Argilla : l'outil ultime pour créer des datasets de qualité pour vos LLM ?

💡 Cet article explore les fonctionnalités et les avantages de cet outil innovant, ainsi que son impact potentiel sur l'amélioration des performances des modèles d'IA.
🤯 BREAKING NEWS (17.09.2024) - Argilla vient de publier "DataCraft", une interface utilisant Distilabel pour créer des datasets synthétiques ! Vous pouvez tester l'outil à cette adresse (https://argilla.io) et si vous souhaitez revoir, enrichir ou compléter votre dataset avec l'aide d'experts, n'hésitez pas à contacter Innovatiana ! UPDATE Juillet 2025 : il semblerait qu'Argilla a arrêté le développement de DataCraft, à notre grand regret !
Qu'est-ce qu'Argilla et quel est son rôle dans l'annotation de données ?
Argilla est une plateforme d’annotation de données conçue pour simplifier et améliorer le processus de création de datasets de haute qualité, essentiels au développement de modèles d’intelligence artificielle (IA).
Elle se distingue par sa capacité à gérer de grandes quantités de données, tout en offrant des outils de collaboration et des fonctionnalités avancées pour personnaliser les annotations selon les besoins spécifiques des projets.
-hand-innv.png)
Comment Argilla se distingue-t-il des autres outils d'annotation de données ?
Interface utilisateur intuitive et personnalisable
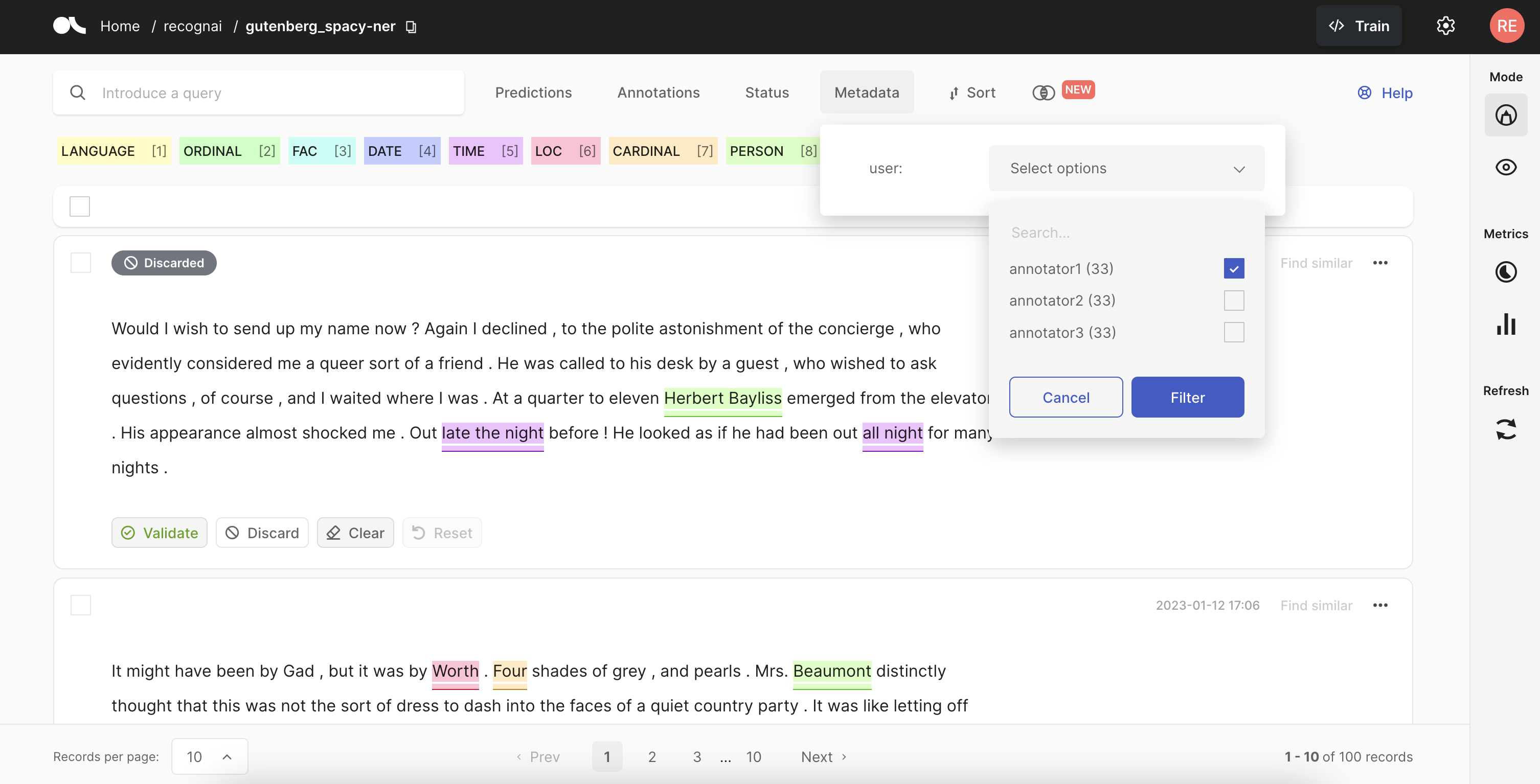
La dernière version d’Argilla se distingue par son interface utilisateur conçue pour être à la fois intuitive et flexible, agissant comme un hub central pour la gestion des annotations. Les nouveautés de l'interface utilisateur d'Argilla incluent des fonctionnalités améliorées pour une meilleure expérience utilisateur. Contrairement à de nombreux autres outils, elle permet une personnalisation poussée des annotations de texte, s’adaptant ainsi parfaitement aux spécificités de chaque projet.
