciega implican la participación de revisores independientes, quienes evalúan un subconjunto de anotaciones sin consultar las etiquetas originales.
Controles de calidad automáticos
Los sistemas automatizados de control de calidad utilizan algoritmos capaces de detectar anotaciones anómalas o inconsistentes con respecto a las tendencias generales, y reportan las anomalías para su revisión humana.
Estas verificaciones automáticas complementan la supervisión manual, permitiendo identificar errores que de otro modo podrían pasar desapercibidos. Las reglas de coherencia garantizan que las etiquetas cumplan con las convenciones del proyecto, evitando términos ambiguos, atributos incorrectos o inconsistencias geométricas.
Las herramientas también pueden comprobar que las anotaciones cubran todos los objetos visibles o que las proporciones entre las etiquetas sean lógicas y coherentes. El seguimiento estadístico del rendimiento de la anotación - incluyendo velocidad, tasa de error, coherencia y precisión por clase - permite detectar rápidamente problemas antes de que afecten grandes volúmenes de datos.
Un cambio repentino en el ritmo o la calidad del trabajo puede indicar fallos en la herramienta, fatiga del anotador o malinterpretaciones de las instrucciones. Los sistemas de retroalimentación en tiempo real proporcionan comentarios inmediatos sobre los errores más comunes, ayudando a los anotadores a corregir sus prácticas durante el proceso, en lugar de hacerlo después.
Las métricas automatizadas de calidad pueden incluir la precisión de los contornos, la verificación del número de objetos anotados o el análisis de la distribución de clases, asegurando que el conjunto de datos permanezca equilibrado entre categorías y escenarios.
Plataformas y herramientas de anotación de imágenes
Elegir la herramienta de anotación adecuada tiene un gran impacto en la eficiencia, la calidad del control y la colaboración del equipo. Las plataformas modernas ofrecen una amplia variedad de funcionalidades que pueden adaptarse a casos de uso específicos, desde tareas simples de anotación en forma de cajas delimitadoras hasta flujos de trabajo multimodales complejos que integran múltiples tipos de datos.
🧩 Soluciones de código abierto
Label Studio es una plataforma flexible y personalizable que admite diversos tipos de datos e interfaces de anotación. Su naturaleza open source permite a los equipos modificar el software según sus necesidades específicas, beneficiándose al mismo tiempo de las contribuciones de la comunidad y de actualizaciones periódicas.
Label Studio admite numerosos tipos de anotaciones: cajas delimitadoras, polígonos, puntos clave, clasificación de texto, entre otros. Además, puede integrarse fácilmente en los flujos de trabajo de aprendizaje automático y en sistemas de control de calidad automatizados.
CVAT (Computer Vision Annotation Tool) es especialmente adecuado para la anotación de vídeo y los flujos de trabajo colaborativos, gracias a sus funcionalidades diseñadas para el seguimiento de objetos y la gestión de datos temporales en secuencias de imágenes. La plataforma incorpora mecanismos de control de calidad y permite gestionar de forma eficiente equipos distribuidos.
LabelImg ofrece una solución simple e intuitiva para anotaciones con cajas delimitadoras destinadas a la detección de objetos. Aunque es menos completa que Label Studio o CVAT, su ligereza la convierte en una herramienta ideal para proyectos rápidos o tareas básicas de anotación de imágenes.
💡 Las soluciones de código abierto ofrecen la ventaja de eliminar los costos de licencia y proporcionar total libertad de personalización. Sin embargo, su configuración y mantenimiento requieren capacidades técnicas internas, por lo que es importante contar con personal especializado para su implementación y soporte continuo.
-hand-innv.png)
Optimización de procesos
Las estrategias de aprendizaje activo (active learning) seleccionan las imágenes más informativas para anotar, maximizando las mejoras en el rendimiento del modelo por cada hora de anotación invertida.
Los algoritmos identifican las zonas de mayor incertidumbre del modelo y priorizan las muestras que aportan mayor valor al proceso de aprendizaje. Los enfoques de transferencia de conocimiento (transfer learning) reducen la necesidad de anotación aprovechando modelos previamente entrenados en conjuntos de datos generales.
Un modelo ajustado de esta manera, incluso con un conjunto de datos pequeño y específico, suele lograr mejores resultados que un modelo entrenado desde cero con una gran cantidad de anotaciones.
Las técnicas de aumento de datos (data augmentation) —como la rotación, el recorte, la variación de color o la adición de ruido— permiten enriquecer artificialmente los conjuntos de datos existentes, incrementando la diversidad y la robustez del modelo, sin necesidad de generar nuevas anotaciones.
Los bucles de mejora continua utilizan la retroalimentación de los modelos en producción para ajustar las directrices y los estándares de calidad. La evaluación periódica del rendimiento del modelo ayuda a identificar las áreas donde nuevas anotaciones pueden ser más beneficiosas, optimizando así la eficiencia global del proceso de entrenamiento.



