¿Cómo creo y anoto un conjunto de datos para la IA? Todo lo que necesitas saber

Introducción: ¿qué es un conjunto de datos y cuál es su importancia para la inteligencia artificial?
Hoy vamos a hablar de un paso esencial, pero a menudo subestimado, en el proceso de desarrollo: la creación y recopilación de conjuntos de datos para Inteligencia Artificial (IA). Tanto si eres un profesional de los datos como un aficionado a la IA, esta guía tiene como objetivo ofrecerte consejos prácticos para crear un conjunto de datos sólido y fiable.
El aprendizaje automático (ML), una rama esencial de la Inteligencia Artificial, depende en gran medida de la calidad de los conjuntos de datos iniciales utilizados en los ciclos de desarrollo. Tener suficientes datos adaptados para aplicaciones específicas de aprendizaje automático es fundamental. Este artículo le brindará una descripción general de mejores prácticas para crear conjuntos de datos para el aprendizaje automático y su uso para tareas específicas. Comprenderá lo que se necesita para recopilar y generar los datos correctos para cada algoritmo de aprendizaje automático.
💡 Recuerda que la IA se basa en 3 pilares: Conjuntos de datos, el Potencia de cómputo Y el Patrones. Descubre en siguiendo este enlace cómo evaluar un modelo de aprendizaje automático.
1. Comprenda la importancia de un conjunto de datos de calidad para la IA
Cualquier proyecto de IA depende en gran medida de la calidad de datos sobre el que se entrena el modelo subyacente. Un conjunto de datos bien diseñado es para la IA lo que los buenos ingredientes son para un chef: esenciales para obtener resultados excepcionales. De hecho, un conjunto de datos de aprendizaje automático es un conjunto de datos que se utiliza para entrenar un modelo de aprendizaje automático. Por lo tanto, crear un buen conjunto de datos es un paso fundamental en el proceso de entrenamiento y evaluación de los modelos de aprendizaje automático. Es importante entender cómo generar datos para el aprendizaje automático y determinar qué datos se necesitan para crear un conjunto de datos completo y eficaz.
En la práctica, un conjunto de datos es:
- Una colección de datos consistentes que puede tener varios formatos (textos, números, imágenes, videos, etc.).
- Un conjunto en el que cada valor está asociado a un atributo y una observación, por ejemplo, datos sobre personas con atributos como la edad, el peso, la dirección, etc.
- Un conjunto coherente, que han sido objeto de comprobaciones para garantizar la validez de las fuentes de datos, para evitar trabajar con datos inexactos, sesgados o que no cumplan con las normas de propiedad intelectual.
Un conjunto de datos no es:
- Un conjunto simple y aleatorio de datos : los conjuntos de datos deben estructurarse y organizarse de manera lógica y coherente.
- Exento del control de calidad : la verificación y la validación de los datos son esenciales para garantizar su fiabilidad.
- Todavía utilizable en su estado original : con frecuencia, la limpieza y transformación de los datos son necesarias antes de su uso.
- Una fuente infalible : incluso los mejores conjuntos de datos pueden contener errores, problemas de calidad o sesgos que requieren análisis y corrección.
- Un conjunto estático : Un buen conjunto de datos puede requerir actualizaciones y revisiones para seguir siendo relevante y útil.
La calidad y el tamaño de un conjunto de datos desempeñan un papel decisivo en la precisión y el rendimiento del modelo de IA. En general, cuanto más fiables y de mayor calidad tengan los datos de un modelo, mejor será su rendimiento. Sin embargo, es importante encontrar un equilibrio entre la cantidad de datos almacenados para su procesamiento y los recursos humanos y de TI necesarios para procesarlos.

2. Defina el propósito de su conjunto de datos
Antes de empezar a crear un conjunto de datos, es decir, antes de sumergirse en la laboriosa fase de recopilación de datos, aclare el propósito de su IA. ¿Qué es lo que busca lograr? Esta definición guiará sus elecciones en términos de los tipos y el volumen de datos necesarios.
Obtención de datos: ¿debe utilizar un conjunto de datos existente, datos sintéticos o recopilar datos?
Al iniciar un desarrollo de IA sin tener datos, es útil recurrir a conjuntos de datos públicos de código abierto. Estos conjuntos de datos, que provienen de comunidades de código abierto u organizaciones públicas, ofrecen una amplia gama de información útil para ciertos casos de uso.
