Etiquetage d'images : Guide complet sur les données d'entraînement en Computer Vision

💡 A retenir
- L'étiquetage d’images consiste à ajouter des balises, des boîtes englobantes ou des catégories / classifications à des données visuelles afin d’entraîner des modèles de Machine Learning pour la reconnaissance d’objets et les tâches de vision par ordinateur.
- Une annotation de qualité exige que chaque objet soit entièrement identifié, que les boîtes soient précises, que les noms de labels soient cohérents et que les instructions de marquage soient uniformes sur l’ensemble du jeu de données.
- Les méthodes modernes d’annotation d’images combinent annotation manuelle, outils assistés par IA et flux de travail automatisés pour accroître la productivité tout en maintenant une haute précision sur de grands volumes de données.
- Les applications les plus courantes en IA incluent les véhicules autonomes, l’imagerie médicale,ou encore les systèmes de sécurité, qui reposent tous sur une détection et une classification précises des objets.
- Un contrôle qualité rigoureux, une coordination efficace des équipes et des plateformes d’annotation spécialisées sont essentiels pour gérer avec succès des projets d’annotation à grande échelle.
⚙️ Ce qui alimente vraiment la vision par ordinateur ("Computer Vision") moderne
Vous êtes-vous déjà demandé ce qui alimente réellement les systèmes de vision par ordinateur d’aujourd’hui ? Ce ne sont ni les gros titres vantant une "IA qui prépare elle-même les données annotées", ni l’illusion que des micro-tâches distribuées puissent produire, à elles seules, des données de haute qualité à grande échelle. La réalité est beaucoup plus structurée - et profondément humaine.
Derrière chaque avancée majeure en vision artificielle se cache une base de données méticuleusement annotées. Des voitures autonomes naviguant dans des rues encombrées aux systèmes médicaux détectant des tumeurs sur des scanners CT, la précision de ces technologies dépend entièrement de la qualité de leurs données d’entraînement.
En bref, l’annotation d’images transforme l’information visuelle brute en ensembles de données structurés, permettant aux modèles d’apprentissage automatique de reconnaître des motifs, de détecter des objets et de prendre des décisions intelligentes.
🧠 De la classification manuelle aux workflows hybrides
Aujourd’hui, le processus d’annotation d’images a considérablement évolué : il ne s’agit plus simplement de classer manuellement des photos, mais de déployer des workflows sophistiqués intégrant outils d’assistance IA et contrôles qualité automatisés. Les Data Scientists doivent relever un défi constant : créer des jeux de données massifs et homogènes tout en garantissant cohérence et précision sur des milliers, voire des millions d’images.
👉 Ce guide complet vous expliquera tout ce qu’il faut savoir sur l'étiquetage d'images, des notions de base aux opérations à grande échelle.
🚀 Que vous soyez…
… en train de construire votre premier modèle de vision par ordinateur, ou de superviser des équipes d’annotation pour des systèmes en production, comprendre les principes et bonnes pratiques de l’annotation de données visuelles est essentiel à la réussite de vos projets. Découvrons ensemble comment créer les données annotées qui alimentent les applications d’IA les plus avancées d’aujourd’hui.
🔍 Qu’est-ce que l'étiquetage d’images ?
L'étiquetage ou annotation d’images est le processus consistant à ajouter des annotations significatives aux images (ou "métadonnées") pour constituer des données d’entraînement destinées à des modèles d’apprentissage supervisé.
Cette étape fondamentale du pipeline de vision par ordinateur fait intervenir des annotateurs humains ou des systèmes automatisés chargés d’identifier et de marquer des objets, des caractéristiques ou des structures présentes dans les images afin d’apprendre aux algorithmes à reconnaître et interpréter le monde visuel.
L’objectif va bien au-delà d’un simple étiquetage : chaque annotation crée un langage visuel que les réseaux neuronaux utilisent pour comprendre la relation entre pixels et concepts réels. Chaque étiquette devient un exemple pédagogique qui aide les modèles à identifier des motifs, formuler des prédictions et classer de nouvelles images avec confiance.
🧩 Types de tâches d’annotation d’images
Classification d’images
C’est la forme la plus simple d’annotation : l’annotateur attribue une ou plusieurs étiquettes à une image entière. Cette approche considère chaque image comme une unité complète, en se concentrant sur son contenu global plutôt que sur la localisation d’objets spécifiques.
- La classification binaire répond à des questions simples : « Oui / Non », par exemple : un défaut est-il présent sur ce produit ?
- La classification multi-classe attribue une seule catégorie parmi plusieurs (chat, chien, oiseau, etc.).
- La classification multi-étiquettes permet plusieurs catégories simultanées (une photo peut contenir à la fois une voiture et une personne).
Les applications incluent la modération de contenu, le diagnostic médical (radiographies normales/anormales), ou encore la catégorisation d’images produits pour la recherche et la recommandation.
💡 La clé du succès réside dans des définitions de classes claires et sans ambiguïté, ainsi que dans une formation homogène des annotateurs.