Cette flexibilité est essentielle pour répondre aux besoins variés des projets d’intelligence artificielle, qui peuvent nécessiter des types d’annotations très spécifiques.
Collaboration facilitée pour un travail en équipe efficace
Annotation guidée par le Machine Learning
Argilla innove également par son approche hybride de l'annotation, en combinant l'expertise humaine avec des modèles de Machine Learning. Cette fonctionnalité permet de suggérer des annotations basées sur des modèles pré-entraînés, accélérant ainsi le processus et augmentant la précision des datasets. Cela représente un gain de temps significatif tout en améliorant la qualité des annotations.
Intégration fluide dans un environnement de développement (Python)
Enfin, Argilla se distingue par sa capacité à s'intégrer facilement dans divers environnements de développement, en particulier ceux basés sur la librairie Python. Cette compatibilité permet aux utilisateurs de continuer à travailler dans leurs environnements familiers tout en profitant des avantages d'Argilla pour mettre en place des workflows d'annotation de données puissants.
🪄 Argilla est un outil particulièrement précieux pour les équipes de développement qui cherchent à optimiser leur workflow de création de datasets sans perturber leurs habitudes de travail.
Liste des types de données pouvant être annotés avec Argilla
Argilla est conçu pour être un outil polyvalent, capable de gérer une large gamme de types de données. Voici un aperçu des principaux types de données qui peuvent être annotés avec Argilla :
Texte
Données séquentielles et temporelles
Pour les projets nécessitant l'annotation de données séquentielles ou temporelles, Argilla offre des outils adaptés à l'annotation de séquences de données. Cela inclut des applications comme l'étiquetage de séries temporelles, l'annotation de flux de données sensoriels, ou encore l'analyse de vidéos.
Multimodalité
Argilla est également capable de gérer des datasets multimodaux, où plusieurs types de données (texte, image, audio) sont combinés. Cela permet une annotation cohérente à travers différents types de médias, ce qui est essentiel pour les projets complexes intégrant plusieurs sources de données.
Données structurées
Enfin, Argilla peut être utilisé pour annoter des données structurées, comme des tableaux ou des bases de données. Cela est particulièrement utile pour les projets nécessitant l'étiquetage de caractéristiques spécifiques ou la création de jeux de données à partir de sources de données structurées.
Distilabel : Une extension puissante d'Argilla pour l'amélioration des datasets
Comment Distilabel fonctionne-t-il ?
Distilabel repose sur des algorithmes avancés de distillation de connaissances, où un modèle pré-entraîné ("teacher") est utilisé pour générer des annotations pour des données non étiquetées. Ces annotations sont ensuite revues et validées par des annotateurs humains, créant ainsi un cycle de feedback qui améliore continuellement la qualité des datasets. Cette approche hybride permet non seulement de gagner du temps, mais aussi de réduire les coûts liés à l'annotation manuelle tout en maintenant un haut niveau de précision.
Les avantages de Distilabel pour les projets d'IA
L'un des principaux avantages de Distilabel est sa capacité à traiter des volumes massifs de données non étiquetées, les transformant en ressources précieuses pour l'entraînement des modèles. Cette extension est particulièrement utile pour les projets nécessitant des datasets extrêmement volumineux, comme ceux impliquant des modèles de traitement du langage naturel (NLP) ou de vision par ordinateur. De plus, Distilabel s'intègre parfaitement à Argilla, offrant une interface unifiée pour gérer l'ensemble du processus d'annotation, de la collecte des données à leur étiquetage final.
Comment Argilla améliore-t-il la qualité des datasets pour l'entraînement des modèles d'intelligence artificielle ?
Annotation assistée par l'IA
Argilla intègre des modèles de Machine Learning pour assister les annotateurs en suggérant des annotations basées sur des prédictions automatisées.
