Apprentissage par "Reinforcement Learning from Human Feedback" (RLHF) : un guide détaillé

L'apprentissage par "Reinforcement Learning from Human Feedback" (ou RLHF) est une technique de Machine Learning (ML) qui utilise le retour d'information humain pour assurer que les modèles de langage de grande taille (LLMs) ou d'autres systèmes IA offrent des réponses semblables à celles formulées par des humains.
L'apprentissage par RLHF joue un rôle révolutionnaire dans la transformation de l'intelligence artificielle. Il est considéré comme la technique standard de l'industrie pour rendre les LLMs plus efficaces et précis dans la façon dont ils imitent les réponses humaines. Le meilleur exemple est ChatGPT. Lorsque l'équipe d'OpenAI développait ChatGPT, elle a appliqué le RLHF au modèle GPT pour rendre ChatGPT capable de répondre comme il le fait aujourd'hui (c'est-à-dire d'une façon quasi-naturelle).
Essentiellement, le RLHF inclut l'apport humain et le retour d'information dans le modèle d'apprentissage par renforcement. Cela aide à améliorer l'efficacité des applications IA et les aligne sur les attentes humaines.
En considérant l'importance et l'utilité du RLHF pour développer des modèles complexes, la communauté de chercheurs et de développeurs IA ont beaucoup investi dans ce concept. Nous avons tenté dans cet atticle de vulgariser son principe, en couvrant tout ce que vous devez savoir sur l'apprentissage par "Reinforcement Learning from Human Feedback" (RLHF), y compris son concept de base, son principe de fonctionnement, ses avantages et bien plus encore. S'il faut retenir une chose, c'est que ce processus implique la mobilisation de modérateurs / évaluateur dans le cycle de développement IA. Innovatiana propose ces services d'évaluation IA : n'hésitez pas à nous solliciter !
En IA, qu'est-ce que l'apprentissage par "Reinforcement Learning from Human Feedback" (RLHF) ?
L'apprentissage par "Reinforcement Learning from Human Feedback" (RLHF) est une technique d'apprentissage machine (ML) qui implique le retour d'information humain pour aider les modèles ML à auto-apprendre plus efficacement. Les techniques d'apprentissage par renforcement (RL) permettent d'entraîner des logiciels/modèles à prendre des décisions qui maximisent les récompenses. Cela conduit à des résultats plus précis.
Le RLHF implique d'incorporer le retour d'information humain dans la fonction de récompense, ce qui amène le modèle ML à effectuer des tâches qui correspondent aux besoins et objectifs humains. Il donne au modèle le pouvoir d'interpréter correctement les instructions humaines, même si elles ne sont pas clairement décrites. En outre, il aide également le modèle existant à améliorer sa capacité à générer un langage naturel.
Aujourd'hui, le RLHF est notamment déployé dans toutes les applications d'intelligence artificielle générative, en particulier dans les modèles de langage de grande taille (LLMs).
Le concept fondamental derrière le RLHF
Pour mieux comprendre le RLHF, il est important de comprendre d'abord l'apprentissage par renforcement (RL) puis le rôle du feedback humain dans celui-ci.
L'apprentissage par renforcement (RL) est une technique de ML dans laquelle l'agent/modèle interagit avec son environnement pour apprendre à prendre des décisions. Pour ce faire, il effectue des actions qui impactent son environnement, le fait passer à un nouvel état et renvoie une récompense. La récompense qu'il reçoit est comme un retour d'information, qui améliore la prise de décision de l'agent. Ce processus de retour d'information se poursuit encore et encore pour améliorer la prise de décision de l'agent. Cependant, il est difficile de concevoir un système de récompense efficace. C'est là que l'interaction humaine et le retour d'information entrent en jeu.
Le retour d'information humain aborde les lacunes du système de récompense en impliquant un signal de récompense humain à travers un superviseur humain. De cette façon, la prise de décision de l'agent devient plus efficace. La plupart des systèmes RLHF impliquent à la fois la collecte de retours d'information humains et de signaux de récompense automatisés pour un entraînement plus rapide.