Détection d’objets
La détection d’objets va au-delà de la classification globale : elle identifie et localise chaque objet présent dans l’image au moyen de boîtes englobantes (bounding boxes).
Chaque boîte, définie par des coordonnées (x, y, largeur, hauteur), sert à la fois d’indicateur de position et d’étiquette de classe.
Une même image peut contenir plusieurs objets, parfois partiellement visibles ou se chevauchant.
Cette méthode permet aux modèles de répondre à deux questions fondamentales :
« Quels objets sont présents ? » et « Où se trouvent-ils ? ».
Les applications vont de la conduite autonome (voitures, piétons, panneaux) à la vidéosurveillance, à la gestion des stocks et à l’analyse sportive.
💡 La précision du tracé des boîtes influence directement la performance du modèle : des boîtes serrées et cohérentes fournissent de meilleurs signaux d’apprentissage.

Segmentation d'instance
La segmentation d’instances améliore la précision de l’annotation en créant des contours polygonaux détaillés autour de chaque objet individuel, offrant une exactitude au niveau du pixel qui dépasse les capacités des simples boîtes englobantes rectangulaires.
Cette technique permet aux modèles de comprendre la forme exacte des objets et de distinguer les instances qui se chevauchent au sein d’une même catégorie.
Contrairement aux boîtes englobantes, qui incluent souvent des pixels d’arrière-plan, les annotations polygonales suivent fidèlement les contours précis des objets irréguliers.
Cette approche devient essentielle - et véritablement transformatrice - lorsqu’il s’agit de formes complexes telles que des vêtements, des objets organiques ou des éléments architecturaux, pour lesquels les limites rectangulaires incluraient une part importante de zones non pertinentes.
La différence entre segmentation d’instances et segmentation sémantique réside dans la séparation des objets. La segmentation d’instances considère chaque objet comme une entité unique, ce qui permet aux modèles de compter et de suivre individuellement chaque instance. Ainsi, une scène de foule peut contenir plusieurs personnes, chacune recevant sa propre annotation polygonale et un identifiant distinct.

Les applications d’imagerie médicale reposent largement sur la segmentation d’instances pour délimiter précisément les contours des tumeurs, distinguer les organes et classifier les tissus - une précision dont dépendent directement les résultats cliniques des patients. Les systèmes de robotique utilisent ces contours détaillés des objets pour réaliser des manipulations et des saisies avec une grande exactitude.
En agriculture de précision, la segmentation permet d’analyser chaque plante individuellement, d’identifier les zones malades et d’optimiser les traitements. Enfin, l’analyse d’imagerie satellite s’appuie sur les annotations polygonales pour cartographier les empreintes de bâtiments, les parcelles agricoles et les caractéristiques environnementales.
👉 La nature particulièrement exigeante de l’annotation par polygones nécessite des outils spécialisés et des annotateurs formés, conscients de l’importance d’un tracé précis des contours. Le contrôle qualité devient alors crucial, car de légères erreurs dans les sommets d’un polygone peuvent avoir un impact significatif sur les performances du modèle.
Segmentation sémantique
La segmentation sémantique représente la forme la plus complète d'étiquetage d'images. Elle consiste à classer chaque pixel d’une image selon des catégories prédéfinies. Cette annotation au niveau du pixel génère des cartes de prédiction denses, offrant une compréhension globale de la scène sans pour autant distinguer les instances individuelles d’un même objet.
Des masques colorés sont utilisés pour différencier les catégories ou types de matériaux à travers toute l’image : les routes peuvent apparaître en gris, la végétation en vert, les véhicules en rouge et le ciel en bleu. Ce procédé permet aux modèles de comprendre les relations spatiales et les propriétés des matériaux dans des environnements complexes.

La segmentation sémantique est la forme la plus complète d’annotation d’images, car elle demande de classer chaque pixel selon des catégories prédéfinies. Les masques colorés attribuent différentes teintes aux classes d’objets (routes en gris, végétation en vert, véhicules en rouge, ciel en bleu), créant une carte complète de la scène. Cette méthode permet aux modèles de comprendre les relations spatiales et les propriétés des matériaux dans des environnements complexes.
Elle est essentielle pour la navigation autonome, la planification urbaine, la surveillance environnementale et l’imagerie médicale, où la précision des contours influence directement les résultats.
💡 Son principal défi : maintenir la cohérence sur des images vastes et complexe - les annotateurs doivent prendre des milliers de décisions au pixel près, avec un contrôle qualité rigoureux pour garantir une annotation complète et exacte.
Bonnes pratiques en étiquetage d'images
Créer des jeux de données de haute qualité nécessite une approche systématique garantissant cohérence, précision et exhaustivité dans toutes les tâches d’annotation. Des stratégies d'étiquetage éprouvées constituent la base de tout projet de vision par ordinateur réussi et aident les équipes à éviter les erreurs courantes susceptibles de nuire aux performances des modèles.
Annotation complète des objets
Le principe d’annotation complète exige que les annotateurs identifient et marquent toutes les occurrences des objets cibles dans chaque image, quelle que soit leur taille, leur visibilité ou leur complexité.