A veces, los científicos de datos recurren a datos sintéticos. ¿De qué se trata? Se trata de datos que se generan artificialmente, a menudo mediante algoritmos, para simular datos reales. Se utilizan en varios campos para entrenar y validar modelos cuando los datos reales son insuficientes, costosos de obtener o mantener la confidencialidad. Estos datos imitan las características estadísticas de los datos reales, lo que permite probar y perfeccionar los modelos de IA en un entorno controlado. Sin embargo, es preferible utilizar datos reales para evitar una discrepancia entre las características de los datos sintéticos y los datos reales (estas diferencias también se denominan «distorsiones»). Si bien son prácticos y relativamente sencillos de obtener, los datos sintéticos pueden hacer que los modelos de aprendizaje automático sean menos precisos o menos eficientes cuando se aplican a situaciones reales.
La importancia de la calidad de los datos...
Aunque los conjuntos de datos públicos o los datos sintéticos pueden proporcionar Perspectivas precioso, el recopilar sus propios datos, adaptada a sus necesidades específicas, suele ser más ventajosa. Sea cual sea la fuente de sus datos, hay una constante: la calidad de los datos y la necesito etiquetarlos correctamente para proporcionarles una capa de información semántica son aspectos importantes a tener en cuenta para su trabajo en el campo de la IA.
-hand-innv.png)
3. Recopilación de datos: un paso estratégico en el proceso de desarrollo de la IA
La recopilación de datos de formación es un paso fundamental en el proceso de desarrollo de la IA. Cuanto más minucioso y riguroso sea durante esta etapa, más eficaz será el algoritmo de aprendizaje automático. Por lo tanto, recopilar la mayor cantidad posible de datos relevantes y, al mismo tiempo, equilibrar su diversidad, representatividad y las capacidades de hardware y software es una tarea importante, aunque a menudo se pasa por alto.
Al crear y optimizar sus modelos de aprendizaje automático, su estrategia debe consistir enusa tus propios datos. Estos datos son naturales adaptado a sus necesidades específicas y representan la mejor manera de optimizar su modelo para los tipos de datos que encontrará en situaciones de la vida real. Según la antigüedad de su empresa, debe tener estos datos internamente, en el mejor de los casos, en lagos de datos o en varias bases de datos estructuradas y no estructuradas recopiladas a lo largo de los años.
Si bien la obtención de datos internamente es uno de los mejores enfoques, a diferencia de las multinacionales, las estructuras más pequeñas (especialmente las nuevas empresas) no siempre tienen a su disposición conjuntos de datos creados por miles de empleados. Por lo tanto, hay que ser ingenioso e imaginar otras formas de obtener los datos. Estos son dos métodos que han demostrado su eficacia:
El»Arrastrándose«y el»Desguace»
- El «arrastrándose» consiste en navegar por una gran cantidad de páginas web que pueden ser de su interés.
- El»Desguace«es el proceso de recopilación de datos de estas páginas.
Estas tareas, que pueden variar en complejidad, permiten recopilar varios tipos de conjuntos de datos, como texto sin formato, textos introductorios para modelos específicos, texto con metadatos para modelos de clasificación, texto multilingüe para modelos de traducción e imágenes con leyendas para modelos de entrenamiento de clasificación de imágenes o conversión de imagen a texto.
Utilice conjuntos de datos distribuidos por los investigadores
Es probable que otros investigadores ya se hayan interesado por problemas similares a los suyos. En este caso, es posible encontrar y usar los conjuntos de datos que crearon o usaron. Si estos conjuntos de datos están disponibles de forma gratuita en una plataforma de código abierto, puede recuperarlos directamente. De lo contrario, no dudes en ponerte en contacto con los investigadores para ver si están de acuerdo en compartir sus datos.
4. Limpieza y preparación de datos
Este paso consiste en compruebe su conjunto de datos para eliminar errores, lo duplica y lo estructura. Un conjunto de datos limpio es esencial para un aprendizaje eficaz de la IA.
Formatear, limpiar y reducir los datos
Para crear un conjunto de datos de calidad, hay tres pasos clave:
- Formato de datos, que consiste en realizar comprobaciones para garantizar la coherencia de los datos. Por ejemplo, ¿el formato de fecha de sus datos es el mismo para cada entrada?
- Limpieza de datos, que implica la eliminación de valores faltantes, erróneos o no representativos para mejorar la precisión del algoritmo.