RLHF et son rôle dans les modèles de langage de grande taille (LLMs)
Pour le grand public, y compris pour les spécialistes hors communauté des chercheurs en IA, lorsque nous entendons parler de RLHF, il est principalement lié aux modèles de langage de grande taille (LLMs). Comme mentionné précédemment, le RLHF est la technique standard de l'industrie pour rendre les LLMs plus efficaces et précis dans l'imitation des réponses humaines.
Les LLMS sont conçus pour prédire le mot/token suivant d'une phrase. Par exemple, si vous entrez le début d'un phrase dans un modèle de langage GPT maintenant, il le complétera en ajoutant des locutions logiques (ou parfois hallucinées voire biaisées - mais c'est un autre débat).
Cependant, les humains ne veulent pas seulement que le LLM complète des phrases. Ils veulent qu'il comprenne leurs requêtes complexes et y réponde en conséquence. Par exemple, supposez que vous demandiez au LLM d' "écrire un article de 500 mots sur la cybersécurité". Dans ce cas, il peut interpréter les instructions de manière incorrecte et répondre en vous disant comment écrire un article sur la cybersécurité au lieu d'écrire un article pour vous. Cela se produit principalement en raison d'un système de récompense inefficace. C'est exactement ce que le RLHF implique pour les LLMs. Vous suivez ?
Le RLHF améliore les capacités des LLMs en incorporant un système de récompense avec retour d'information humain. Cela enseigne au modèle à prendre en compte les conseils humains et à répondre de manière à s'aligner au mieux sur les attentes humaines. En bref, le RLHF est la clé pour que les LLMs fassent des réponses semblables à celles des humains. Cela pourrait aussi, d'une certaine façon, expliquer qu'un modèle comme ChatGPT soit plus attentif aux questions formulées de façon courtoise (comme dans la vie, un "s'il vous plaît" dans une question a plus de chance d'obtenir une réponse de qualité !).
-hand-innv.png)
Pourquoi le RLHF est-il important ?
L'industrie de l'intelligence artificielle (IA) est en plein essor aujourd'hui avec l'émergence d'une large gamme d'applications, y compris le traitement du langage naturel (NLP), les voitures autonomes, les prédictions du marché boursier, etc. Cependant, l'objectif principal de presque toutes les applications IA est de reproduire les réponses humaines ou de prendre des décisions semblables à celles des humains.
Le RLHF joue un rôle majeur dans l'entraînement des modèles/applications IA pour répondre de manière plus humaine. Dans le processus de développement RLHF, le modèle donne d'abord une réponse qui ressemble un peu à celle qui pourrait être formulée par un humain. Ensuite, un superviseur humain (comme notre équipe de modérateurs chez Innovatiana) donne un retour direct et une note à la réponse en fonction de différents aspects impliquant des valeurs humaines, comme l'humeur, la convivialité, les sentiments associés à un texte ou une image, etc. Par exemple, un modèle traduit un texte qui semble correct techniquement, mais il peut sembler peu naturel au lecteur. C'est ce que le feedback humain peut détecter. De cette façon, le modèle continue d'apprendre des réponses humaines et améliore ses résultats pour correspondre aux attentes humaines.
Si vous utilisez ChatGPT régulièrement, vous aurez sans doute noté que celui-ci propose des options et vous demande parfois de choisir la meilleure réponse. Vous avez participé, sans le savoir, à son processus d'entraînement, en tant que superviseur !
L'importance du RLHF est évidente en ce qui concerner les aspects suivants :
- Rendre l'IA plus précise : Il améliore la précision des modèles en incorporant une boucle de retour d'information humain supplémentaire.
- Faciliter les paramètres d'entraînement complexes : RLHF aide dans l'entraînement de modèles avec des paramètres complexes, comme deviner le sentiment associé à une musique ou un texte (tristesse, joie, état d'esprit particulier, etc.).