Cette approche globale permet d’éviter les erreurs de type faux négatif, où les modèles ne reconnaissent pas certains objets simplement parce que des instances similaires ont été oubliées pendant l’entraînement.
Une couverture cohérente de l’ensemble du jeu de données garantit que les modèles apprennent à reconnaître les objets dans divers contextes et conditions. Une annotation partielle crée de la confusion dans les algorithmes d’apprentissage automatique, qui peuvent interpréter les objets non annotés comme faisant partie de l’arrière-plan et ensuite ignorer des objets similaires en conditions réelles.
Les objets cachés ou partiellement visibles demandent une attention particulière. Les petits objets, même flous ou éloignés, doivent être annotés pour renforcer la robustesse du modèle à différentes échelles et conditions visuelles.
Les objets occlus, dont seule une partie est visible, nécessitent une estimation complète de leurs limites, comme si l’objet entier était présent.
Un exemple concret issu de la détection de panneaux routiers illustre ce principe : les projets d’annotation doivent inclure tous les panneaux visibles, des grands panneaux d’autoroute aux petits panneaux partiellement masqués par la végétation. Omettre les plus petits ou les panneaux partiellement visibles apprendrait au modèle à ignorer ces indicateurs critiques lors de son déploiement réel.
L’exigence d’exhaustivité s’étend également aux cas "limites" (ou "edge cases") et aux présentations inhabituelles, souvent perçus comme secondaires mais représentant des exemples d’apprentissage précieux. Ces situations complexes font souvent la différence entre des modèles efficaces en laboratoire et ceux performants dans des environnements réels et imprévisibles.
Définition précise des contours
Un positionnement précis des contours constitue la pierre angulaire de la détection d’objets et de l’entraînement à la segmentation. Des boîtes englobantes serrées, qui minimisent l’espace vide tout en incluant complètement les objets cibles, fournissent les signaux d’apprentissage optimaux permettant aux modèles de comprendre l’étendue et la position des objets.
L’objectif est donc de trouver un équilibre entre l’inclusion complète de l’objet et la réduction du bruit de fond. Les boîtes doivent englober toutes les parties visibles de l’objet sans inclure inutilement des pixels d’arrière-plan. Cette précision devient critique lorsque les objets sont proches ou se chevauchent dans la scène.

L’inclusion complète de l’objet prime sur les considérations esthétiques : même lorsqu’un objet est partiellement coupé par les bords de l’image, la boîte doit s’étendre à toutes les parties visibles, plutôt que de créer des limites artificiellement resserrées susceptibles d’induire le modèle en erreur.
Les objets occlus représentent un défi particulier : les annotateurs doivent estimer les contours complets à partir des portions visibles. Dans certains cas, plutôt que de dessiner une boîte uniquement autour des parties visibles, la bonne pratique consiste à projeter l’étendue probable complète pour fournir au modèle des attentes réalistes de taille et de forme.
Les annotations qui se chevauchent sont acceptables lorsque les objets se recouvrent réellement dans l’espace tridimensionnel. Plusieurs objets partageant une même zone d’image doivent chacun recevoir leur propre limite, même si cela crée des superpositions reflétant la réalité spatiale de scènes complexes.
Nommage précis des étiquettes
Le niveau de spécificité des catégories d’étiquettes a un impact direct sur la flexibilité du modèle et sur les possibilités de déploiement futur. Des catégories plus fines, capturant des distinctions significatives, permettent des applications plus sophistiquées tout en gardant la possibilité de regrouper les classes ultérieurement pour des besoins de catégorisation plus larges.
Plutôt que d’utiliser des étiquettes génériques comme « chien », une approche d’annotation efficace privilégie des classifications spécifiques telles que « golden_retriever », « labrador » ou « berger_allemand ».
Cette granularité permet aux modèles d’apprendre des distinctions fines utiles à des applications spécialisées, tout en conservant la possibilité de regrouper ces sous-classes sous une catégorie générale (« chien ») si nécessaire.
Les considérations de flexibilité future favorisent donc une approche spécifique plutôt que générale. Transformer une catégorie large en sous-catégories précises nécessite une réannotation complète du jeu de données, tandis que l’inverse (fusionner des labels spécifiques en catégories générales) peut se faire aisément pendant l’entraînement du modèle.
Une terminologie cohérente sur l’ensemble du jeu de données évite les confusions et garantit que tous les membres de l’équipe comprennent exactement la signification de chaque label. Des conventions de nommage standardisées doivent prendre en compte les variations, abréviations ou cas particuliers susceptibles d’apparaître dans des projets d’annotation à grande échelle.
L’expertise métier joue également un rôle important dans la définition des hiérarchies de labels et du niveau de spécificité adéquat. Par exemple, les projets d’imagerie médicale nécessitent une terminologie anatomique précise, tandis que les applications en agriculture requièrent l’identification de variétés spécifiques de cultures - un détail qui peut sembler superflu pour un annotateur non expert, mais essentiel pour un déploiement efficace du modèle.