Cette approche hybride permet non seulement de gagner du temps, mais aussi d'améliorer la cohérence et la précision des annotations, en réduisant les erreurs humaines. Les suggestions fournies par l'IA sont ensuite validées ou ajustées par des annotateurs humains, garantissant ainsi un équilibre entre automatisation et qualité.
Contrôle de la qualité et validation des annotations
L'un des aspects essentiels d'Argilla est son système de contrôle de la qualité intégré. Les annotations peuvent être revues, validées, ou corrigées par d'autres membres de l'équipe, ce qui permet d'assurer une double vérification des données annotées. Ce processus collaboratif réduit les biais individuels et améliore la fiabilité des données.
Flexibilité et personnalisation des workflows d'annotation
Argilla permet de créer des workflows d'annotation personnalisés, adaptés aux besoins spécifiques de chaque projet. Cette flexibilité garantit que les annotations sont réalisées selon des critères précis, correspondant aux exigences du modèle d'IA à entraîner.
La possibilité de définir des schémas d'annotation en détails aide à standardiser le processus, ce qui est indispensable pour obtenir des datasets homogènes et de haute qualité.
Collaboration facilitée pour une cohérence accrue
Argilla offre des fonctionnalités de collaboration qui permettent à plusieurs annotateurs de travailler simultanément sur le même dataset. Cette approche collaborative renforce la cohérence des annotations, car les annotateurs peuvent partager des retours en temps réel, discuter des cas ambigus, et harmoniser leurs pratiques d'annotation.
La centralisation des annotations dans un environnement partagé aide également à maintenir une qualité élevée sur l'ensemble du dataset.
Analyse et feedback en temps réel
Enfin, Argilla fournit des outils d’analyse en temps réel qui permettent de surveiller la progression de l’annotation et d’identifier rapidement les éventuelles incohérences ou erreurs. Argilla offre des insights précieux sur la qualité des données en cours de création, permettant des ajustements immédiats si nécessaire. L’analyse continue améliore l’efficacité du processus d’annotation et garantit que le dataset final répond aux standards de qualité requis pour l’entraînement des modèles d’IA.
Quels sont les principaux cas d'utilisation d'Argilla dans le développement de modèles IA ?
Argilla est utilisé dans une variété de cas d'utilisation dans le développement de modèles d'intelligence artificielle (IA), en particulier là où l'annotation de données joue un grand rôle dans l'entraînement et l'amélioration des performances des modèles. Voici quelques-uns des principaux cas d'utilisation :
Annotation de séries temporelles
Argilla s'avère utile dans l'annotation de données séquentielles et temporelles, telles que les séries temporelles. Cela inclut des applications dans des domaines comme la finance, où les modèles d'IA doivent analyser des données historiques pour prédire des tendances futures, ou dans la médecine, pour l'analyse de données biométriques.
La possibilité d'annoter et de gérer efficacement des données séquentielles permet de créer des datasets robustes pour ces types de modèles.
Projets multimodaux
Les projets nécessitant l'intégration de plusieurs types de données (texte, image, audio) bénéficient également d'Argilla. Les annotations multimodales sont souvent complexes, et Argilla permet de les gérer de manière cohérente, en assurant que les annotations de différents types de données soient alignées.
Ceci est particulièrement utile dans des applications avancées comme la reconnaissance de contextes ou la création de systèmes interactifs où plusieurs types de médias doivent être traités conjointement.
Création et gestion de bases de connaissances
Argilla est aussi utilisé pour annoter des données structurées, comme des tableaux ou des bases de données, ce qui est essentiel pour des applications comme la création de systèmes de recommandation, la gestion de connaissances, ou l'analyse de données.
Ces annotations aident à structurer l'information de manière utile pour l'entraînement de modèles d'IA qui dépendent de données organisées et interconnectées.
Conclusion
Argilla s'impose comme un outil essentiel dans le domaine de l'intelligence artificielle, en offrant des solutions avancées pour l'annotation de données, un aspect important du développement de modèles performants.
Grâce à sa flexibilité, son intégration fluide dans divers environnements de développement, et ses fonctionnalités innovantes comme l'annotation assistée par IA, Argilla permet aux équipes de créer des datasets de haute qualité de manière plus efficace et collaborative.
Que ce soit pour des projets de traitement du langage naturel ou d'autres applications de Machine Learning, Argilla se distingue par sa capacité à répondre aux besoins complexes des annotateurs et des développeurs.
Au final, l'utilisation d'Argilla ne se limite pas à l'amélioration de la qualité des données, mais elle représente également une avancée significative dans la fiabilité et la précision des modèles d'IA, contribuant ainsi au succès des projets d'intelligence artificielle à grande échelle. Comme quoi... il est encore possible d'innover dans le monde du Data Labeling !