- Satisfaire les utilisateurs : Il fait en sorte que les modèles répondent de manière plus humaine, ce qui augmente la satisfaction des utilisateurs.
En bref, le RLHF est un outil du cycle de développement IA pour optimiser la performance des modèles ML et les rendre capables d'imiter les réponses et la prise de décision humaines.
Processus d'entraînement RLHF étape par étape
L'apprentissage par renforcement avec retour d'information humain ou "Reinforcement Learning from Human Feedback" (RLHF) étend l'apprentissage auto-supervisé que les modèles de langage de grande taille subissent dans le cadre du processus d'entraînement. Cependant, le RLHF n'est pas un modèle d'apprentissage auto-suffisant, car l'utilisation de testeurs et de formateurs humains rend l'ensemble du processus coûteux. Par conséquent, la plupart des entreprises utilisent le RLHF pour fine-tuner un modèle pré-entraîné, c'est-à-dire compléter un cycle de développement IA automatisé avec une intervention humaine.
Le processus de développement/entraînement RLHF étape par étape est le suivant :
Étape 1. Pré-entraînement d'un modèle de langage
La première étape est le pré-entraînement du modèle de langage (comme BERT, GPT ou LLaMA pour n'en citer que quelques-uns) en utilisant une grande quantité de données textuelles. Ce processus de formation permet au modèle de langage de comprendre les différentes nuances de la langue humaine, comme la sémantique ou la syntaxe, et bien sûr la langue.

Les principales activités impliquées dans cette étape sont les suivantes :
1. Choisir un modèle de langage de base pour le processus RLHF. Par exemple, OpenAI utilise une version légère de GPT-3 pour son modèle RLHF.
2. Rassembler les données brutes d'Internet et d'autres sources et les prétraiter pour les rendre adaptées à la formation.
3. Entraîner le modèle de langage avec les données.
4. Évaluer le modèle de langage après entraînement en utilisant un ensemble de données différent.
Pour que le LM acquière plus de connaissances sur les préférences humaines, des humains sont impliqués dans la génération de réponses aux invites ou questions. Ces réponses sont également utilisées pour entraîner le modèle de récompense.
Étape 2. Entraînement d'un modèle de récompense
Un modèle de récompense est un modèle de langage qui envoie un signal de classement au modèle de langage original. Fondamentalement, il sert d'outil d'alignement qui intègre les préférences humaines dans le processus d'apprentissage de l'IA. Par exemple, un modèle IA génère deux réponses à la même question, donc le modèle de récompense indiquera quelle réponse est plus proche des préférences humaines.

Les principales activités impliquées dans la formation du modèle de récompense sont les suivantes :
- Établir le modèle de récompense, qui peut être un système modulaire ou un modèle de langage de bout en bout.
- Entraîner le modèle de récompense avec un ensemble de données différent de celui utilisé lors du pré-entraînement du modèle de langage. L'ensemble de données est composé de paires d'invite et de récompense, c'est-à-dire que chaque invite reflète une sortie attendue avec des récompenses associées pour présenter le caractère souhaitable de la sortie.
- Entraîner le modèle en utilisant des invites (ou "prompts") et des paires de récompense pour associer des sorties spécifiques à des valeurs de récompense correspondantes.
- Intégrer le retour d'information humain dans l'entraînement du modèle de récompense pour affiner le modèle. Par exemple, ChatGPT intègre le retour d'information humain en demandant aux utilisateurs de classer la réponse en cliquant sur le pouce vers le bas ou le pouce vers le haut
Étape 3. Fine-tuning du modèle de langage ou LM avec l'apprentissage par renforcement
La dernière étape, et la plus critique, est le fine-tuning du modèle de compréhension du langage naturel avec l'apprentissage par renforcement. Cet affinage est essentiel pour garantir que le modèle de langage fournit des réponses fiables aux invites des utilisateurs. Pour cela, les spécialistes IA utilisent différentes techniques d'apprentissage par renforcement, telles que l'Optimisation de la Politique Proximale (PPO) et la Divergence de Kullback-Leibler (KL).