Rédiger des instructions d'annotation claires
Des consignes d’annotation complètes et précises constituent la base de jeux de données cohérents et de haute qualité, garantissant ainsi la fiabilité des performances des modèles. Ces documents doivent aborder les cas limites ("edge cases"), les situations ambiguës et les normes de qualité afin de maintenir une uniformité entre les annotateurs et au fil des sessions d’annotation.
Une documentation détaillée doit couvrir les situations courantes rencontrées par les annotateurs, en apportant des instructions spécifiques pour gérer les contours flous, les occlusions partielles et les objets appartenant à plusieurs catégories. Des lignes directrices écrites empêchent les interprétations incohérentes de cas complexes susceptibles d’introduire des erreurs dans le jeu de données.
Les exemples visuels renforcent ces instructions en illustrant les approches correctes et incorrectes d’annotation sur des scénarios représentatifs. Des comparaisons avant / après aident les annotateurs à saisir la différence entre un marquage acceptable et une erreur typique, réduisant ainsi les fautes et améliorant la qualité globale des annotations.
La cohérence d’équipe exige que tous les annotateurs respectent les mêmes standards et procédures, indépendamment de leur expérience ou de leurs préférences personnelles. Des sessions de formation régulières et des mises à jour des consignes permettent de maintenir la qualité au fur et à mesure de l’évolution des projets et de l’apparition de nouveaux cas d’usage.
L’amélioration continue des consignes, fondée sur l’analyse des erreurs courantes et sur l’évolution des besoins du projet, aide les équipes à s’adapter tout en maintenant la cohérence historique. Des revues périodiques de la qualité des annotations permettent d’identifier les points nécessitant clarification ou révision afin de corriger les problèmes récurrents.
Méthodes "modernes" d'annotation d'images pour l'IA
L’annotation manuelle traditionnelle repose sur des annotateurs formés qui dessinent eux-mêmes les boîtes englobantes, créent des polygones et attribuent des étiquettes en fonction de leur interprétation visuelle et de leur expertise métier.
Cette méthode offre le plus haut niveau de précision, notamment pour les scènes complexes et les cas particuliers qui mettent à l’épreuve les systèmes automatisés.
L’intelligence humaine excelle dans les situations ambiguës, les présentations inhabituelles d’objets et les décisions contextuelles qui nécessitent une réflexion au-delà de la simple reconnaissance de motifs. Les annotateurs expérimentés savent différencier des objets similaires, interpréter des occlusions partielles et prendre des décisions fines sur des cas limites qui perturberaient un algorithme.
Cependant, cette approche est chronophage, surtout pour les grands ensembles de données et les tâches complexes. Chaque image peut demander plusieurs minutes d’attention, en particulier pour les annotations de segmentation détaillées ou les scènes contenant de nombreux objets aux contours peu nets.
Le contrôle qualité dans les workflows manuels repose souvent sur un système de validation à plusieurs niveaux, où des annotateurs seniors vérifient le travail de leurs pairs ou des membres plus juniors. Des mesures d’accord inter-annotateurs (comme le coefficient Kappa de Cohen) permettent de repérer les incohérences et de fournir des retours pour améliorer continuellement la précision.
💡 Malgré le temps et les coûts engagés, l’annotation manuelle demeure la référence absolue pour constituer des jeux de données de référence (“ground truth”), en particulier dans les domaines où la précision est critique ou lorsque les outils automatisés manquent de données d’entraînement adaptées.
Annotation assistée par IA
Les approches modernes assistées par l’intelligence artificielle exploitent des modèles de machine learning pour générer des annotations initiales, ensuite validées, corrigées et affinées par des annotateurs humains. Cette méthode hybride réduit considérablement le temps de production tout en conservant les bénéfices de la supervision humaine.
Les workflows de pré-annotation commencent par l’analyse des images non étiquetées à l’aide de modèles pré-entraînés, qui produisent des boîtes englobantes, des classifications ou des masques de segmentation. Les annotateurs vérifient ensuite ces propositions automatiques, corrigent les erreurs et ajoutent les objets oubliés.
Les outils modernes d’annotation intègrent désormais des techniques avancées comme Segment Anything 2 (Meta), capable de générer des contours précis d’objets avec un minimum d’intervention humaine. Ces modèles fondamentaux comprennent des concepts visuels généraux et peuvent suggérer des masques de segmentation très précis que les annotateurs n’ont plus qu’à valider ou ajuster.
Les gains d’efficacité sont considérables : de nombreuses équipes constatent une réduction de 70 à 95 % du temps d’annotation par rapport aux approches purement manuelles. Cette accélération permet de créer des jeux de données beaucoup plus grands, dans des délais et budgets réalistes.
Les systèmes human-in-the-loop optimisent la complémentarité entre la rapidité des machines et la précision des humains. Les annotateurs se concentrent ainsi sur les cas complexes, tandis que les algorithmes traitent les tâches répétitives - maximisant à la fois l’efficacité et la qualité des projets d’annotation à grande échelle.