- Reducción de datos, que consiste en reducir el tamaño del conjunto de datos mediante la eliminación de la información irrelevante o menos relevante.
Estos pasos son esenciales para obtener un conjunto de datos útil y optimizado en Machine Learning.
Preparación de los datos
Los conjuntos de datos suelen tener defectos que pueden afectar a la precisión y el rendimiento de los modelos de aprendizaje automático. Entre los problemas más comunes se incluyen Desequilibrio de clases (una clase predominante sobre otra), Los datos que faltan (lo que compromete la precisión y la generalización del modelo), El «ruido» (información incorrecta o irrelevante, como imágenes demasiado borrosas) y Valores atípicos (muy alta o muy baja, lo que distorsiona los resultados). Para abordar estos problemas, los científicos de datos deben limpiar y preparar los datos con antelación para garantizar la fiabilidad y la eficacia del modelo.
Aumento de datos
El »aumento de datos« (or Data Augmentation) es una técnica clave de aprendizaje automático para enriquecer un conjunto de datos. Consiste en crear nuevos datos a partir de los datos existentes mediante diversas transformaciones. Por ejemplo, en el procesamiento de imágenes, esto puede implicar cambiar la iluminación, girar o ampliar una imagen. Este método aumenta la diversidad de datos, lo que permite que un modelo de IA aprenda de ejemplos más variados y, por lo tanto, mejora su capacidad de generalización a nuevas situaciones.
Por encima de todo, aumentar los conjuntos de datos es una forma inteligente de aumentar la cantidad de datos de entrenamiento sin tener que recopilar nuevos datos reales.
5. Anotación: el idioma de sus datos
La anotación de un conjunto de datos es asignar etiquetas a los datos para que la IA los pueda interpretar, una operación que requiere rigor y precisión porque influye directamente en la toma de decisiones del algoritmo, es decir, en la forma en que la IA procesará los datos. Esta tarea puede facilitarse en gran medida mediante el uso de plataformas de anotación dedicadas, como Kili, V7 o Label Studio. Estas herramientas ofrecen interfaces intuitivas y funciones avanzadas para una anotación precisa, lo que contribuye a la eficiencia y precisión de los modelos de aprendizaje automático.
La anotación de datos para la IA generalmente implica un experiencia humana etiquetar los datos con precisión, un paso esencial en los modelos de formación. Cuanto más complejos o específicos sean sus conjuntos de datos o requieran capacitación sobre reglas o mecanismos particulares, mayor será la experiencia humana de Etiquetadoras de datos se hace necesario. Con los avances tecnológicos, las capacidades de anotación se complementan cada vez más con herramientas automatizadas. Estas herramientas utilizan algoritmos para anotar datos previamente, lo que reduce el tiempo y el esfuerzo necesarios para la anotación manual, al tiempo que requiere la verificación y la validación humanas para garantizar la precisión y la relevancia de las etiquetas asignadas. Las últimas actualizaciones de las plataformas de etiquetado del mercado ofrecen funciones avanzadas de selección o revisión automática, lo que hace que la anotación sea cada vez menos laboriosa para los anotadores. Gracias a estas herramientas, el etiquetado de datos se está convirtiendo en una profesión por derecho propio.