Les principales activités impliquées dans l'affinage du LM sont les suivantes :
1. L'entrée de l'utilisateur est envoyée à la politique RL (la version ajustée du LM). La politique RL génère la réponse. La réponse de la politique RL et la sortie initiale du LM sont ensuite évaluées par le modèle de récompense, qui fournit une valeur de récompense scalaire en fonction de la qualité des réponses.
2. Le processus ci-dessus continue dans une boucle de retour d'information, de sorte que le modèle de récompense continue d'attribuer des récompenses à autant d'échantillons que possible. De cette façon, la politique RL commencera progressivement à générer des réponses dans un style proche de celui des humains.
3. La Divergence KL est une méthode statistique pour évaluer la différence entre deux distributions de probabilité. Elle est utilisée pour comparer la distribution de probabilité parmi les réponses actuelles de la politique RL avec la distribution de référence qui reflète les meilleures réponses de style humain.
4. L'Optimisation de la Politique Proximale (PPO) est un algorithme d'apprentissage par renforcement qui optimise efficacement les politiques dans des environnements complexes impliquant des espaces d'état/action de haute dimension. Il est très utile pour affiner le LM car il équilibre l'exploitation et l'exploration pendant l'entraînement. Étant donné que les agents RLHF doivent apprendre à partir du retour d'information humain et de l'exploration par essai et erreur, cet équilibre est vital. De cette façon, le PPO aide à atteindre un apprentissage robuste et plus rapide.
C'est tout, et c'est déjà pas mal ! C'est comme cela que se déroule un processus d'entraînement complet de RLHF, commençant par un processus de pré-entraînement et se terminant par un agent IA avec un fine-tuning approfondi.
Comment le RLHF est-il utilisé dans ChatGPT ?
Maintenant que nous savons comment fonctionne un RLHF, prenons un exemple concret :discutons de la façon dont le RLHF est embarqué dans le processus d'entraînement de ChatGPT - le chatbot IA le plus populaire au monde.