Annotation entièrement automatisée
L’annotation automatisée représente l’avant-garde de la création de jeux de données, utilisant des modèles fondamentaux et des systèmes d’IA avancés capables d’étiqueter des milliers d’images sans intervention humaine directe. Bien qu’encore limitée à certains cas d’usage, cette approche montre un potentiel croissant pour des domaines précis.
Les modèles fondamentaux pré-entraînés sur d’immenses ensembles de données peuvent reconnaître des objets courants et générer des labels pour de nouvelles images grâce à leur large base de connaissances. Ces systèmes excellent pour les objets standards dans des contextes typiques, mais peuvent rencontrer des difficultés avec les domaines spécialisés ou les présentations atypiques.
La génération de données synthétiques constitue une autre méthode automatisée : des environnements virtuels produisent des images réalistes accompagnées de labels parfaits, connus à l’avance. Cette approche est particulièrement utile lorsque la collecte de données réelles est difficile ou coûteuse (ex. : maladies rares, conditions météorologiques extrêmes).
Les algorithmes d’apprentissage actif (active learning) identifient quant à eux les images les plus utiles à annoter pour maximiser les progrès du modèle par heure d’effort investi, optimisant ainsi l’utilisation des ressources d’annotation.
Les avantages économiques de l’annotation automatisée deviennent évidents dans les projets à grande échelle, où l’annotation manuelle serait prohibitive. Cependant, une validation qualité rigoureuse demeure indispensable pour s’assurer que les labels produits atteignent le niveau requis pour l’entraînement fiable des modèles.
💡 Les limites actuelles concernent la spécialisation et l'expertise (médecine, légal, etc.) : les systèmes automatisés formés sur des ensembles de données génériques peuvent ne pas comprendre les termes ou objets propres à un domaine spécifique. Une vérification statistique de précision aide les équipes à déterminer quand les labels automatiques sont suffisants et quand une intervention humaine reste nécessaire.
Contrôle qualité et gestion des équipes
Maintenir une précision d’annotation élevée au sein de grandes équipes sur de longues périodes nécessite des processus de contrôle qualité rigoureux et une gestion efficace des flux de travail. Ces approches organisationnelles garantissent que les jeux de données respectent les standards nécessaires pour un apprentissage automatique fiable, tout en gérant les facteurs humains qui influencent la cohérence de l’annotation.
Multi-Reviewer Workflows
Les approches dites de labeling par consensus consistent à faire annoter les mêmes images par plusieurs personnes. Les divergences sont ensuite examinées et résolues collectivement, soit par discussion, soit via un arbitrage d’experts. Cette méthode aide à détecter les erreurs systématiques et améliore la fiabilité globale du jeu de données grâce à une validation croisée collective.
Les structures hiérarchiques de validation organisent les équipes en plusieurs niveaux : les annotateurs juniors produisent les annotations initiales, tandis que les réviseurs seniors vérifient et corrigent leur travail. Ce système favorise la montée en compétence tout en maintenant un haut niveau de qualité et de transmission du savoir au sein de l’équipe.
Les mesures d’accord inter-annotateurs (telles que le coefficient Kappa de Cohen pour deux annotateurs, ou celui de Fleiss pour plusieurs) permettent de quantifier la cohérence des annotations. Ces statistiques aident à repérer les zones où les consignes doivent être clarifiées et servent à suivre l’évolution de la cohérence au fil du temps.
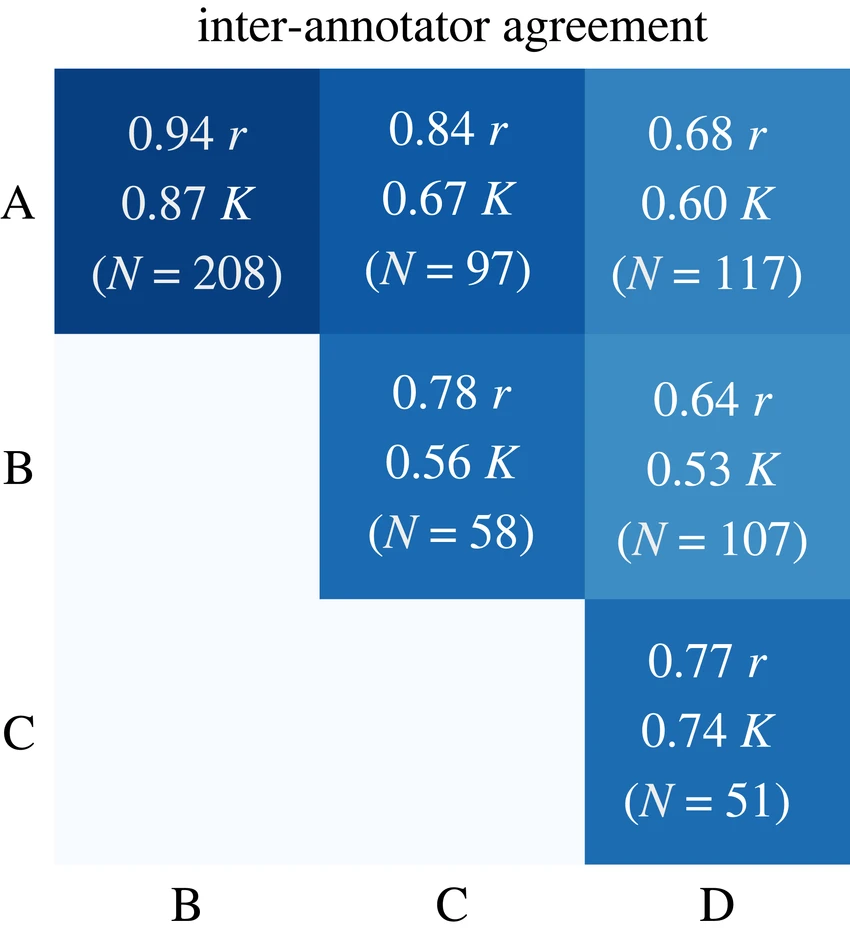
Un taux d’accord supérieur à 0,8 est généralement considéré comme acceptable pour la plupart des projets de production, tandis que les domaines critiques (comme l’imagerie médicale) nécessitent souvent des seuils encore plus élevés. Un suivi régulier de ces indicateurs permet aux chefs de projet de détecter les besoins en formation ou les ajustements nécessaires dans les consignes.