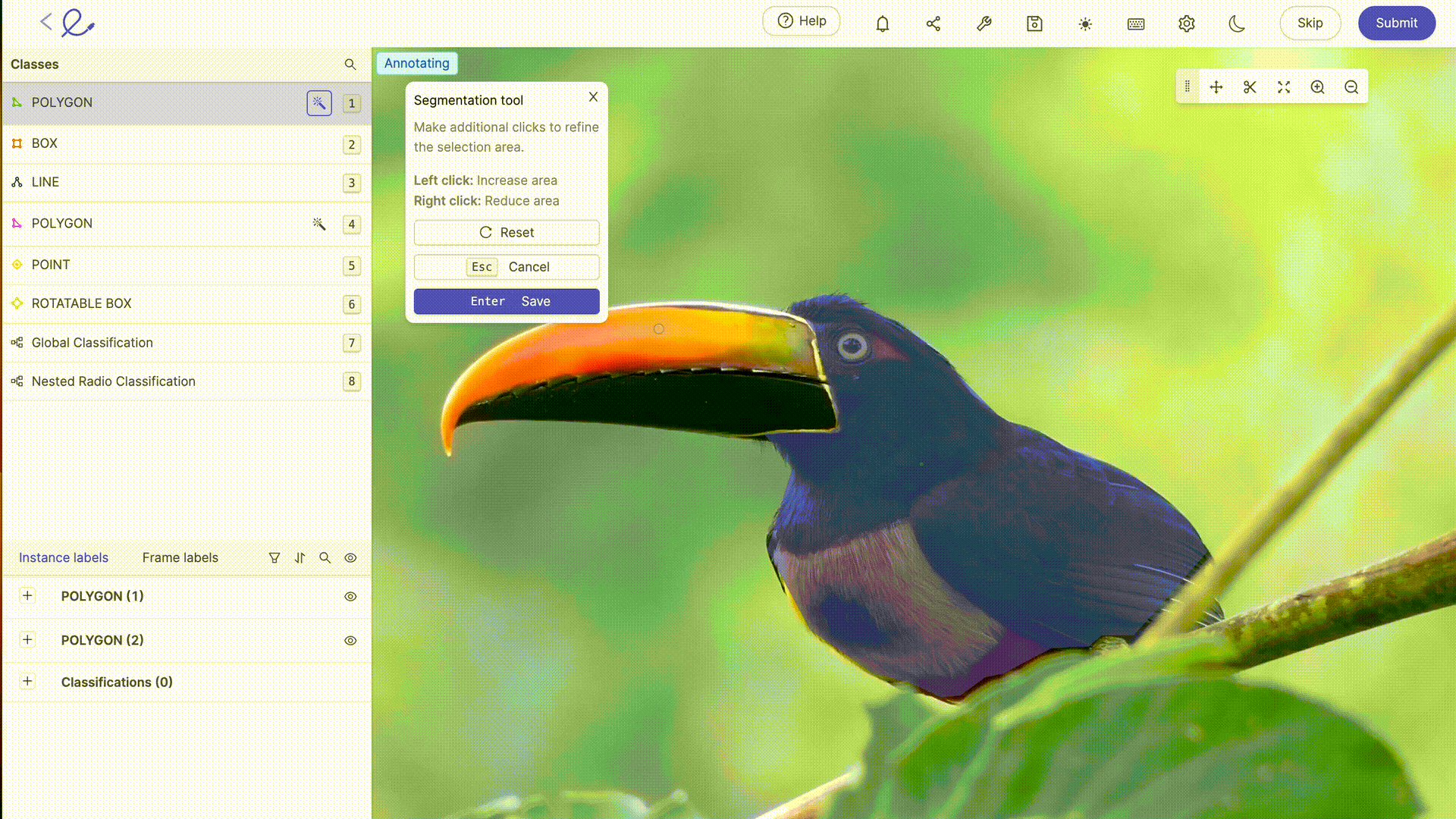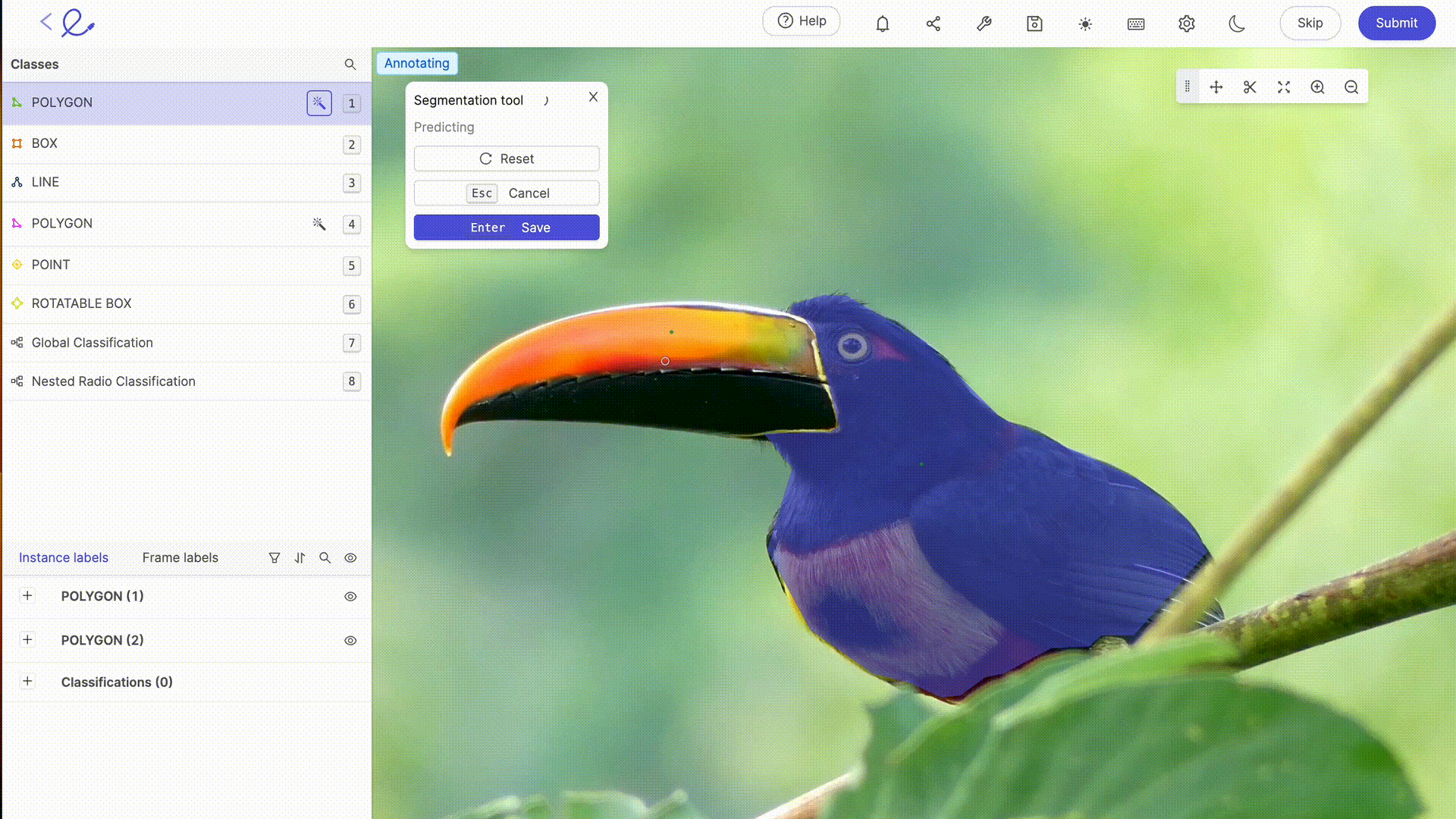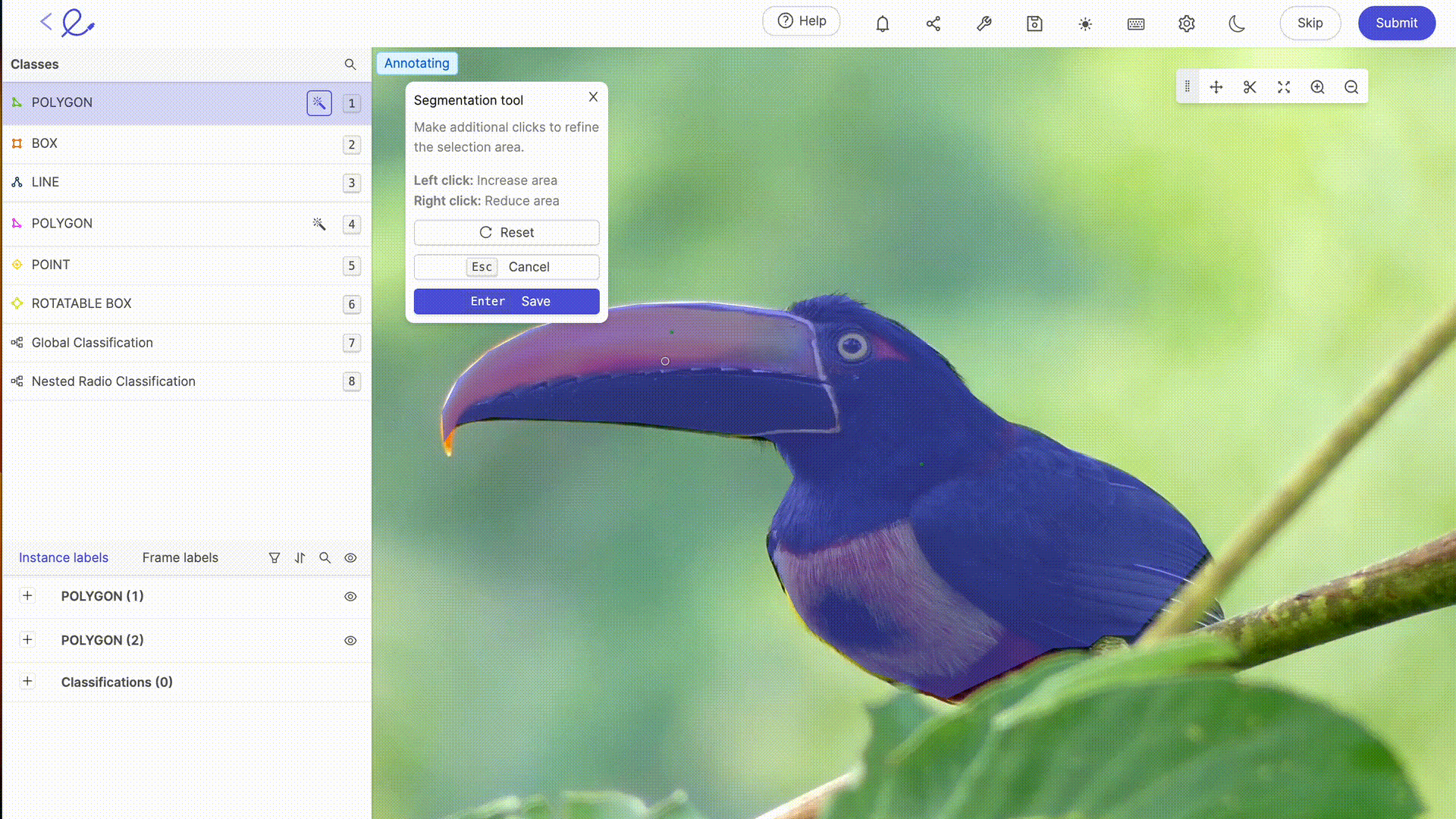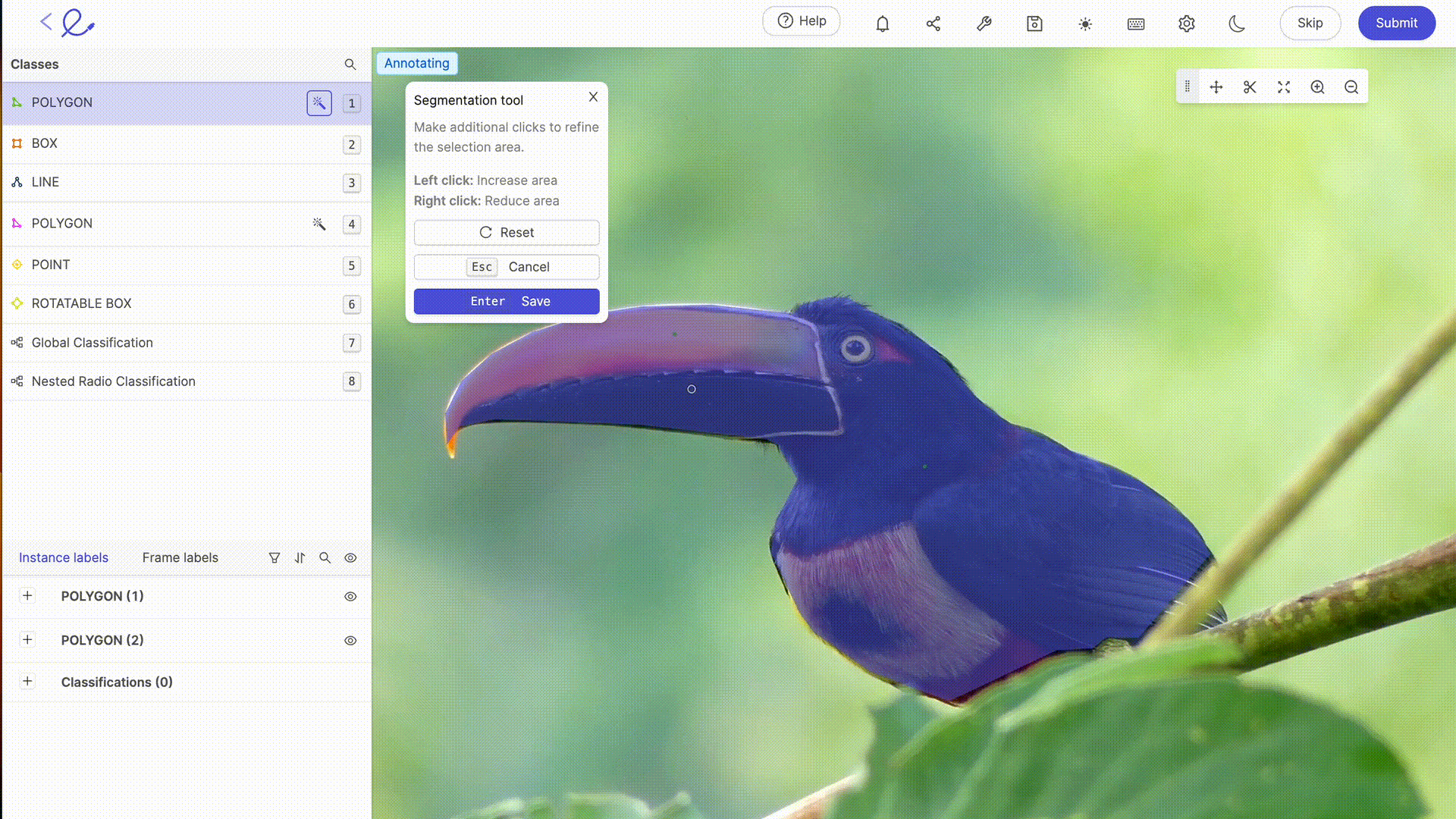
6. Optimización de un conjunto de datos: pruebas e iteraciones
Tras recopilar y anotar una gran cantidad de datos, el siguiente paso lógico es probar el conjunto de datos para evaluar el rendimiento de su modelo de IA. Por lo tanto, se trata deun enfoque iterativo, y tendrá que volver a los pasos anteriores para mejorar la calidad de los datos o las etiquetas producidas.
Para Evaluar la calidad de un conjunto de datos, aquí tienes algunas preguntas que puedes hacerte:
- ¿Los datos son representativos de la población o el fenómeno estudiado?
- ¿La recopilación de datos se realizó de forma ética y legal?