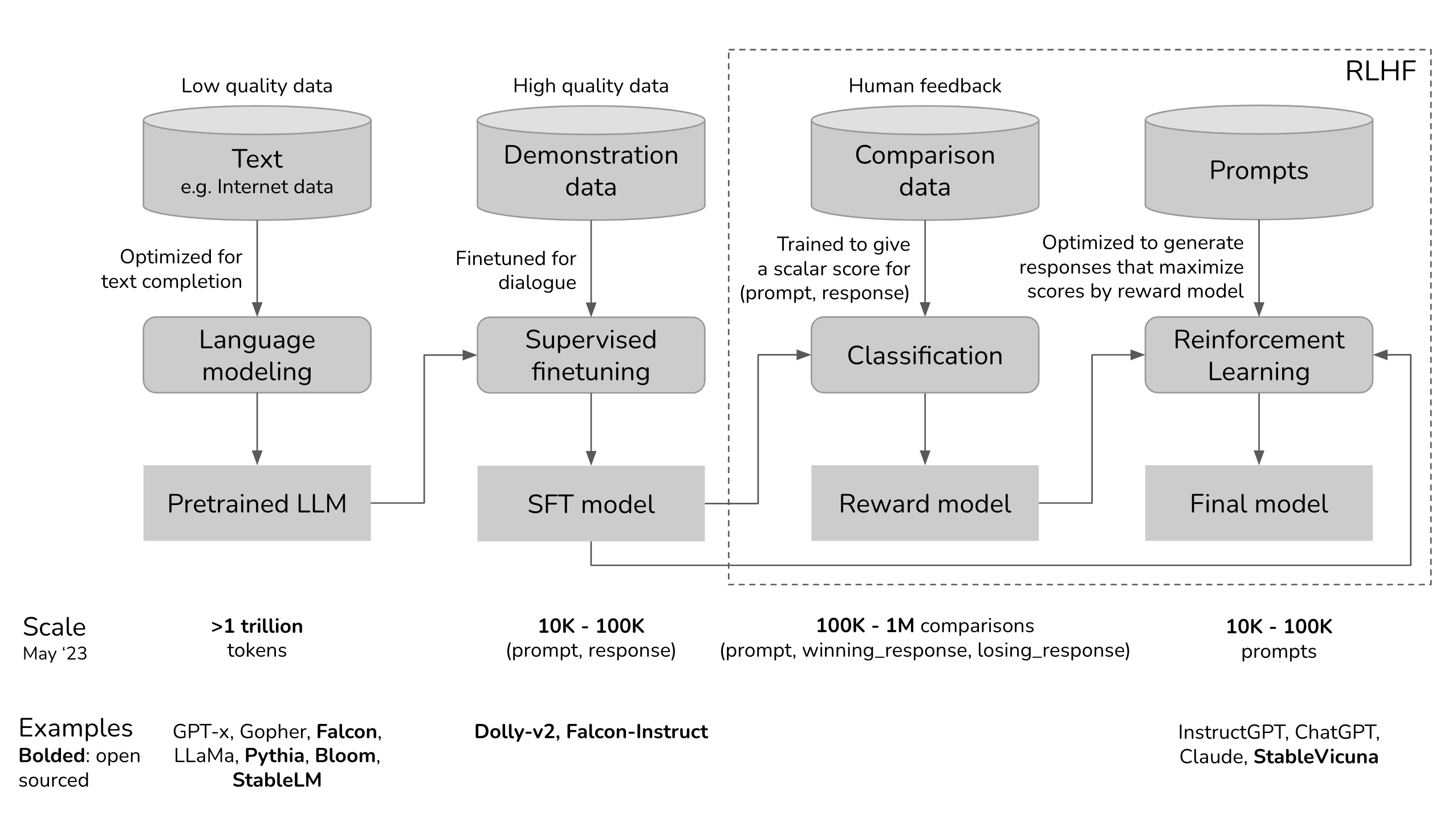
ChatGPT utilise le cadre RLHF pour entraîner le modèle de langage afin de fournir des réponses appropriées à un contexte et semblables à celles des humains. Les trois principales étapes incluses dans son processus d'entraînement sont les suivantes :
1. Fine-tuning du modèle de langage
Le processus commence par l'utilisation de données d'apprentissage supervisé pour affiner le modèle de langage initial. Cela nécessite de construire un ensemble de données de conversations où les formateurs IA jouent à la fois les rôles d'assistant IA et d'utilisateur. En d'autres termes, les formateurs IA utilisent des suggestions écrites par le modèle pour écrire leurs réponses. De cette façon, l'ensemble de données est construit avec un mélange de texte écrit par le modèle et généré par l'humain, ce qui signifie une collection de diverses réponses du modèle.
2. Création d'un modèle de récompense
Après avoir affiné le modèle initial, le modèle de récompense entre en jeu. Dans cette étape, le modèle de récompense est créé pour refléter les attentes humaines. Pour cela, des annotateurs humains classent les réponses générées par le modèle selon la préférence humaine, leur qualité et d'autres facteurs.
Les classements sont utilisés pour former le deuxième modèle d'apprentissage machine, appelé modèle de récompense. Ce modèle est capable de prédire dans quelle mesure la fonction de récompense d'une réponse est alignée sur les préférences humaines.
3. Amélioration du Modèle avec l'Apprentissage par Renforcement
Une fois que le modèle de récompense est prêt, la dernière étape consiste à améliorer les sorties principales du modèle de langage et du modèle grâce à l'apprentissage par renforcement. Ici, l'Optimisation de la Politique Proximale (PPO) aide le LLM à générer des réponses qui obtiennent des scores plus élevés selon le modèle de récompense.