Les processus de validation en aveugle impliquent des réviseurs indépendants qui évaluent un sous-ensemble d’annotations sans consulter les labels originaux. Cette approche permet d’obtenir une évaluation impartiale et de repérer les biais systématiques ou les dérives progressives de qualité au fil du temps.
Vérifications automatiques de qualité
Les systèmes de contrôle qualité automatisés exploitent des algorithmes capables de repérer des annotations anormales ou incohérentes par rapport aux tendances générales, et de signaler les anomalies pour une revue humaine. Ces vérifications automatisées complètent la supervision manuelle en détectant des erreurs qui pourraient autrement passer inaperçues.
Les règles de cohérence garantissent que les labels respectent les conventions du projet - par exemple, éviter les termes ambigus, les attributs manquants ou les incohérences géométriques. Les outils peuvent aussi vérifier que les annotations couvrent la totalité des objets visibles ou que les proportions restent logiques.
Le suivi statistique des performances d’annotation (vitesse, taux d’erreur, régularité, précision par classe) permet d’identifier rapidement les problèmes avant qu’ils n’affectent des volumes importants de données. Un changement soudain de rythme ou de qualité peut signaler un problème d’outil, une fatigue annotateur ou un malentendu dans les consignes.
Les systèmes de retour en temps réel (disponibles dans les plateformes d'annotation de données les plus avancées) offrent un retour immédiat sur les erreurs courantes, aidant les annotateurs à corriger leurs pratiques pendant le processus plutôt qu’après. En outre, les métriques automatisées de qualité peuvent inclure la précision des contours, la vérification du nombre d’objets annotés, ou l’analyse de la distribution des classes pour s’assurer que le jeu de données reste équilibré entre les catégories et les scénarios.
Outils et plateformes d’annotation d’images
Le choix du bon outil d’annotation a un impact majeur sur l’efficacité, la qualité du contrôle et la collaboration des équipes.Les plateformes modernes proposent des fonctionnalités variées, adaptées à des cas d’usage spécifiques - de la simple annotation en boîte englobante aux workflows multimodaux complexes intégrant plusieurs types de données.
Open Source Solutions
Label Studio est une plateforme flexible et personnalisable, prenant en charge différents types de données et d’interfaces d’annotation. Sa nature open source permet aux équipes d'adapter le logiciel selon leurs besoins spécifiques tout en profitant des contributions de la communauté et des mises à jour régulières. La version "Community" de l'outil, gratuite, permet en outre de maîtriser les coûts.
Label Studio supporte de nombreux types d’annotations : boîtes englobantes, polygones, points clés, classification de texte, etc. De plus, elle s’intègre facilement aux pipelines de machine learning et aux systèmes de contrôle qualité automatisé.
CVAT (Computer Vision Annotation Tool) est particulièrement adapté à l’annotation vidéo et aux workflows collaboratifs, grâce à des fonctionnalités conçues pour les données temporelles et le suivi d’objets sur plusieurs images. La plateforme intègre des mécanismes de contrôle qualité et prend en charge les équipes distribuées.
Enfin, LabelImg propose une solution simple et intuitive pour les annotations en boîtes englobantes destinées à la détection d’objets. Moins complète que Label Studio ou CVAT, sa légèreté en fait un outil idéal pour les projets rapides ou les tâches basiques d’annotation d’images.
💡 Les solutions open source présentent l’avantage de supprimer les coûts de licence et d’offrir une liberté totale de personnalisation. En revanche, leur mise en place et maintenance nécessitent des compétences techniques internes.
Plateformes commerciales
Roboflow fournit une plateforme complète pour la vision par ordinateur, combinant annotation, entraînement de modèles et déploiement au sein d’un même environnement.