- ¿Los datos son lo suficientemente variados como para cubrir diferentes casos de uso?
- ¿Se vio afectada la calidad de los datos durante el ciclo de recopilación y anotación, por ejemplo, durante el proceso de transferencia o almacenamiento?
- ¿Los datos contienen sesgos o errores que podrían influir en los resultados del modelo?
- ¿Hay dependencias o correlaciones inesperadas entre las variables?
Estas preguntas lo ayudarán a evaluar minuciosamente la calidad de sus datos para garantizar la eficiencia y la confiabilidad de sus modelos de IA.
En conclusión...
Llegamos al final de este artículo. Lo habrás entendido: crear y anotar un conjunto de datos son pasos fundamentales en el desarrollo de soluciones de IA. Si sigue nuestros consejos, esperamos que pueda sentar las bases sólidas necesarias para entrenar modelos de IA eficientes y confiables. Buena suerte con tus experimentos y proyectos, y no olvides: un buen conjunto de datos es la clave del éxito de su proyecto de IA !
Finalmente, pensamos en ti al reunir Una lista de los 10 mejores sitios para encontrar conjuntos de datos de aprendizaje automático. Si esta lista parece incompleta o si necesita datos más específicos, nuestro equipo está a tu disposición para ayudarlo a recopilar y anotar conjuntos de datos personalizados y de alta calidad. No dude en utilizar nuestros servicios para perfeccionar sus proyectos de aprendizaje automático.
Nuestros 10 sitios principales donde encontrar conjuntos de datos para el aprendizaje automático
- Conjunto de datos de Kaggle: 🔗 https://www.kaggle.com/datasets
- Conjuntos de datos de Hugging Face: 🔗 https://huggingface.co/docs/datasets/index
- Conjuntos de datos de Amazon: 🔗 https://registry.opendata.aws
- Buscador de conjuntos de datos de Google: 🔗 https://datasetsearch.research.google.com
- Plataforma para la difusión de datos públicos del Estado francés: 🔗 https://data.gouv.fr
- Portal de datos abiertos de la Unión Europea: 🔗 http://data.europa.eu/euodp
- Conjuntos de datos de la comunidad de Reddit: 🔗 https://www.reddit.com/r/datasets
- Repositorio de aprendizaje automático de la UCI: 🔗 https://archive.ics.uci.edu
- Sitio web del INSEE: 🔗 https://www.insee.fr/fr/information/2410988
(BONUS) - SDSC, plataforma para proporcionar datos anotados para casos de uso médico: 🔗 https://www.surgicalvideo.io/