Les trois étapes ci-dessus sont itératives, ce qui signifie qu'elles se produisent en boucle pour améliorer les performances et la précision de l'ensemble du modèle.
Quels sont les défis de l'utilisation du RLHF dans ChatGPT ?
Bien que le RLHF dans ChatGPT ait amélioré l'efficacité des réponses de manière significative, il présente certains défis, comme suit :
- Aborder les différentes préférences humaines. Chaque humain a des préférences différentes. Ainsi, il est difficile de définir un modèle de récompense qui réponde à tous les types de préférences.
- Le travail humain pour la modération type "Human Feedback". La dépendance au travail humain pour optimiser les réponses est coûteuse et lente (et parfois peu éthique).
- L'utilisation du langage de façon cohérente. Une attention particulière est requise pour garantir la cohérence du langage(anglais, français, espagnol, malgache, etc.) tout en améliorant les réponses.
Avantages du RLHF
De toutes les discussions jusqu'à présent, il est évident que le RLHF joue un rôle de premier plan dans l'optimisation des applications IA. Certains des principaux avantages qu'il offre sont les suivants :
- Adaptabilité : Le RLHF offre une stratégie d'apprentissage dynamique, qui s'adapte en fonction des retours d'information. Cela l'aide à adapter son comportement en fonction des retours d'information/interactions en temps réel et à bien s'adapter à une large gamme de tâches.
- Amélioration continue : Les modèles basés sur le RLHF sont capables de s'améliorer continuellement en fonction des interactions des utilisateurs et de plus de retours d'information. De cette façon, ils continueront à améliorer leurs performances avec le temps.
- Réduction des biais du modèle : Le RLHF réduit les biais du modèle en impliquant le retour d'information humain, ce qui minimise les préoccupations de biais ou de généralisation excessive du modèle.
- Sécurité renforcée : Le RLHF rend les applications IA sûres, car la boucle de retour d'information humain interdit aux systèmes IA de déclencher un comportement inapproprié.
En résumé, le RLHF est la clé pour optimiser les systèmes IA et les faire fonctionner d'une manière qui s'aligne sur les valeurs et les intentions humaines.
Défis et Limites du RLHF
L'engouement autour du RLHF vient également avec un ensemble de défis et de limites. Certains des principaux défis/limites du RLHF sont les suivants :
- Biais humain : Il y a des chances que le modèle RLHF puisse faire face au biais humain, car les évaluateurs humains peuvent influencer involontairement leurs biais dans les réponses.
- Scalabilité : Étant donné que le RLHF dépend fortement du retour d'information humain, il est difficile de mettre à l'échelle le modèle pour des tâches plus importantes en raison de la demande extensive de temps et de ressources.
- Dépendance au facteur humain : L'exactitude du modèle RLHF est influencée par le facteur humain. Ainsi, des réponses humaines inefficaces, en particulier dans les requêtes avancées, peuvent compromettre la performance du modèle.
- Formulation de la uestion : La qualité de la réponse du modèle dépend principalement de la formulation de la question. Si la formulation de la question est peu claire, le modèle peut encore ne pas être capable de répondre de manière appropriée malgré des limites RLHF étendues.
Conclusion – Quel est l'avenir du RLHF ?
Sans aucun doute, le "Reinforcement Learning from Human Feedback" (RLHF) promet un avenir brillant et est prêt à continuer à jouer un rôle majeur dans l'industrie de l'IA. Avec l'objectif principal d'avoir une IA qui imite les comportements et mécanismes humains, le RLHF continuera à améliorer cet aspect grâce à des techniques nouvelles/avancées. De plus, il y aura un accent croissant sur la résolution de ses limitations et la garantie d'un équilibre entre les capacités de l'IA et les préoccupations éthiques. Chez Innovatiana, nous espérons contribuer aux processus de développement impliquant le RLHF : nos modérateurs sont spécialisés, habitués des outils et à même de vous accompagner dans vos tâches d'évaluation IA les plus complexes.