Son workflow intégré permet de passer rapidement des images brutes à un modèle opérationnel. Parmi ses fonctionnalités : contrôle qualité automatisé, gestion de versions de datasets, et suivi de l’impact de la qualité d’annotation sur la performance du modèle.
Azure Machine Learning propose un service de labellisation cloud intégrant des fonctionnalités d’assistance par IA grâce à des modèles pré-entraînés. Son intégration native avec l’écosystème Azure (stockage, calcul, déploiement) en fait une solution fluide pour les environnements Microsoft.
Amazon SageMaker Ground Truth offre une solution d’annotation au sein de l’écosystème AWS, avec des outils avancés de gestion de main-d’œuvre. Il permet de combiner des annotateurs internes avec du travail externalisé, tout en intégrant des mécanismes de contrôle qualité et d’automatisation du workflow.
Ces plateformes commerciales incluent souvent des fonctionnalités d’entreprise essentielles :
- gestion des droits et accès,
- conformité réglementaire,
- support dédié et
- certifications de sécurité (ISO, SOC, HIPAA, …).
Elles conviennent donc particulièrement aux organisations manipulant des données sensibles ou opérant dans des secteurs réglementés.
Outils spécialisés
Les applications d’imagerie médicale nécessitent des outils d’annotation adaptés aux formats DICOM et aux flux de travail radiologiques. Ces plateformes gèrent la terminologie clinique et les coordonnées anatomiques spécifiques aux données médicales.
Les projets de véhicules autonomes reposent sur des outils capables de traiter des données complexes : nuages de points LiDAR, fusion de capteurs et boîtes 3D pour l’entraînement des systèmes de perception.
L’analyse d’imagerie satellite requiert des outils géospatiaux capables de gérer les projections géographiques, les coordonnées précises et les images de grande taille.
Ces plateformes permettent d’annoter des éléments à l’échelle territoriale : bâtiments, champs agricoles, routes, zones urbaines, etc.
Ces outils spécialisés offrent des gains d’efficacité considérables, car ils comprennent les besoins métiers, la terminologie, et les flux de travail propres à chaque domaine, là où les outils génériques atteignent leurs limites.
Cas d'usage concrets et applications réelles
L’annotation d’images trouve des applications dans de nombreux secteurs où la vision par ordinateur permet de résoudre des problèmes complexes et d’automatiser des prises de décision critiques. Ces exemples concrets illustrent la valeur tangible des jeux de données annotés avec précision.
Véhicules autonomes
Les voitures autonomes représentent l’un des cas d’usage les plus exigeants de la vision par ordinateur. Elles nécessitent des annotations précises pour les véhicules, les plaques d'immatriculation, les piétons, les panneaux de signalisation, les marquages au sol et les limites de voie. Le caractère critique de la sécurité impose un niveau d’exactitude extrêmement élevé et une couverture complète des cas particuliers.
Les systèmes de détection d’objets doivent identifier et suivre plusieurs éléments simultanément tout en anticipant leurs mouvements. Les boîtes englobantes servent à localiser les véhicules, tandis que les points clés marquent les phares, clignotants ou plaques d’immatriculation pour analyser le comportement routier.
La segmentation sémantique aide le véhicule à distinguer la chaussée, les trottoirs, les bâtiments ou la végétation pour planifier sa trajectoire. Les annotations 3D (issues des capteurs LiDAR) apportent la perception de la profondeur et permettent d’interpréter la scène en trois dimensions.
Des ensembles de tests couvrant toutes les conditions météo, les éclairages et les configurations routières inhabituelles (zones de travaux, véhicules d’urgence, routes non balisées) sont indispensables pour garantir la fiabilité des modèles en conditions réelles.
Imagerie médicale
Les applications médicales exigent le plus haut niveau de précision, car la qualité de l’annotation influe directement sur le diagnostic et le traitement des patients. Les annotations sont souvent réalisées par des radiologues ou cliniciens qualifiés, capables d’identifier les structures anatomiques et les anomalies pathologiques.
Les systèmes d’aide au diagnostic analysent les IRM, scanners et radiographies pour détecter des tumeurs, fractures ou lésions. Des annotations précises des contours permettent de mesurer la taille des lésions, leur évolution et la réponse au traitement.
La segmentation anatomique aide à délimiter les organes, classifier les tissus et mettre en évidence les anomalies. Ces annotations détaillées servent aussi à la planification chirurgicale et au suivi thérapeutique.
L’intégration dans les flux médicaux (dossiers médicaux électroniques) est essentielle pour que les cliniciens puissent accéder, annoter et partager les images dans leur environnement habituel. Enfin, les projets d’imagerie médicale doivent respecter des normes réglementaires strictes (comme la FDA), incluant la validation statistique, la documentation complète et l’évaluation de la variabilité entre annotateurs.
Vente en ligne, e-commerce
Les systèmes de reconnaissance de produits utilisent l’annotation d’images pour automatiser la gestion des stocks, la recherche visuelle et les recommandations personnalisées. Les applications de contrôle qualité identifient les défauts de fabrication, les erreurs d’emballage ou les dommages produits à l’aide d’inspections automatisées.
Des annotations précises des zones de défaut permettent d’entraîner des modèles capables de détecter ces problèmes de manière constante et rapide.
L’analyse du comportement client exploite les caméras en magasin pour étudier les parcours d’achat, les zones de chaleur ou les tendances démographiques. Les approches respectueuses de la vie privée privilégient des annotations comportementales anonymisées, sans identification personnelle.
Les systèmes de surveillance de marques détectent les logos, produits et placements publicitaires sur les réseaux sociaux ou dans les médias visuels. Une annotation fine des logos et éléments de marque permet de protéger les droits et d’analyser la visibilité marketing.
Enfin, la gestion automatisée des stocks repose sur la détection et la classification des produits sur les étagères, grâce aux boîtes englobantes et aux étiquettes de catégorie.
Sécurité et surveillance
Dans la sécurité, la vision par ordinateur permet la reconnaissance faciale pour le contrôle d’accès, la détection de menaces (armes, comportements suspects) et l’analyse de foule pour la gestion des urgences.
Les systèmes de détection d’objets identifient les menaces potentielles à partir de flux vidéo, tandis que les modèles d’analyse temporelle reconnaissent les séquences de comportements anormaux.
La segmentation sémantique est utilisée pour mesurer la densité de foule, analyser les flux de personnes et optimiser les plans d’évacuation. Ces outils aident les gestionnaires de sites à anticiper les risques et à intervenir plus efficacement.
Les considérations de protection de la vie privée sont essentielles : de nombreuses organisations intègrent des techniques d’anonymisation afin de concilier sécurité et conformité réglementaire (ex. RGPD).
Les systèmes de surveillance périmétrique combinent plusieurs capteurs — caméras optiques, infrarouges et capteurs de mouvement — pour une détection complète des intrusions et anomalies.
Passage à l'échelle et optimisation des opérations d'annotation IA
Les équipes internes d’annotation offrent une expertise métier et un contrôle qualité constant, mais exigent un investissement important en formation, infrastructure et management. Ce modèle convient aux organisations ayant des besoins d’annotation récurrents ou hautement spécialisés.
Les prestataires professionnels de labellisation apportent leur savoir-faire et leur capacité à monter rapidement en charge. Ils constituent une solution flexible et rentable pour les entreprises sans capacités internes ou devant livrer sous des délais courts.
Les plateformes de crowdsourcing, comme Amazon Mechanical Turk, permettent de distribuer les tâches à grande échelle à de nombreux contributeurs, réduisant les coûts pour certaines tâches simples. Cependant, le contrôle qualité y est plus difficile, nécessitant des procédures de validation robustes et des instructions claires. ℹ️ Cette approche reste efficace lorsque les exigences de qualité sont faibles ou modérées.
Les modèles hybrides combinent ces approches pour équilibrer coûts et qualité :
- équipes internes pour les tâches complexes,
- crowdsourcing pour les tâches simples,
- prestataires spécialisés pour la création initiale du dataset ou la maintenance continue.
Lors de la montée en charge, il faut anticiper :
- le temps de formation des nouveaux annotateurs,
- la charge de contrôle qualité accrue,
- et la complexité de communication qui croît avec la taille de l’équipe.
Des processus d’onboarding structurés et des outils de gestion de workflow clairs sont indispensables pour assurer la cohérence et la productivité.
-hand-innv.png)
Optimisation des processus
Les stratégies d’apprentissage actif (active learning) sélectionnent les images les plus informatives à annoter, maximisant ainsi les gains de performance du modèle pour chaque heure d’annotation investie. Les algorithmes identifient les zones d’incertitude du modèle et priorisent les échantillons qui apportent le plus de valeur à l’apprentissage.
Les approches de transfert de connaissances (transfer learning) réduisent les besoins d’annotation en exploitant des modèles pré-entraînés sur des jeux de données généraux. Un modèle ainsi ajusté sur un petit jeu de données spécifique obtient souvent de meilleurs résultats qu’un modèle entraîné de zéro avec beaucoup plus d’annotations.
Les techniques d’augmentation de données (rotation, recadrage, variation de couleur, bruit, etc.) permettent d’enrichir artificiellement les jeux de données existants.
Elles augmentent la diversité et la robustesse du modèle sans nécessiter de nouvelles annotations.
Les boucles d’amélioration continue exploitent les retours des modèles déployés pour ajuster les consignes et les standards de qualité. L’évaluation régulière des performances du modèle permet d’identifier les domaines où de nouvelles annotations seraient les plus bénéfiques.
Enfin, les outils d’automatisation ou d'orchestration du workflow d'étiquetage de données facilitent la coordination des tâches, le suivi de la progression et la gestion du contrôle qualité à grande échelle.
Ces systèmes peuvent :
- répartir automatiquement les tâches,
- surveiller la productivité,
- et signaler les problèmes de qualité en temps réel.



